 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKairosVL: Orchestrating Time Series and Semantics for Unified Reasoning
Feb 24, 2026Driven by the increasingly complex and decision-oriented demands of time series analysis, we introduce the Semantic-Conditional Time Series Reasoning task, which extends conventional time series analysis beyond purely numerical modeling to incorporate contextual and semantic understanding. To further enhance the mode's reasoning capabilities on complex time series problems, we propose a two-round reinforcement learning framework: the first round strengthens the mode's perception of fundamental temporal primitives, while the second focuses on semantic-conditioned reasoning. The resulting model, KairosVL, achieves competitive performance across both synthetic and real-world tasks. Extensive experiments and ablation studies demonstrate that our framework not only boosts performance but also preserves intrinsic reasoning ability and significantly improves generalization to unseen scenarios. To summarize, our work highlights the potential of combining semantic reasoning with temporal modeling and provides a practical framework for real-world time series intelligence, which is in urgent demand.
LEC-KG: An LLM-Embedding Collaborative Framework for Domain-Specific Knowledge Graph Construction -- A Case Study on SDGs
Feb 02, 2026Constructing domain-specific knowledge graphs from unstructured text remains challenging due to heterogeneous entity mentions, long-tail relation distributions, and the absence of standardized schemas. We present LEC-KG, a bidirectional collaborative framework that integrates the semantic understanding of Large Language Models (LLMs) with the structural reasoning of Knowledge Graph Embeddings (KGE). Our approach features three key components: (1) hierarchical coarse-to-fine relation extraction that mitigates long-tail bias, (2) evidence-guided Chain-of-Thought feedback that grounds structural suggestions in source text, and (3) semantic initialization that enables structural validation for unseen entities. The two modules enhance each other iteratively-KGE provides structure-aware feedback to refine LLM extractions, while validated triples progressively improve KGE representations. We evaluate LEC-KG on Chinese Sustainable Development Goal (SDG) reports, demonstrating substantial improvements over LLM baselines, particularly on low-frequency relations. Through iterative refinement, our framework reliably transforms unstructured policy text into validated knowledge graph triples.
ViTs: Teaching Machines to See Time Series Anomalies Like Human Experts
Oct 06, 2025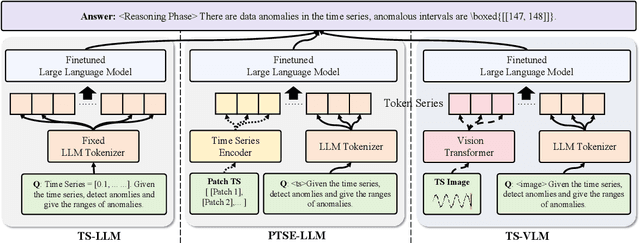

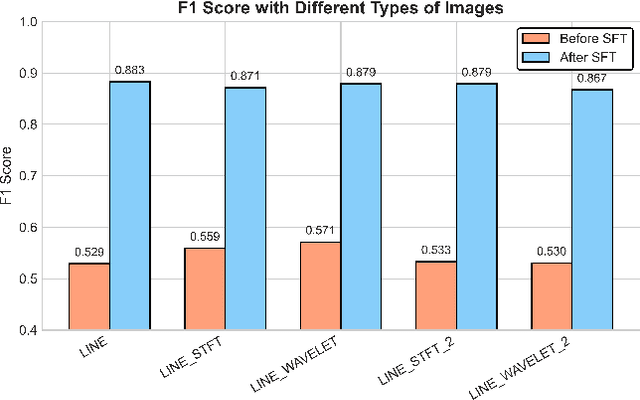
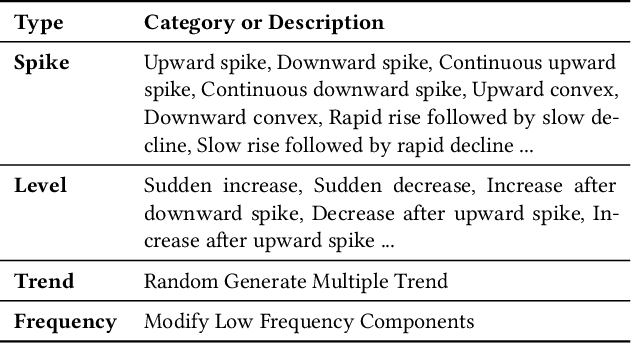
Web service administrators must ensure the stability of multiple systems by promptly detecting anomalies in Key Performance Indicators (KPIs). Achieving the goal of "train once, infer across scenarios" remains a fundamental challenge for time series anomaly detection models. Beyond improving zero-shot generalization, such models must also flexibly handle sequences of varying lengths during inference, ranging from one hour to one week, without retraining. Conventional approaches rely on sliding-window encoding and self-supervised learning, which restrict inference to fixed-length inputs. Large Language Models (LLMs) have demonstrated remarkable zero-shot capabilities across general domains. However, when applied to time series data, they face inherent limitations due to context length. To address this issue, we propose ViTs, a Vision-Language Model (VLM)-based framework that converts time series curves into visual representations. By rescaling time series images, temporal dependencies are preserved while maintaining a consistent input size, thereby enabling efficient processing of arbitrarily long sequences without context constraints. Training VLMs for this purpose introduces unique challenges, primarily due to the scarcity of aligned time series image-text data. To overcome this, we employ an evolutionary algorithm to automatically generate thousands of high-quality image-text pairs and design a three-stage training pipeline consisting of: (1) time series knowledge injection, (2) anomaly detection enhancement, and (3) anomaly reasoning refinement. Extensive experiments demonstrate that ViTs substantially enhance the ability of VLMs to understand and detect anomalies in time series data. All datasets and code will be publicly released at: https://anonymous.4open.science/r/ViTs-C484/.
CMoS: Rethinking Time Series Prediction Through the Lens of Chunk-wise Spatial Correlations
May 25, 2025Recent advances in lightweight time series forecasting models suggest the inherent simplicity of time series forecasting tasks. In this paper, we present CMoS, a super-lightweight time series forecasting model. Instead of learning the embedding of the shapes, CMoS directly models the spatial correlations between different time series chunks. Additionally, we introduce a Correlation Mixing technique that enables the model to capture diverse spatial correlations with minimal parameters, and an optional Periodicity Injection technique to ensure faster convergence. Despite utilizing as low as 1% of the lightweight model DLinear's parameters count, experimental results demonstrate that CMoS outperforms existing state-of-the-art models across multiple datasets. Furthermore, the learned weights of CMoS exhibit great interpretability, providing practitioners with valuable insights into temporal structures within specific application scenarios.
Online Poisoning Attack Against Reinforcement Learning under Black-box Environments
Dec 01, 2024
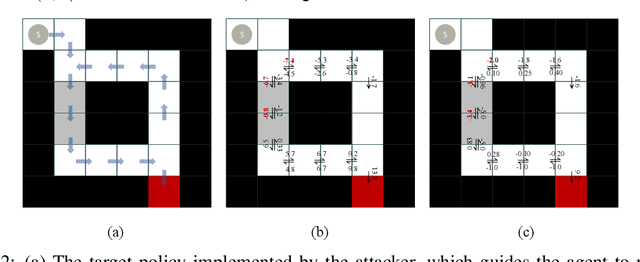
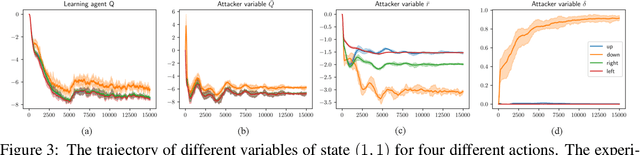
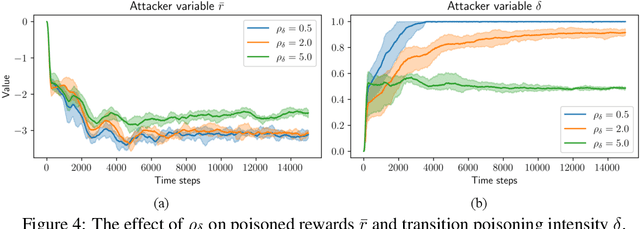
This paper proposes an online environment poisoning algorithm tailored for reinforcement learning agents operating in a black-box setting, where an adversary deliberately manipulates training data to lead the agent toward a mischievous policy. In contrast to prior studies that primarily investigate white-box settings, we focus on a scenario characterized by \textit{unknown} environment dynamics to the attacker and a \textit{flexible} reinforcement learning algorithm employed by the targeted agent. We first propose an attack scheme that is capable of poisoning the reward functions and state transitions. The poisoning task is formalized as a constrained optimization problem, following the framework of \cite{ma2019policy}. Given the transition probabilities are unknown to the attacker in a black-box environment, we apply a stochastic gradient descent algorithm, where the exact gradients are approximated using sample-based estimates. A penalty-based method along with a bilevel reformulation is then employed to transform the problem into an unconstrained counterpart and to circumvent the double-sampling issue. The algorithm's effectiveness is validated through a maze environment.
KAN-AD: Time Series Anomaly Detection with Kolmogorov-Arnold Networks
Nov 01, 2024



Time series anomaly detection (TSAD) has become an essential component of large-scale cloud services and web systems because it can promptly identify anomalies, providing early warnings to prevent greater losses. Deep learning-based forecasting methods have become very popular in TSAD due to their powerful learning capabilities. However, accurate predictions don't necessarily lead to better anomaly detection. Due to the common occurrence of noise, i.e., local peaks and drops in time series, existing black-box learning methods can easily learn these unintended patterns, significantly affecting anomaly detection performance. Kolmogorov-Arnold Networks (KAN) offers a potential solution by decomposing complex temporal sequences into a combination of multiple univariate functions, making the training process more controllable. However, KAN optimizes univariate functions using spline functions, which are also susceptible to the influence of local anomalies. To address this issue, we present KAN-AD, which leverages the Fourier series to emphasize global temporal patterns, thereby mitigating the influence of local peaks and drops. KAN-AD improves both effectiveness and efficiency by transforming the existing black-box learning approach into learning the weights preceding univariate functions. Experimental results show that, compared to the current state-of-the-art, we achieved an accuracy increase of 15% while boosting inference speed by 55 times.
TimeSeriesBench: An Industrial-Grade Benchmark for Time Series Anomaly Detection Models
Feb 26, 2024Driven by the proliferation of real-world application scenarios and scales, time series anomaly detection (TSAD) has attracted considerable scholarly and industrial interest. However, existing algorithms exhibit a gap in terms of training paradigm, online detection paradigm, and evaluation criteria when compared to the actual needs of real-world industrial systems. Firstly, current algorithms typically train a specific model for each individual time series. In a large-scale online system with tens of thousands of curves, maintaining such a multitude of models is impractical. The performance of using merely one single unified model to detect anomalies remains unknown. Secondly, most TSAD models are trained on the historical part of a time series and are tested on its future segment. In distributed systems, however, there are frequent system deployments and upgrades, with new, previously unseen time series emerging daily. The performance of testing newly incoming unseen time series on current TSAD algorithms remains unknown. Lastly, although some papers have conducted detailed surveys, the absence of an online evaluation platform prevents answering questions like "Who is the best at anomaly detection at the current stage?" In this paper, we propose TimeSeriesBench, an industrial-grade benchmark that we continuously maintain as a leaderboard. On this leaderboard, we assess the performance of existing algorithms across more than 168 evaluation settings combining different training and testing paradigms, evaluation metrics and datasets. Through our comprehensive analysis of the results, we provide recommendations for the future design of anomaly detection algorithms. To address known issues with existing public datasets, we release an industrial dataset to the public together with TimeSeriesBench. All code, data, and the online leaderboard have been made publicly available.
Revisiting VAE for Unsupervised Time Series Anomaly Detection: A Frequency Perspective
Feb 05, 2024Time series Anomaly Detection (AD) plays a crucial role for web systems. Various web systems rely on time series data to monitor and identify anomalies in real time, as well as to initiate diagnosis and remediation procedures. Variational Autoencoders (VAEs) have gained popularity in recent decades due to their superior de-noising capabilities, which are useful for anomaly detection. However, our study reveals that VAE-based methods face challenges in capturing long-periodic heterogeneous patterns and detailed short-periodic trends simultaneously. To address these challenges, we propose Frequency-enhanced Conditional Variational Autoencoder (FCVAE), a novel unsupervised AD method for univariate time series. To ensure an accurate AD, FCVAE exploits an innovative approach to concurrently integrate both the global and local frequency features into the condition of Conditional Variational Autoencoder (CVAE) to significantly increase the accuracy of reconstructing the normal data. Together with a carefully designed "target attention" mechanism, our approach allows the model to pick the most useful information from the frequency domain for better short-periodic trend construction. Our FCVAE has been evaluated on public datasets and a large-scale cloud system, and the results demonstrate that it outperforms state-of-the-art methods. This confirms the practical applicability of our approach in addressing the limitations of current VAE-based anomaly detection models.
InstructPix2NeRF: Instructed 3D Portrait Editing from a Single Image
Nov 06, 2023



With the success of Neural Radiance Field (NeRF) in 3D-aware portrait editing, a variety of works have achieved promising results regarding both quality and 3D consistency. However, these methods heavily rely on per-prompt optimization when handling natural language as editing instructions. Due to the lack of labeled human face 3D datasets and effective architectures, the area of human-instructed 3D-aware editing for open-world portraits in an end-to-end manner remains under-explored. To solve this problem, we propose an end-to-end diffusion-based framework termed InstructPix2NeRF, which enables instructed 3D-aware portrait editing from a single open-world image with human instructions. At its core lies a conditional latent 3D diffusion process that lifts 2D editing to 3D space by learning the correlation between the paired images' difference and the instructions via triplet data. With the help of our proposed token position randomization strategy, we could even achieve multi-semantic editing through one single pass with the portrait identity well-preserved. Besides, we further propose an identity consistency module that directly modulates the extracted identity signals into our diffusion process, which increases the multi-view 3D identity consistency. Extensive experiments verify the effectiveness of our method and show its superiority against strong baselines quantitatively and qualitatively.
OpsEval: A Comprehensive Task-Oriented AIOps Benchmark for Large Language Models
Oct 12, 2023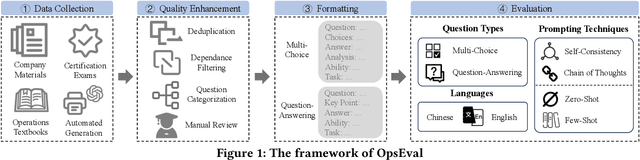
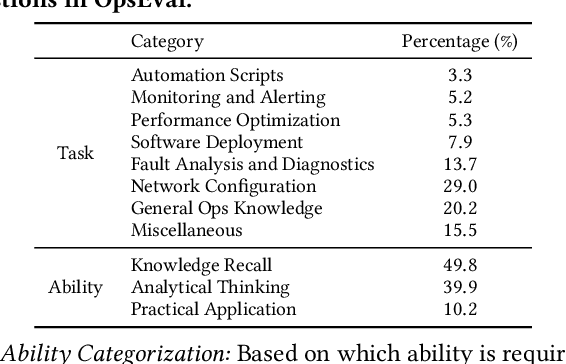

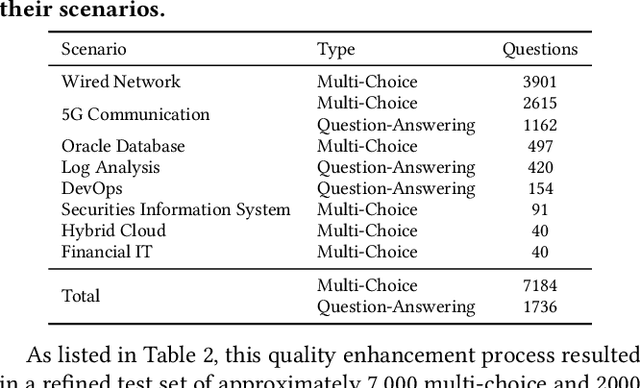
Large language models (LLMs) have exhibited remarkable capabilities in NLP-related tasks such as translation, summarizing, and generation. The application of LLMs in specific areas, notably AIOps (Artificial Intelligence for IT Operations), holds great potential due to their advanced abilities in information summarizing, report analyzing, and ability of API calling. Nevertheless, the performance of current LLMs in AIOps tasks is yet to be determined. Furthermore, a comprehensive benchmark is required to steer the optimization of LLMs tailored for AIOps. Compared with existing benchmarks that focus on evaluating specific fields like network configuration, in this paper, we present \textbf{OpsEval}, a comprehensive task-oriented AIOps benchmark designed for LLMs. For the first time, OpsEval assesses LLMs' proficiency in three crucial scenarios (Wired Network Operation, 5G Communication Operation, and Database Operation) at various ability levels (knowledge recall, analytical thinking, and practical application). The benchmark includes 7,200 questions in both multiple-choice and question-answer (QA) formats, available in English and Chinese. With quantitative and qualitative results, we show how various LLM tricks can affect the performance of AIOps, including zero-shot, chain-of-thought, and few-shot in-context learning. We find that GPT4-score is more consistent with experts than widely used Bleu and Rouge, which can be used to replace automatic metrics for large-scale qualitative evaluations.