 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpsEval: A Comprehensive Task-Oriented AIOps Benchmark for Large Language Models
Paper and Code
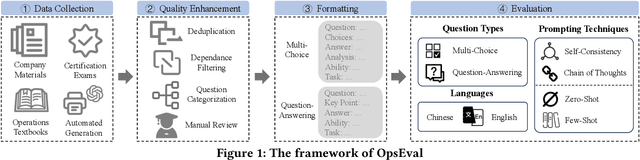
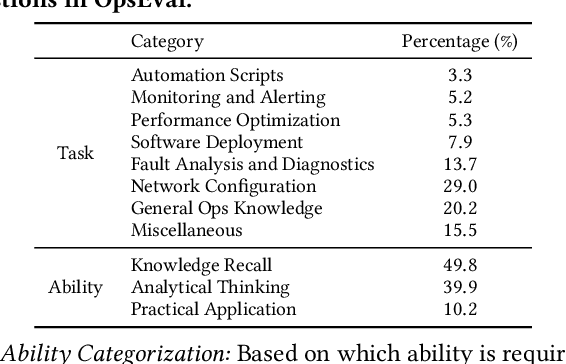

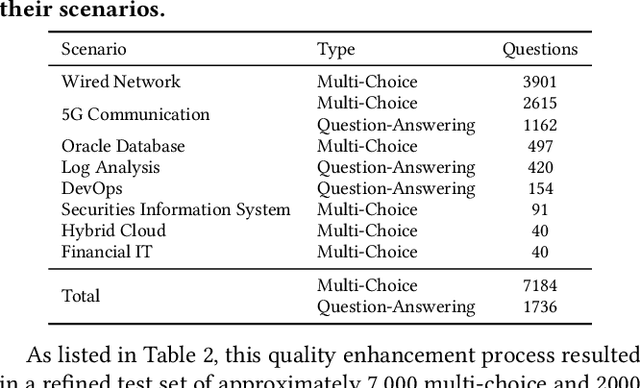
Large language models (LLMs) have exhibited remarkable capabilities in NLP-related tasks such as translation, summarizing, and generation. The application of LLMs in specific areas, notably AIOps (Artificial Intelligence for IT Operations), holds great potential due to their advanced abilities in information summarizing, report analyzing, and ability of API calling. Nevertheless, the performance of current LLMs in AIOps tasks is yet to be determined. Furthermore, a comprehensive benchmark is required to steer the optimization of LLMs tailored for AIOps. Compared with existing benchmarks that focus on evaluating specific fields like network configuration, in this paper, we present \textbf{OpsEval}, a comprehensive task-oriented AIOps benchmark designed for LLMs. For the first time, OpsEval assesses LLMs' proficiency in three crucial scenarios (Wired Network Operation, 5G Communication Operation, and Database Operation) at various ability levels (knowledge recall, analytical thinking, and practical application). The benchmark includes 7,200 questions in both multiple-choice and question-answer (QA) formats, available in English and Chinese. With quantitative and qualitative results, we show how various LLM tricks can affect the performance of AIOps, including zero-shot, chain-of-thought, and few-shot in-context learning. We find that GPT4-score is more consistent with experts than widely used Bleu and Rouge, which can be used to replace automatic metrics for large-scale qualitative evaluations.