 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaFeRw: Query Rewriting with Multi-Aspect Feedbacks for Retrieval-Augmented Large Language Models
Paper and Code
Aug 30, 2024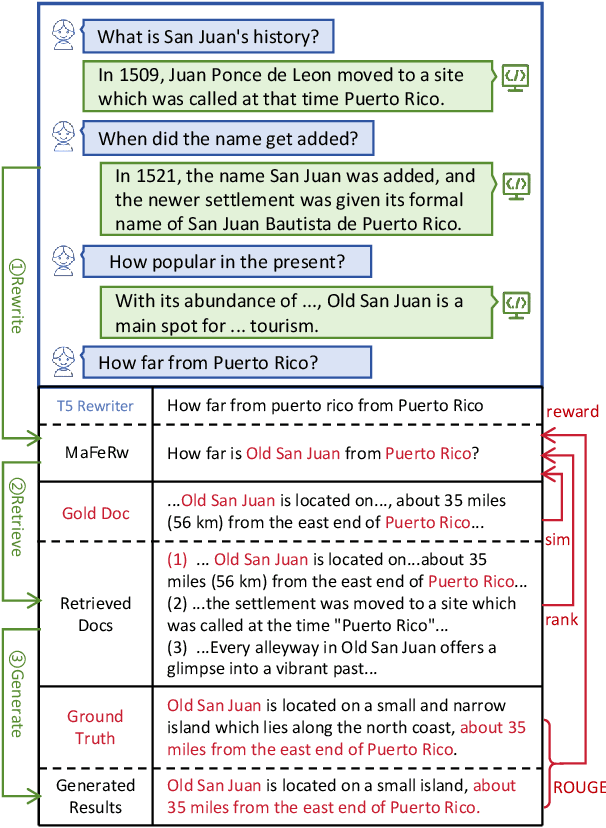

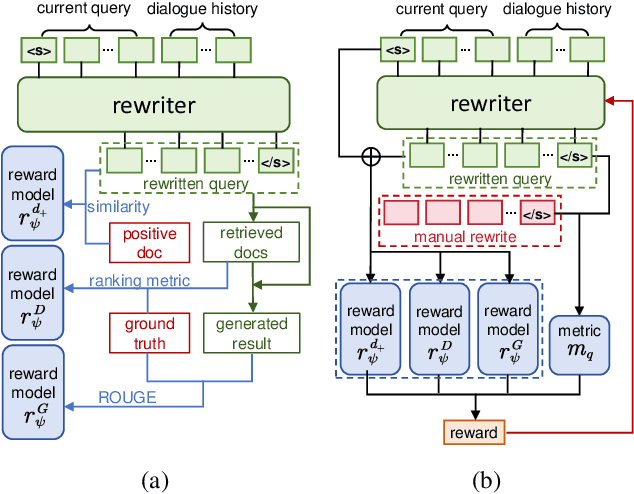

In a real-world RAG system, the current query often involves spoken ellipses and ambiguous references from dialogue contexts, necessitating query rewriting to better describe user's information needs. However, traditional context-based rewriting has minimal enhancement on downstream generation tasks due to the lengthy process from query rewriting to response generation. Some researchers try to utilize reinforcement learning with generation feedback to assist the rewriter, but these sparse rewards provide little guidance in most cases, leading to unstable training and generation results. We find that user's needs are also reflected in the gold document, retrieved documents and ground truth. Therefore, by feeding back these multi-aspect dense rewards to query rewriting, more stable and satisfactory responses can be achieved. In this paper, we propose a novel query rewriting method MaFeRw, which improves RAG performance by integrating multi-aspect feedback from both the retrieval process and generated results. Specifically, we first use manual data to train a T5 model for the rewriter initialization. Next, we design three metrics as reinforcement learning feedback: the similarity between the rewritten query and the gold document, the ranking metrics, and ROUGE between the generation and the ground truth. Inspired by RLAIF, we train three kinds of reward models for the above metrics to achieve more efficient training. Finally, we combine the scores of these reward models as feedback, and use PPO algorithm to explore the optimal query rewriting strategy. Experimental results on two conversational RAG datasets demonstrate that MaFeRw achieves superior generation metrics and more stable training compared to baselines.