 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem 1&2 Synergy via Dynamic Model Interpolation
Jan 29, 2026Training a unified language model that adapts between intuitive System 1 and deliberative System 2 remains challenging due to interference between their cognitive modes. Recent studies have thus pursued making System 2 models more efficient. However, these approaches focused on output control, limiting what models produce. We argue that this paradigm is misaligned: output length is merely a symptom of the model's cognitive configuration, not the root cause. In this work, we shift the focus to capability control, which modulates \textit{how models think} rather than \textit{what they produce}. To realize this, we leverage existing Instruct and Thinking checkpoints through dynamic parameter interpolation, without additional training. Our pilot study establishes that linear interpolation yields a convex, monotonic Pareto frontier, underpinned by representation continuity and structural connectivity. Building on this, we propose \textbf{DAMI} (\textbf{D}yn\textbf{A}mic \textbf{M}odel \textbf{I}nterpolation), a framework that estimates a query-specific Reasoning Intensity $λ(q)$ to configure cognitive depth. For training-based estimation, we develop a preference learning method encoding accuracy and efficiency criteria. For zero-shot deployment, we introduce a confidence-based method leveraging inter-model cognitive discrepancy. Experiments on five mathematical reasoning benchmarks demonstrate that DAMI achieves higher accuracy than the Thinking model while remaining efficient, effectively combining the efficiency of System 1 with the reasoning depth of System 2.
A Symbolic Adversarial Learning Framework for Evolving Fake News Generation and Detection
Aug 27, 2025Rapid LLM advancements heighten fake news risks by enabling the automatic generation of increasingly sophisticated misinformation. Previous detection methods, including fine-tuned small models or LLM-based detectors, often struggle with its dynamically evolving nature. In this work, we propose a novel framework called the Symbolic Adversarial Learning Framework (SALF), which implements an adversarial training paradigm by an agent symbolic learning optimization process, rather than relying on numerical updates. SALF introduces a paradigm where the generation agent crafts deceptive narratives, and the detection agent uses structured debates to identify logical and factual flaws for detection, and they iteratively refine themselves through such adversarial interactions. Unlike traditional neural updates, we represent agents using agent symbolic learning, where learnable weights are defined by agent prompts, and simulate back-propagation and gradient descent by operating on natural language representations of weights, loss, and gradients. Experiments on two multilingual benchmark datasets demonstrate SALF's effectiveness, showing it generates sophisticated fake news that degrades state-of-the-art detection performance by up to 53.4% in Chinese and 34.2% in English on average. SALF also refines detectors, improving detection of refined content by up to 7.7%. We hope our work inspires further exploration into more robust, adaptable fake news detection systems.
On the Privacy Risks of Spiking Neural Networks: A Membership Inference Analysis
Feb 18, 2025Spiking Neural Networks (SNNs) are increasingly explored for their energy efficiency and robustness in real-world applications, yet their privacy risks remain largely unexamined. In this work, we investigate the susceptibility of SNNs to Membership Inference Attacks (MIAs) -- a major privacy threat where an adversary attempts to determine whether a given sample was part of the training dataset. While prior work suggests that SNNs may offer inherent robustness due to their discrete, event-driven nature, we find that its resilience diminishes as latency (T) increases. Furthermore, we introduce an input dropout strategy under black box setting, that significantly enhances membership inference in SNNs. Our findings challenge the assumption that SNNs are inherently more secure, and even though they are expected to be better, our results reveal that SNNs exhibit privacy vulnerabilities that are equally comparable to Artificial Neural Networks (ANNs). Our code is available at https://anonymous.4open.science/r/MIA_SNN-3610.
A Factuality and Diversity Reconciled Decoding Method for Knowledge-Grounded Dialogue Generation
Jul 08, 2024Grounding external knowledge can enhance the factuality of responses in dialogue generation. However, excessive emphasis on it might result in the lack of engaging and diverse expressions. Through the introduction of randomness in sampling, current approaches can increase the diversity. Nevertheless, such sampling method could undermine the factuality in dialogue generation. In this study, to discover a solution for advancing creativity without relying on questionable randomness and to subtly reconcile the factuality and diversity within the source-grounded paradigm, a novel method named DoGe is proposed. DoGe can dynamically alternate between the utilization of internal parameter knowledge and external source knowledge based on the model's factual confidence. Extensive experiments on three widely-used datasets show that DoGe can not only enhance response diversity but also maintain factuality, and it significantly surpasses other various decoding strategy baselines.
Multi-level Adaptive Contrastive Learning for Knowledge Internalization in Dialogue Generation
Oct 17, 2023Knowledge-grounded dialogue generation aims to mitigate the issue of text degeneration by incorporating external knowledge to supplement the context. However, the model often fails to internalize this information into responses in a human-like manner. Instead, it simply inserts segments of the provided knowledge into generic responses. As a result, the generated responses tend to be tedious, incoherent, and in lack of interactivity which means the degeneration problem is still unsolved. In this work, we first find that such copying-style degeneration is primarily due to the weak likelihood objective, which allows the model to "cheat" the objective by merely duplicating knowledge segments in a superficial pattern matching based on overlap. To overcome this challenge, we then propose a Multi-level Adaptive Contrastive Learning (MACL) framework that dynamically samples negative examples and subsequently penalizes degeneration behaviors at both the token-level and sequence-level. Extensive experiments on the WoW dataset demonstrate the effectiveness of our approach across various pre-trained models.
FedNAR: Federated Optimization with Normalized Annealing Regularization
Oct 04, 2023
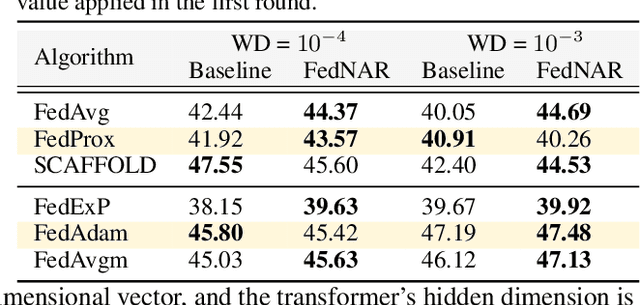
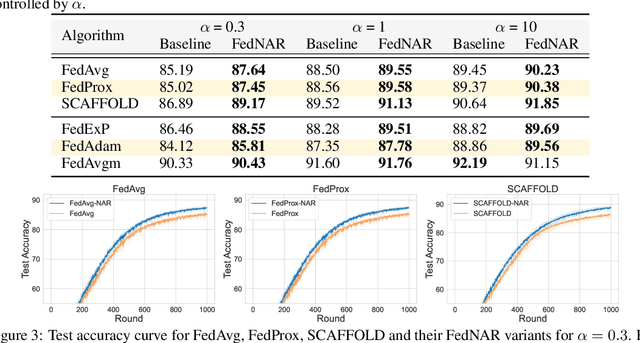

Weight decay is a standard technique to improve generalization performance in modern deep neural network optimization, and is also widely adopted in federated learning (FL) to prevent overfitting in local clients. In this paper, we first explore the choices of weight decay and identify that weight decay value appreciably influences the convergence of existing FL algorithms. While preventing overfitting is crucial, weight decay can introduce a different optimization goal towards the global objective, which is further amplified in FL due to multiple local updates and heterogeneous data distribution. To address this challenge, we develop {\it Federated optimization with Normalized Annealing Regularization} (FedNAR), a simple yet effective and versatile algorithmic plug-in that can be seamlessly integrated into any existing FL algorithms. Essentially, we regulate the magnitude of each update by performing co-clipping of the gradient and weight decay. We provide a comprehensive theoretical analysis of FedNAR's convergence rate and conduct extensive experiments on both vision and language datasets with different backbone federated optimization algorithms. Our experimental results consistently demonstrate that incorporating FedNAR into existing FL algorithms leads to accelerated convergence and heightened model accuracy. Moreover, FedNAR exhibits resilience in the face of various hyperparameter configurations. Specifically, FedNAR has the ability to self-adjust the weight decay when the initial specification is not optimal, while the accuracy of traditional FL algorithms would markedly decline. Our codes are released at \href{https://github.com/ljb121002/fednar}{https://github.com/ljb121002/fednar}.