 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteLong: Resource-Efficient Long-Context Data Synthesis for LLMs
Sep 19, 2025
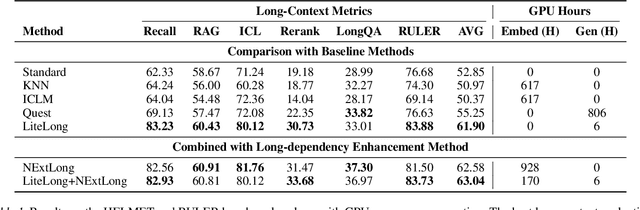


High-quality long-context data is essential for training large language models (LLMs) capable of processing extensive documents, yet existing synthesis approaches using relevance-based aggregation face challenges of computational efficiency. We present LiteLong, a resource-efficient method for synthesizing long-context data through structured topic organization and multi-agent debate. Our approach leverages the BISAC book classification system to provide a comprehensive hierarchical topic organization, and then employs a debate mechanism with multiple LLMs to generate diverse, high-quality topics within this structure. For each topic, we use lightweight BM25 retrieval to obtain relevant documents and concatenate them into 128K-token training samples. Experiments on HELMET and Ruler benchmarks demonstrate that LiteLong achieves competitive long-context performance and can seamlessly integrate with other long-dependency enhancement methods. LiteLong makes high-quality long-context data synthesis more accessible by reducing both computational and data engineering costs, facilitating further research in long-context language training.
GPMFS: Global Foundation and Personalized Optimization for Multi-Label Feature Selection
Apr 17, 2025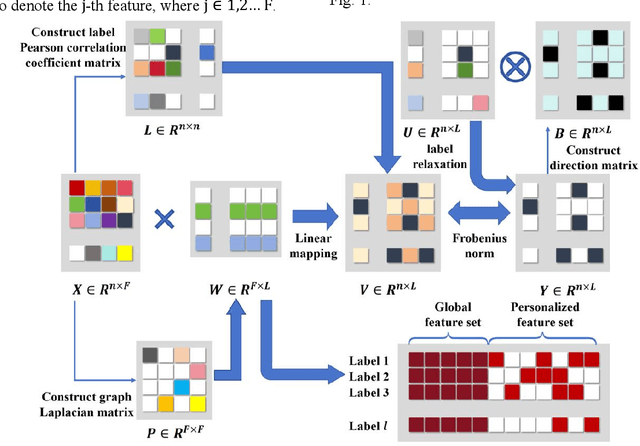
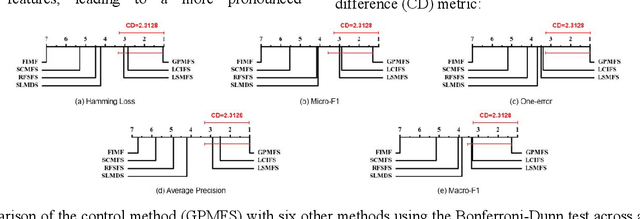
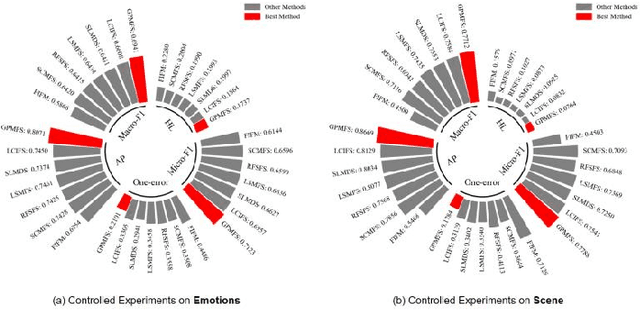
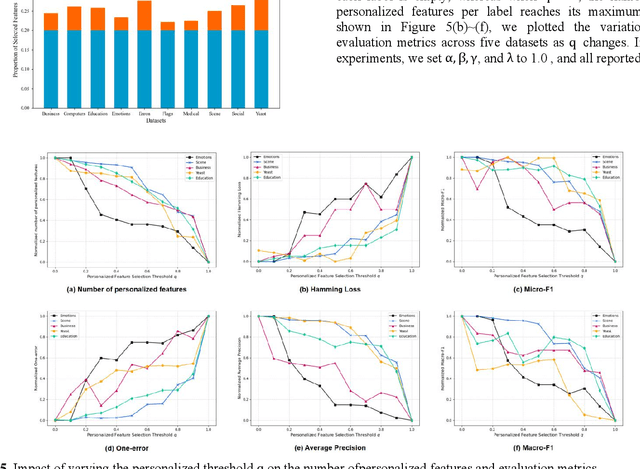
As artificial intelligence methods are increasingly applied to complex task scenarios, high dimensional multi-label learning has emerged as a prominent research focus. At present, the curse of dimensionality remains one of the major bottlenecks in high-dimensional multi-label learning, which can be effectively addressed through multi-label feature selection methods. However, existing multi-label feature selection methods mostly focus on identifying global features shared across all labels, which overlooks personalized characteristics and specific requirements of individual labels. This global-only perspective may limit the ability to capture label-specific discriminative information, thereby affecting overall performance. In this paper, we propose a novel method called GPMFS (Global Foundation and Personalized Optimization for Multi-Label Feature Selection). GPMFS firstly identifies global features by exploiting label correlations, then adaptively supplements each label with a personalized subset of discriminative features using a threshold-controlled strategy. Experiments on multiple real-world datasets demonstrate that GPMFS achieves superior performance while maintaining strong interpretability and robustness. Furthermore, GPMFS provides insights into the label-specific strength across different multi-label datasets, thereby demonstrating the necessity and potential applicability of personalized feature selection approaches.
Learning to Erase Private Knowledge from Multi-Documents for Retrieval-Augmented Large Language Models
Apr 14, 2025



Retrieval-Augmented Generation (RAG) is a promising technique for applying LLMs to proprietary domains. However, retrieved documents may contain sensitive knowledge, posing risks of privacy leakage in generative results. Thus, effectively erasing private information from retrieved documents is a key challenge for RAG. Unlike traditional text anonymization, RAG should consider: (1) the inherent multi-document reasoning may face de-anonymization attacks; (2) private knowledge varies by scenarios, so users should be allowed to customize which information to erase; (3) preserving sufficient publicly available knowledge for generation tasks. This paper introduces the privacy erasure task for RAG and proposes Eraser4RAG, a private knowledge eraser which effectively removes user-defined private knowledge from documents while preserving sufficient public knowledge for generation. Specifically, we first construct a global knowledge graph to identify potential knowledge across documents, aiming to defend against de-anonymization attacks. Then we randomly split it into private and public sub-graphs, and fine-tune Flan-T5 to rewrite the retrieved documents excluding private triples. Finally, PPO algorithm optimizes the rewriting model to minimize private triples and maximize public triples retention. Experiments on four QA datasets demonstrate that Eraser4RAG achieves superior erase performance than GPT-4o.
Defending Against Sophisticated Poisoning Attacks with RL-based Aggregation in Federated Learning
Jun 20, 2024



Federated learning is highly susceptible to model poisoning attacks, especially those meticulously crafted for servers. Traditional defense methods mainly focus on updating assessments or robust aggregation against manually crafted myopic attacks. When facing advanced attacks, their defense stability is notably insufficient. Therefore, it is imperative to develop adaptive defenses against such advanced poisoning attacks. We find that benign clients exhibit significantly higher data distribution stability than malicious clients in federated learning in both CV and NLP tasks. Therefore, the malicious clients can be recognized by observing the stability of their data distribution. In this paper, we propose AdaAggRL, an RL-based Adaptive Aggregation method, to defend against sophisticated poisoning attacks. Specifically, we first utilize distribution learning to simulate the clients' data distributions. Then, we use the maximum mean discrepancy (MMD) to calculate the pairwise similarity of the current local model data distribution, its historical data distribution, and global model data distribution. Finally, we use policy learning to adaptively determine the aggregation weights based on the above similarities. Experiments on four real-world datasets demonstrate that the proposed defense model significantly outperforms widely adopted defense models for sophisticated attacks.