 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiao: Bridging Isolation and Customization in Mixed Criticality Robotics
May 05, 2026Consumer robotics demands consolidation of safety-critical control, perception pipelines, and user applications on shared multicore platforms. While static partitioning hypervisors provide hardware-enforced isolation, directly transplanting automotive architectures encounters an expertise asymmetry problem in which end-users modifying robot behavior lack the systems knowledge that platform developers possess. We present an architecture addressing this challenge through three integrated components. A Safe IO Cell provides hardware-level override capability. A Parameter Synchronization Service encapsulates cross-domain complexity. A Safety Communication Layer implements IEC~61508-aligned verification. Our empirical evaluation on an ARM Cortex-A55 platform demonstrates that partition isolation reduces cycle-period jitter by 84.5\% and cuts tail timing error by nearly an order of magnitude (p99 $|$jitter$|$ from 69.0\,$μ$s to 7.8\,$μ$s), eliminating all $>$50\,$μ$s~excursions.
DIVA-GRPO: Enhancing Multimodal Reasoning through Difficulty-Adaptive Variant Advantage
Mar 01, 2026Reinforcement learning (RL) with group relative policy optimization (GRPO) has become a widely adopted approach for enhancing the reasoning capabilities of multimodal large language models (MLLMs). While GRPO enables long-chain reasoning without a critic, it often suffers from sparse rewards on difficult problems and advantage vanishing when group-level rewards are too consistent for overly easy or hard problems. Existing solutions (sample expansion, selective utilization, and indirect reward design) often fail to maintain enough variance in within-group reward distributions to yield clear optimization signals. To address this, we propose DIVA-GRPO, a difficulty-adaptive variant advantage method that adjusts variant difficulty distributions from a global perspective. DIVA-GRPO dynamically assesses problem difficulty, samples variants with appropriate difficulty levels, and calculates advantages across local and global groups using difficulty-weighted and normalized scaling. This alleviates reward sparsity and advantage vanishing while improving training stability. Extensive experiments on six reasoning benchmarks demonstrate that DIVA-GRPO outperforms existing approaches in training efficiency and reasoning performance. Code: https://github.com/Siaaaaaa1/DIVA-GRPO
D-Models and E-Models: Diversity-Stability Trade-offs in the Sampling Behavior of Large Language Models
Jan 25, 2026The predictive probability of the next token (P_token) in large language models (LLMs) is inextricably linked to the probability of relevance for the next piece of information, the purchase probability of the next product, and the execution probability of the next action-all of which fall under the scope of the task-level target distribution (P_task). While LLMs are known to generate samples that approximate real-world distributions, whether their fine-grained sampling probabilities faithfully align with task requirements remains an open question. Through controlled distribution-sampling simulations, we uncover a striking dichotomy in LLM behavior, distinguishing two model types: D-models (e.g. Qwen-2.5), whose P_token exhibits large step-to-step variability and poor alignment with P_task; and E-models (e.g. Mistral-Small), whose P_token is more stable and better aligned with P_task. We further evaluate these two model types in downstream tasks such as code generation and recommendation, revealing systematic trade-offs between diversity and stability that shape task outcomes. Finally, we analyze the internal properties of both model families to probe their underlying mechanisms. These findings offer foundational insights into the probabilistic sampling behavior of LLMs and provide practical guidance on when to favor D- versus E-models. For web-scale applications, including recommendation, search, and conversational agents, our results inform model selection and configuration to balance diversity with reliability under real-world uncertainty, providing a better level of interpretation.
Projecting Out the Malice: A Global Subspace Approach to LLM Detoxification
Jan 09, 2026Large language models (LLMs) exhibit exceptional performance but pose inherent risks of generating toxic content, restricting their safe deployment. While traditional methods (e.g., alignment) adjust output preferences, they fail to eliminate underlying toxic regions in parameters, leaving models vulnerable to adversarial attacks. Prior mechanistic studies characterize toxic regions as "toxic vectors" or "layer-wise subspaces", yet our analysis identifies critical limitations: i) Removed toxic vectors can be reconstructed via linear combinations of non-toxic vectors, demanding targeting of entire toxic subspace; ii) Contrastive objective over limited samples inject noise into layer-wise subspaces, hindering stable extraction. These highlight the challenge of identifying robust toxic subspace and removing them. Therefore, we propose GLOSS (GLobal tOxic Subspace Suppression), a lightweight method that mitigates toxicity by identifying and eliminating this global subspace from FFN parameters. Experiments on LLMs (e.g., Qwen3) show GLOSS achieves SOTA detoxification while preserving general capabilities without requiring large-scale retraining. WARNING: This paper contains context which is toxic in nature.
Circular Reasoning: Understanding Self-Reinforcing Loops in Large Reasoning Models
Jan 09, 2026Despite the success of test-time scaling, Large Reasoning Models (LRMs) frequently encounter repetitive loops that lead to computational waste and inference failure. In this paper, we identify a distinct failure mode termed Circular Reasoning. Unlike traditional model degeneration, this phenomenon manifests as a self-reinforcing trap where generated content acts as a logical premise for its own recurrence, compelling the reiteration of preceding text. To systematically analyze this phenomenon, we introduce LoopBench, a dataset designed to capture two distinct loop typologies: numerical loops and statement loops. Mechanistically, we characterize circular reasoning as a state collapse exhibiting distinct boundaries, where semantic repetition precedes textual repetition. We reveal that reasoning impasses trigger the loop onset, which subsequently persists as an inescapable cycle driven by a self-reinforcing V-shaped attention mechanism. Guided by these findings, we employ the Cumulative Sum (CUSUM) algorithm to capture these precursors for early loop prediction. Experiments across diverse LRMs validate its accuracy and elucidate the stability of long-chain reasoning.
Stable-RAG: Mitigating Retrieval-Permutation-Induced Hallucinations in Retrieval-Augmented Generation
Jan 07, 2026Retrieval-Augmented Generation (RAG) has become a key paradigm for reducing factual hallucinations in large language models (LLMs), yet little is known about how the order of retrieved documents affects model behavior. We empirically show that under Top-5 retrieval with the gold document included, LLM answers vary substantially across permutations of the retrieved set, even when the gold document is fixed in the first position. This reveals a previously underexplored sensitivity to retrieval permutations. Although robust RAG methods primarily focus on enhancing LLM robustness to low-quality retrieval and mitigating positional bias to distribute attention fairly over long contexts, neither approach directly addresses permutation sensitivity. In this paper, we propose Stable-RAG, which exploits permutation sensitivity estimation to mitigate permutation-induced hallucinations. Stable-RAG runs the generator under multiple retrieval orders, clusters hidden states, and decodes from a cluster-center representation that captures the dominant reasoning pattern. It then uses these reasoning results to align hallucinated outputs toward the correct answer, encouraging the model to produce consistent and accurate predictions across document permutations. Experiments on three QA datasets show that Stable-RAG significantly improves answer accuracy, reasoning consistency and robust generalization across datasets, retrievers, and input lengths compared with baselines.
Can Synthetic Query Rewrites Capture User Intent Better than Humans in Retrieval-Augmented Generation?
Sep 26, 2025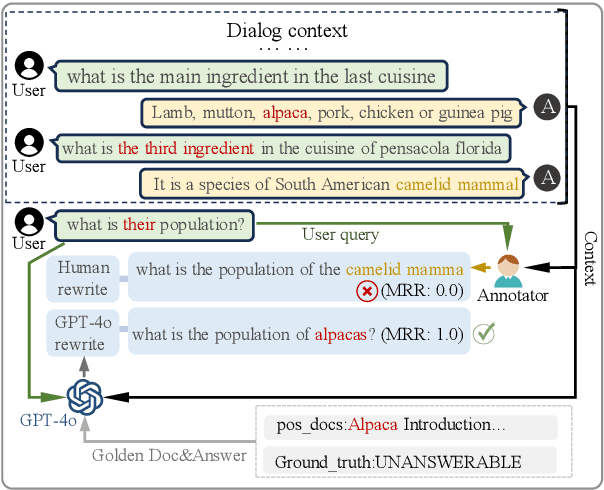



Multi-turn RAG systems often face queries with colloquial omissions and ambiguous references, posing significant challenges for effective retrieval and generation. Traditional query rewriting relies on human annotators to clarify queries, but due to limitations in annotators' expressive ability and depth of understanding, manually rewritten queries often diverge from those needed in real-world RAG systems, resulting in a gap between user intent and system response. We observe that high-quality synthetic queries can better bridge this gap, achieving superior performance in both retrieval and generation compared to human rewrites. This raises an interesting question: Can rewriting models trained on synthetic queries better capture user intent than human annotators? In this paper, we propose SynRewrite, a synthetic data-driven query rewriting model to generate high-quality synthetic rewrites more aligned with user intent. To construct training data, we prompt GPT-4o with dialogue history, current queries, positive documents, and answers to synthesize high-quality rewrites. A Flan-T5 model is then finetuned on this dataset to map dialogue history and queries to synthetic rewrites. Finally, we further enhance the rewriter using the generator's feedback through the DPO algorithm to boost end-task performance. Experiments on TopiOCQA and QRECC datasets show that SynRewrite consistently outperforms human rewrites in both retrieval and generation tasks. Our results demonstrate that synthetic rewrites can serve as a scalable and effective alternative to human annotations.
Stop Spinning Wheels: Mitigating LLM Overthinking via Mining Patterns for Early Reasoning Exit
Aug 25, 2025



Large language models (LLMs) enhance complex reasoning tasks by scaling the individual thinking process. However, prior work shows that overthinking can degrade overall performance. Motivated by observed patterns in thinking length and content length, we categorize reasoning into three stages: insufficient exploration stage, compensatory reasoning stage, and reasoning convergence stage. Typically, LLMs produce correct answers in the compensatory reasoning stage, whereas reasoning convergence often triggers overthinking, causing increased resource usage or even infinite loops. Therefore, mitigating overthinking hinges on detecting the end of the compensatory reasoning stage, defined as the Reasoning Completion Point (RCP). RCP typically appears at the end of the first complete reasoning cycle and can be identified by querying the LLM sentence by sentence or monitoring the probability of an end-of-thinking token (e.g., \texttt{</think>}), though these methods lack an efficient and precise balance. To improve this, we mine more sensitive and consistent RCP patterns and develop a lightweight thresholding strategy based on heuristic rules. Experimental evaluations on benchmarks (AIME24, AIME25, GPQA-D) demonstrate that the proposed method reduces token consumption while preserving or enhancing reasoning accuracy.
Distilling the Implicit Multi-Branch Structure in LLMs' Reasoning via Reinforcement Learning
May 22, 2025Distilling reasoning paths from teacher to student models via supervised fine-tuning (SFT) provides a shortcut for improving the reasoning ability of smaller Large Language Models (LLMs). However, the reasoning paths generated by teacher models often reflect only surface-level traces of their underlying authentic reasoning. Insights from cognitive neuroscience suggest that authentic reasoning involves a complex interweaving between meta-reasoning (which selects appropriate sub-problems from multiple candidates) and solving (which addresses the sub-problem). This implies authentic reasoning has an implicit multi-branch structure. Supervised fine-tuning collapses this rich structure into a flat sequence of token prediction in the teacher's reasoning path, preventing effective distillation of this structure to students. To address this limitation, we propose RLKD, a reinforcement learning (RL)-based distillation framework guided by a novel Generative Structure Reward Model (GSRM). Our GSRM converts reasoning paths into multiple meta-reasoning-solving steps and computes rewards to measure structural alignment between student and teacher reasoning. RLKD combines this reward with RL, enabling student LLMs to internalize the teacher's implicit multi-branch reasoning structure rather than merely mimicking fixed output paths. Experiments show RLKD surpasses standard SFT-RL pipelines even when trained on 0.1% of data under an RL-only regime, unlocking greater student reasoning potential than SFT-based distillation.
NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search
May 20, 2025Generative AI search is reshaping information retrieval by offering end-to-end answers to complex queries, reducing users' reliance on manually browsing and summarizing multiple web pages. However, while this paradigm enhances convenience, it disrupts the feedback-driven improvement loop that has historically powered the evolution of traditional Web search. Web search can continuously improve their ranking models by collecting large-scale, fine-grained user feedback (e.g., clicks, dwell time) at the document level. In contrast, generative AI search operates through a much longer search pipeline, spanning query decomposition, document retrieval, and answer generation, yet typically receives only coarse-grained feedback on the final answer. This introduces a feedback loop disconnect, where user feedback for the final output cannot be effectively mapped back to specific system components, making it difficult to improve each intermediate stage and sustain the feedback loop. In this paper, we envision NExT-Search, a next-generation paradigm designed to reintroduce fine-grained, process-level feedback into generative AI search. NExT-Search integrates two complementary modes: User Debug Mode, which allows engaged users to intervene at key stages; and Shadow User Mode, where a personalized user agent simulates user preferences and provides AI-assisted feedback for less interactive users. Furthermore, we envision how these feedback signals can be leveraged through online adaptation, which refines current search outputs in real-time, and offline update, which aggregates interaction logs to periodically fine-tune query decomposition, retrieval, and generation models. By restoring human control over key stages of the generative AI search pipeline, we believe NExT-Search offers a promising direction for building feedback-rich AI search systems that can evolve continuously alongside human feedback.