 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Behavior Sequential Modeling with Transition-Aware Graph Attention Network for E-Commerce Recommendation
Jan 21, 2026User interactions on e-commerce platforms are inherently diverse, involving behaviors such as clicking, favoriting, adding to cart, and purchasing. The transitions between these behaviors offer valuable insights into user-item interactions, serving as a key signal for un- derstanding evolving preferences. Consequently, there is growing interest in leveraging multi-behavior data to better capture user intent. Recent studies have explored sequential modeling of multi- behavior data, many relying on transformer-based architectures with polynomial time complexity. While effective, these approaches often incur high computational costs, limiting their applicability in large-scale industrial systems with long user sequences. To address this challenge, we propose the Transition-Aware Graph Attention Network (TGA), a linear-complexity approach for modeling multi-behavior transitions. Unlike traditional trans- formers that treat all behavior pairs equally, TGA constructs a structured sparse graph by identifying informative transitions from three perspectives: (a) item-level transitions, (b) category-level transitions, and (c) neighbor-level transitions. Built upon the structured graph, TGA employs a transition-aware graph Attention mechanism that jointly models user-item interactions and behav- ior transition types, enabling more accurate capture of sequential patterns while maintaining computational efficiency. Experiments show that TGA outperforms all state-of-the-art models while sig- nificantly reducing computational cost. Notably, TGA has been deployed in a large-scale industrial production environment, where it leads to impressive improvements in key business metrics.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
BaseCal: Unsupervised Confidence Calibration via Base Model Signals
Jan 08, 2026Reliable confidence is essential for trusting the outputs of LLMs, yet widely deployed post-trained LLMs (PoLLMs) typically compromise this trust with severe overconfidence. In contrast, we observe that their corresponding base LLMs often remain well-calibrated. This naturally motivates us to calibrate PoLLM confidence using the base LLM as a reference. This work proposes two ways to achieve this. A straightforward solution, BaseCal-ReEval, evaluates PoLLM's responses by feeding them into the base LLM to get average probabilities as confidence. While effective, this approach introduces additional inference overhead. To address this, we propose BaseCal-Proj, which trains a lightweight projection to map the final-layer hidden states of PoLLMs back to those of their base LLMs. These projected states are then processed by the base LLM's output layer to derive base-calibrated confidence for PoLLM's responses. Notably, BaseCal is an unsupervised, plug-and-play solution that operates without human labels or LLM modifications. Experiments across five datasets and three LLM families demonstrate the effectiveness of BaseCal, reducing Expected Calibration Error (ECE) by an average of 42.90\% compared to the best unsupervised baselines.
LIR$^3$AG: A Lightweight Rerank Reasoning Strategy Framework for Retrieval-Augmented Generation
Dec 20, 2025Retrieval-Augmented Generation (RAG) effectively enhances Large Language Models (LLMs) by incorporating retrieved external knowledge into the generation process. Reasoning models improve LLM performance in multi-hop QA tasks, which require integrating and reasoning over multiple pieces of evidence across different documents to answer a complex question. However, they often introduce substantial computational costs, including increased token consumption and inference latency. To better understand and mitigate this trade-off, we conduct a comprehensive study of reasoning strategies for reasoning models in RAG multi-hop QA tasks. Our findings reveal that reasoning models adopt structured strategies to integrate retrieved and internal knowledge, primarily following two modes: Context-Grounded Reasoning, which relies directly on retrieved content, and Knowledge-Reconciled Reasoning, which resolves conflicts or gaps using internal knowledge. To this end, we propose a novel Lightweight Rerank Reasoning Strategy Framework for RAG (LiR$^3$AG) to enable non-reasoning models to transfer reasoning strategies by restructuring retrieved evidence into coherent reasoning chains. LiR$^3$AG significantly reduce the average 98% output tokens overhead and 58.6% inferencing time while improving 8B non-reasoning model's F1 performance ranging from 6.2% to 22.5% to surpass the performance of 32B reasoning model in RAG, offering a practical and efficient path forward for RAG systems.
AsarRec: Adaptive Sequential Augmentation for Robust Self-supervised Sequential Recommendation
Dec 16, 2025
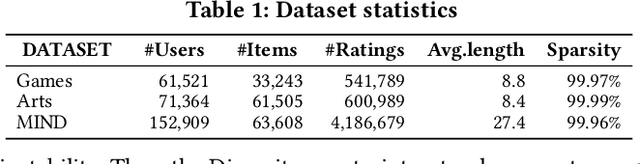


Sequential recommender systems have demonstrated strong capabilities in modeling users' dynamic preferences and capturing item transition patterns. However, real-world user behaviors are often noisy due to factors such as human errors, uncertainty, and behavioral ambiguity, which can lead to degraded recommendation performance. To address this issue, recent approaches widely adopt self-supervised learning (SSL), particularly contrastive learning, by generating perturbed views of user interaction sequences and maximizing their mutual information to improve model robustness. However, these methods heavily rely on their pre-defined static augmentation strategies~(where the augmentation type remains fixed once chosen) to construct augmented views, leading to two critical challenges: (1) the optimal augmentation type can vary significantly across different scenarios; (2) inappropriate augmentations may even degrade recommendation performance, limiting the effectiveness of SSL. To overcome these limitations, we propose an adaptive augmentation framework. We first unify existing basic augmentation operations into a unified formulation via structured transformation matrices. Building on this, we introduce AsarRec (Adaptive Sequential Augmentation for Robust Sequential Recommendation), which learns to generate transformation matrices by encoding user sequences into probabilistic transition matrices and projecting them into hard semi-doubly stochastic matrices via a differentiable Semi-Sinkhorn algorithm. To ensure that the learned augmentations benefit downstream performance, we jointly optimize three objectives: diversity, semantic invariance, and informativeness. Extensive experiments on three benchmark datasets under varying noise levels validate the effectiveness of AsarRec, demonstrating its superior robustness and consistent improvements.
GoalRank: Group-Relative Optimization for a Large Ranking Model
Sep 26, 2025Mainstream ranking approaches typically follow a Generator-Evaluator two-stage paradigm, where a generator produces candidate lists and an evaluator selects the best one. Recent work has attempted to enhance performance by expanding the number of candidate lists, for example, through multi-generator settings. However, ranking involves selecting a recommendation list from a combinatorially large space. Simply enlarging the candidate set remains ineffective, and performance gains quickly saturate. At the same time, recent advances in large recommendation models have shown that end-to-end one-stage models can achieve promising performance with the expectation of scaling laws. Motivated by this, we revisit ranking from a generator-only one-stage perspective. We theoretically prove that, for any (finite Multi-)Generator-Evaluator model, there always exists a generator-only model that achieves strictly smaller approximation error to the optimal ranking policy, while also enjoying scaling laws as its size increases. Building on this result, we derive an evidence upper bound of the one-stage optimization objective, from which we find that one can leverage a reward model trained on real user feedback to construct a reference policy in a group-relative manner. This reference policy serves as a practical surrogate of the optimal policy, enabling effective training of a large generator-only ranker. Based on these insights, we propose GoalRank, a generator-only ranking framework. Extensive offline experiments on public benchmarks and large-scale online A/B tests demonstrate that GoalRank consistently outperforms state-of-the-art methods.
Fine-tuning Done Right in Model Editing
Sep 26, 2025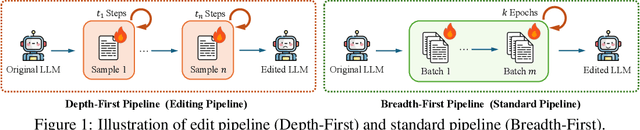
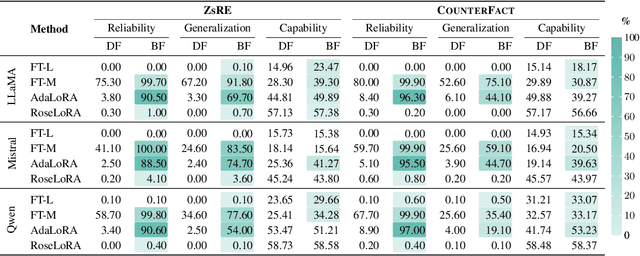
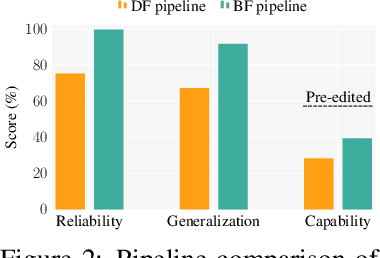

Fine-tuning, a foundational method for adapting large language models, has long been considered ineffective for model editing. Here, we challenge this belief, arguing that the reported failure arises not from the inherent limitation of fine-tuning itself, but from adapting it to the sequential nature of the editing task, a single-pass depth-first pipeline that optimizes each sample to convergence before moving on. While intuitive, this depth-first pipeline coupled with sample-wise updating over-optimizes each edit and induces interference across edits. Our controlled experiments reveal that simply restoring fine-tuning to the standard breadth-first (i.e., epoch-based) pipeline with mini-batch optimization substantially improves its effectiveness for model editing. Moreover, fine-tuning in editing also suffers from suboptimal tuning parameter locations inherited from prior methods. Through systematic analysis of tuning locations, we derive LocFT-BF, a simple and effective localized editing method built on the restored fine-tuning framework. Extensive experiments across diverse LLMs and datasets demonstrate that LocFT-BF outperforms state-of-the-art methods by large margins. Notably, to our knowledge, it is the first to sustain 100K edits and 72B-parameter models,10 x beyond prior practice, without sacrificing general capabilities. By clarifying a long-standing misconception and introducing a principled localized tuning strategy, we advance fine-tuning from an underestimated baseline to a leading method for model editing, establishing a solid foundation for future research.
Stop Spinning Wheels: Mitigating LLM Overthinking via Mining Patterns for Early Reasoning Exit
Aug 25, 2025



Large language models (LLMs) enhance complex reasoning tasks by scaling the individual thinking process. However, prior work shows that overthinking can degrade overall performance. Motivated by observed patterns in thinking length and content length, we categorize reasoning into three stages: insufficient exploration stage, compensatory reasoning stage, and reasoning convergence stage. Typically, LLMs produce correct answers in the compensatory reasoning stage, whereas reasoning convergence often triggers overthinking, causing increased resource usage or even infinite loops. Therefore, mitigating overthinking hinges on detecting the end of the compensatory reasoning stage, defined as the Reasoning Completion Point (RCP). RCP typically appears at the end of the first complete reasoning cycle and can be identified by querying the LLM sentence by sentence or monitoring the probability of an end-of-thinking token (e.g., \texttt{</think>}), though these methods lack an efficient and precise balance. To improve this, we mine more sensitive and consistent RCP patterns and develop a lightweight thresholding strategy based on heuristic rules. Experimental evaluations on benchmarks (AIME24, AIME25, GPQA-D) demonstrate that the proposed method reduces token consumption while preserving or enhancing reasoning accuracy.
Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions
Aug 11, 2025Speculative decoding is a standard method for accelerating the inference speed of large language models. However, scaling it for production environments poses several engineering challenges, including efficiently implementing different operations (e.g., tree attention and multi-round speculative decoding) on GPU. In this paper, we detail the training and inference optimization techniques that we have implemented to enable EAGLE-based speculative decoding at a production scale for Llama models. With these changes, we achieve a new state-of-the-art inference latency for Llama models. For example, Llama4 Maverick decodes at a speed of about 4 ms per token (with a batch size of one) on 8 NVIDIA H100 GPUs, which is 10% faster than the previously best known method. Furthermore, for EAGLE-based speculative decoding, our optimizations enable us to achieve a speed-up for large batch sizes between 1.4x and 2.0x at production scale.
LLM4MEA: Data-free Model Extraction Attacks on Sequential Recommenders via Large Language Models
Jul 22, 2025Recent studies have demonstrated the vulnerability of sequential recommender systems to Model Extraction Attacks (MEAs). MEAs collect responses from recommender systems to replicate their functionality, enabling unauthorized deployments and posing critical privacy and security risks. Black-box attacks in prior MEAs are ineffective at exposing recommender system vulnerabilities due to random sampling in data selection, which leads to misaligned synthetic and real-world distributions. To overcome this limitation, we propose LLM4MEA, a novel model extraction method that leverages Large Language Models (LLMs) as human-like rankers to generate data. It generates data through interactions between the LLM ranker and target recommender system. In each interaction, the LLM ranker analyzes historical interactions to understand user behavior, and selects items from recommendations with consistent preferences to extend the interaction history, which serves as training data for MEA. Extensive experiments demonstrate that LLM4MEA significantly outperforms existing approaches in data quality and attack performance, reducing the divergence between synthetic and real-world data by up to 64.98% and improving MEA performance by 44.82% on average. From a defensive perspective, we propose a simple yet effective defense strategy and identify key hyperparameters of recommender systems that can mitigate the risk of MEAs.