 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaic: Multimodal Jailbreak against Closed-Source VLMs via Multi-View Ensemble Optimization
Apr 10, 2026Vision-Language Models (VLMs) are powerful but remain vulnerable to multimodal jailbreak attacks. Existing attacks mainly rely on either explicit visual prompt attacks or gradient-based adversarial optimization. While the former is easier to detect, the latter produces subtle perturbations that are less perceptible, but is usually optimized and evaluated under homogeneous open-source surrogate-target settings, leaving its effectiveness on commercial closed-source VLMs under heterogeneous settings unclear. To examine this issue, we study different surrogate-target settings and observe a consistent gap between homogeneous and heterogeneous settings, a phenomenon we term surrogate dependency. Motivated by this finding, we propose Mosaic, a Multi-view ensemble optimization framework for multimodal jailbreak against closed-source VLMs, which alleviates surrogate dependency under heterogeneous surrogate-target settings by reducing over-reliance on any single surrogate model and visual view. Specifically, Mosaic incorporates three core components: a Text-Side Transformation module, which perturbs refusal-sensitive lexical patterns; a Multi-View Image Optimization module, which updates perturbations under diverse cropped views to avoid overfitting to a single visual view; and a Surrogate Ensemble Guidance module, which aggregates optimization signals from multiple surrogate VLMs to reduce surrogate-specific bias. Extensive experiments on safety benchmarks demonstrate that Mosaic achieves state-of-the-art Attack Success Rate and Average Toxicity against commercial closed-source VLMs.
From Unfamiliar to Familiar: Detecting Pre-training Data via Gradient Deviations in Large Language Models
Mar 05, 2026Pre-training data detection for LLMs is essential for addressing copyright concerns and mitigating benchmark contamination. Existing methods mainly focus on the likelihood-based statistical features or heuristic signals before and after fine-tuning, but the former are susceptible to word frequency bias in corpora, and the latter strongly depend on the similarity of fine-tuning data. From an optimization perspective, we observe that during training, samples transition from unfamiliar to familiar in a manner reflected by systematic differences in gradient behavior. Familiar samples exhibit smaller update magnitudes, distinct update locations in model components, and more sharply activated neurons. Based on this insight, we propose GDS, a method that identifies pre-training data by probing Gradient Deviation Scores of target samples. Specifically, we first represent each sample using gradient profiles that capture the magnitude, location, and concentration of parameter updates across FFN and Attention modules, revealing consistent distinctions between member and non-member data. These features are then fed into a lightweight classifier to perform binary membership inference. Experiments on five public datasets show that GDS achieves state-of-the-art performance with significantly improved cross-dataset transferability over strong baselines. Further interpretability analyse show gradient feature distribution differences, enabling practical and scalable pre-training data detection.
Replacing Parameters with Preferences: Federated Alignment of Heterogeneous Vision-Language Models
Jan 31, 2026VLMs have broad potential in privacy-sensitive domains such as healthcare and finance, yet strict data-sharing constraints render centralized training infeasible. FL mitigates this issue by enabling decentralized training, but practical deployments face challenges due to client heterogeneity in computational resources, application requirements, and model architectures. We argue that while replacing data with model parameters characterizes the present of FL, replacing parameters with preferences represents a more scalable and privacy-preserving future. Motivated by this perspective, we propose MoR, a federated alignment framework based on GRPO with Mixture-of-Rewards for heterogeneous VLMs. MoR initializes a visual foundation model as a KL-regularized reference, while each client locally trains a reward model from local preference annotations, capturing specific evaluation signals without exposing raw data. To reconcile heterogeneous rewards, we introduce a routing-based fusion mechanism that adaptively aggregates client reward signals. Finally, the server performs GRPO with this mixed reward to optimize the base VLM. Experiments on three public VQA benchmarks demonstrate that MoR consistently outperforms federated alignment baselines in generalization, robustness, and cross-client adaptability. Our approach provides a scalable solution for privacy-preserving alignment of heterogeneous VLMs under federated settings.
Stable-RAG: Mitigating Retrieval-Permutation-Induced Hallucinations in Retrieval-Augmented Generation
Jan 07, 2026Retrieval-Augmented Generation (RAG) has become a key paradigm for reducing factual hallucinations in large language models (LLMs), yet little is known about how the order of retrieved documents affects model behavior. We empirically show that under Top-5 retrieval with the gold document included, LLM answers vary substantially across permutations of the retrieved set, even when the gold document is fixed in the first position. This reveals a previously underexplored sensitivity to retrieval permutations. Although robust RAG methods primarily focus on enhancing LLM robustness to low-quality retrieval and mitigating positional bias to distribute attention fairly over long contexts, neither approach directly addresses permutation sensitivity. In this paper, we propose Stable-RAG, which exploits permutation sensitivity estimation to mitigate permutation-induced hallucinations. Stable-RAG runs the generator under multiple retrieval orders, clusters hidden states, and decodes from a cluster-center representation that captures the dominant reasoning pattern. It then uses these reasoning results to align hallucinated outputs toward the correct answer, encouraging the model to produce consistent and accurate predictions across document permutations. Experiments on three QA datasets show that Stable-RAG significantly improves answer accuracy, reasoning consistency and robust generalization across datasets, retrievers, and input lengths compared with baselines.
Parameter Importance-Driven Continual Learning for Foundation Models
Nov 19, 2025Domain-specific post-training often causes catastrophic forgetting, making foundation models lose their general reasoning ability and limiting their adaptability to dynamic real-world environments. Preserving general capabilities while acquiring downstream domain knowledge is a central challenge for large language and multimodal models. Traditional continual learning methods, such as regularization, replay and architectural isolation, suffer from poor downstream performance, reliance on inaccessible historical data, or additional parameter overhead. While recent parameter-efficient tuning (PET) methods can alleviate forgetting, their effectiveness strongly depends on the choice of parameters and update strategies. In this paper, we introduce PIECE, a Parameter Importance Estimation-based Continual Enhancement method that preserves general ability while efficiently learning domain knowledge without accessing prior training data or increasing model parameters. PIECE selectively updates only 0.1% of core parameters most relevant to new tasks, guided by two importance estimators: PIECE-F based on Fisher Information, and PIECE-S based on a second-order normalization that combines gradient and curvature information. Experiments across three language models and two multimodal models show that PIECE maintains general capabilities and achieves state-of-the-art continual learning performance across diverse downstream tasks. Our results highlight a practical path to scalable, domain-adaptive foundation models without catastrophic forgetting.
Unlocking Dynamic Inter-Client Spatial Dependencies: A Federated Spatio-Temporal Graph Learning Method for Traffic Flow Forecasting
Nov 13, 2025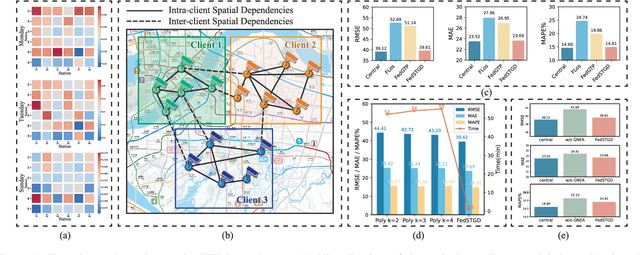

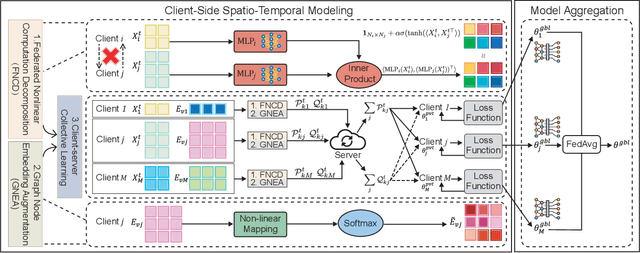
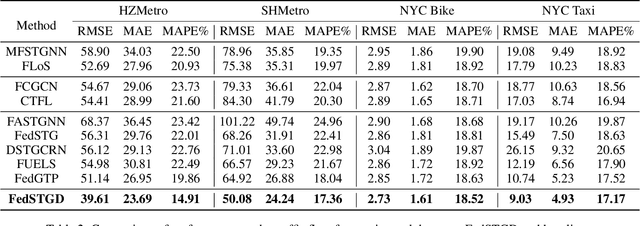
Spatio-temporal graphs are powerful tools for modeling complex dependencies in traffic time series. However, the distributed nature of real-world traffic data across multiple stakeholders poses significant challenges in modeling and reconstructing inter-client spatial dependencies while adhering to data locality constraints. Existing methods primarily address static dependencies, overlooking their dynamic nature and resulting in suboptimal performance. In response, we propose Federated Spatio-Temporal Graph with Dynamic Inter-Client Dependencies (FedSTGD), a framework designed to model and reconstruct dynamic inter-client spatial dependencies in federated learning. FedSTGD incorporates a federated nonlinear computation decomposition module to approximate complex graph operations. This is complemented by a graph node embedding augmentation module, which alleviates performance degradation arising from the decomposition. These modules are coordinated through a client-server collective learning protocol, which decomposes dynamic inter-client spatial dependency learning tasks into lightweight, parallelizable subtasks. Extensive experiments on four real-world datasets demonstrate that FedSTGD achieves superior performance over state-of-the-art baselines in terms of RMSE, MAE, and MAPE, approaching that of centralized baselines. Ablation studies confirm the contribution of each module in addressing dynamic inter-client spatial dependencies, while sensitivity analysis highlights the robustness of FedSTGD to variations in hyperparameters.
Detecting Stealthy Backdoor Samples based on Intra-class Distance for Large Language Models
May 29, 2025



Fine-tuning LLMs with datasets containing stealthy backdoors from publishers poses security risks to downstream applications. Mainstream detection methods either identify poisoned samples by analyzing the prediction probability of poisoned classification models or rely on the rewriting model to eliminate the stealthy triggers. However, the former cannot be applied to generation tasks, while the latter may degrade generation performance and introduce new triggers. Therefore, efficiently eliminating stealthy poisoned samples for LLMs remains an urgent problem. We observe that after applying TF-IDF clustering to the sample response, there are notable differences in the intra-class distances between clean and poisoned samples. Poisoned samples tend to cluster closely because of their specific malicious outputs, whereas clean samples are more scattered due to their more varied responses. Thus, in this paper, we propose a stealthy backdoor sample detection method based on Reference-Filtration and Tfidf-Clustering mechanisms (RFTC). Specifically, we first compare the sample response with the reference model's outputs and consider the sample suspicious if there's a significant discrepancy. And then we perform TF-IDF clustering on these suspicious samples to identify the true poisoned samples based on the intra-class distance. Experiments on two machine translation datasets and one QA dataset demonstrate that RFTC outperforms baselines in backdoor detection and model performance. Further analysis of different reference models also confirms the effectiveness of our Reference-Filtration.
A Federated Splitting Framework for LLMs: Security, Efficiency, and Adaptability
May 21, 2025Private data is typically larger and of higher quality than public data, offering great potential to improve LLM. However, its scattered distribution across data silos and the high computational demands of LLMs limit their deployment in federated environments. To address this, the transformer-based split learning model has emerged, offloading most model parameters to the server while retaining only the embedding and output layers on clients to ensure privacy. However, it still faces significant challenges in security, efficiency, and adaptability: 1) embedding gradients are vulnerable to attacks, leading to reverse engineering of private data; 2) the autoregressive nature of LLMs means that federated split learning can only train and infer sequentially, causing high communication overhead; 3) fixed partition points lack adaptability to downstream tasks. In this paper, we introduce FL-LLaMA, a secure, efficient, and adaptive federated split framework based on LLaMA2. First, we place some input and output blocks on the local client and inject Gaussian noise into forward-pass hidden states, enabling secure end-to-end propagation. Second, we employ client-batch and server-hierarchical strategies to achieve parallel training, along with attention-mask compression and KV cache mechanisms to accelerate inference, reducing communication costs effectively. Third, we allow users to dynamically adjust the partition points for input/output blocks based on specific task requirements and hardware limitations. Experiments on NLU, summarization and conversational QA tasks show that FL-LLaMA maintains performance comparable to centralized LLaMA2, and achieves up to 2x train speedups and 8x inference speedups. Further analysis of privacy attacks and different partition points also demonstrates the effectiveness of FL-LLaMA in security and adaptability.
CodeBC: A More Secure Large Language Model for Smart Contract Code Generation in Blockchain
Apr 28, 2025



Large language models (LLMs) excel at generating code from natural language instructions, yet they often lack an understanding of security vulnerabilities. This limitation makes it difficult for LLMs to avoid security risks in generated code, particularly in high-security programming tasks such as smart contract development for blockchain. Researchers have attempted to enhance the vulnerability awareness of these models by training them to differentiate between vulnerable and fixed code snippets. However, this approach relies heavily on manually labeled vulnerability data, which is only available for popular languages like Python and C++. For low-resource languages like Solidity, used in smart contracts, large-scale annotated datasets are scarce and difficult to obtain. To address this challenge, we introduce CodeBC, a code generation model specifically designed for generating secure smart contracts in blockchain. CodeBC employs a three-stage fine-tuning approach based on CodeLlama, distinguishing itself from previous methods by not relying on pairwise vulnerability location annotations. Instead, it leverages vulnerability and security tags to teach the model the differences between vulnerable and secure code. During the inference phase, the model leverages security tags to generate secure and robust code. Experimental results demonstrate that CodeBC outperforms baseline models in terms of BLEU, CodeBLEU, and compilation pass rates, while significantly reducing vulnerability rates. These findings validate the effectiveness and cost-efficiency of our three-stage fine-tuning strategy, making CodeBC a promising solution for generating secure smart contract code.
Learning to Erase Private Knowledge from Multi-Documents for Retrieval-Augmented Large Language Models
Apr 14, 2025



Retrieval-Augmented Generation (RAG) is a promising technique for applying LLMs to proprietary domains. However, retrieved documents may contain sensitive knowledge, posing risks of privacy leakage in generative results. Thus, effectively erasing private information from retrieved documents is a key challenge for RAG. Unlike traditional text anonymization, RAG should consider: (1) the inherent multi-document reasoning may face de-anonymization attacks; (2) private knowledge varies by scenarios, so users should be allowed to customize which information to erase; (3) preserving sufficient publicly available knowledge for generation tasks. This paper introduces the privacy erasure task for RAG and proposes Eraser4RAG, a private knowledge eraser which effectively removes user-defined private knowledge from documents while preserving sufficient public knowledge for generation. Specifically, we first construct a global knowledge graph to identify potential knowledge across documents, aiming to defend against de-anonymization attacks. Then we randomly split it into private and public sub-graphs, and fine-tune Flan-T5 to rewrite the retrieved documents excluding private triples. Finally, PPO algorithm optimizes the rewriting model to minimize private triples and maximize public triples retention. Experiments on four QA datasets demonstrate that Eraser4RAG achieves superior erase performance than GPT-4o.