 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLLaVA: An RL-central Framework for Language and Vision Assistants
Dec 25, 2025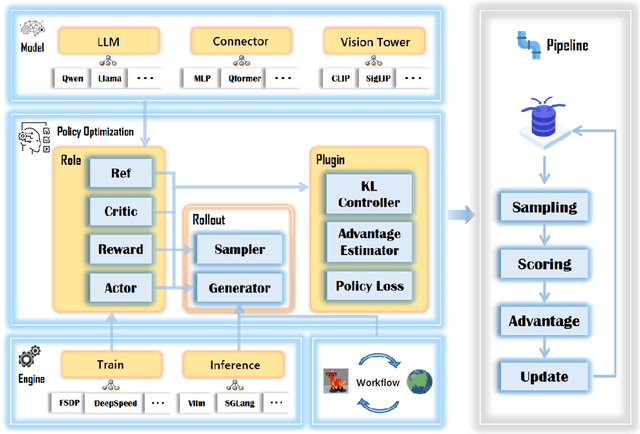

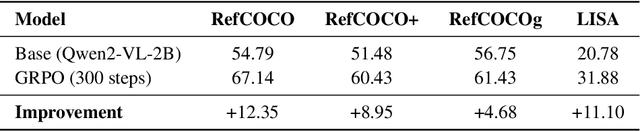
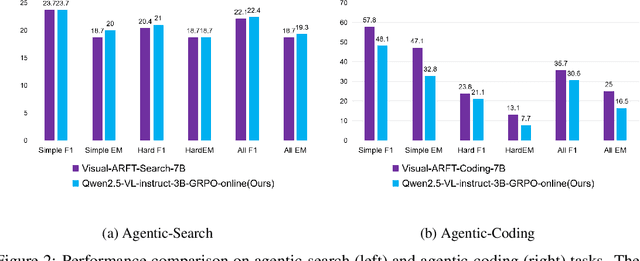
We present an RL-central framework for Language and Vision Assistants (RLLaVA) with its formulation of Markov decision process (MDP). RLLaVA decouples RL algorithmic logic from model architecture and distributed execution, supporting researchers in implementing new RL algorithms with minimal code, and to plug in a broad family of RL methods and vision-language models (VLMs) while remaining agnostic to specific training and inference engines. RLLaVA makes resource-efficient training of 1B--7B models feasible on common GPUs; notably, 4B-scale models can be trained end-to-end with full-parameter updates on a single 24GB GPU. Experiments on multi-modal and agentic tasks demonstrate that RLLaVA has task extensibility, and the models trained with it consistently improve performance over base models, competitive with other specially engineered RL frameworks. The code is available at https://github.com/TinyLoopX/RLLaVA.
Parallel Layer Normalization for Universal Approximation
May 19, 2025Universal approximation theorem (UAT) is a fundamental theory for deep neural networks (DNNs), demonstrating their powerful representation capacity to represent and approximate any function. The analyses and proofs of UAT are based on traditional network with only linear and nonlinear activation functions, but omitting normalization layers, which are commonly employed to enhance the training of modern networks. This paper conducts research on UAT of DNNs with normalization layers for the first time. We theoretically prove that an infinitely wide network -- composed solely of parallel layer normalization (PLN) and linear layers -- has universal approximation capacity. Additionally, we investigate the minimum number of neurons required to approximate $L$-Lipchitz continuous functions, with a single hidden-layer network. We compare the approximation capacity of PLN with traditional activation functions in theory. Different from the traditional activation functions, we identify that PLN can act as both activation function and normalization in deep neural networks at the same time. We also find that PLN can improve the performance when replacing LN in transformer architectures, which reveals the potential of PLN used in neural architectures.
DiffAtlas: GenAI-fying Atlas Segmentation via Image-Mask Diffusion
Mar 09, 2025Accurate medical image segmentation is crucial for precise anatomical delineation. Deep learning models like U-Net have shown great success but depend heavily on large datasets and struggle with domain shifts, complex structures, and limited training samples. Recent studies have explored diffusion models for segmentation by iteratively refining masks. However, these methods still retain the conventional image-to-mask mapping, making them highly sensitive to input data, which hampers stability and generalization. In contrast, we introduce DiffAtlas, a novel generative framework that models both images and masks through diffusion during training, effectively ``GenAI-fying'' atlas-based segmentation. During testing, the model is guided to generate a specific target image-mask pair, from which the corresponding mask is obtained. DiffAtlas retains the robustness of the atlas paradigm while overcoming its scalability and domain-specific limitations. Extensive experiments on CT and MRI across same-domain, cross-modality, varying-domain, and different data-scale settings using the MMWHS and TotalSegmentator datasets demonstrate that our approach outperforms existing methods, particularly in limited-data and zero-shot modality segmentation. Code is available at https://github.com/M3DV/DiffAtlas.
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
May 27, 2024As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.
LogicalDefender: Discovering, Extracting, and Utilizing Common-Sense Knowledge
Mar 18, 2024



Large text-to-image models have achieved astonishing performance in synthesizing diverse and high-quality images guided by texts. With detail-oriented conditioning control, even finer-grained spatial control can be achieved. However, some generated images still appear unreasonable, even with plentiful object features and a harmonious style. In this paper, we delve into the underlying causes and find that deep-level logical information, serving as common-sense knowledge, plays a significant role in understanding and processing images. Nonetheless, almost all models have neglected the importance of logical relations in images, resulting in poor performance in this aspect. Following this observation, we propose LogicalDefender, which combines images with the logical knowledge already summarized by humans in text. This encourages models to learn logical knowledge faster and better, and concurrently, extracts the widely applicable logical knowledge from both images and human knowledge. Experiments show that our model has achieved better logical performance, and the extracted logical knowledge can be effectively applied to other scenarios.
OpsEval: A Comprehensive Task-Oriented AIOps Benchmark for Large Language Models
Oct 12, 2023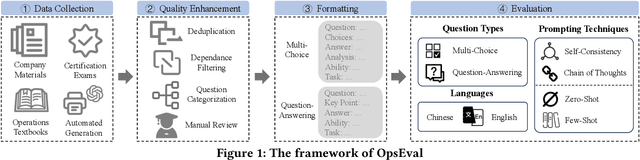
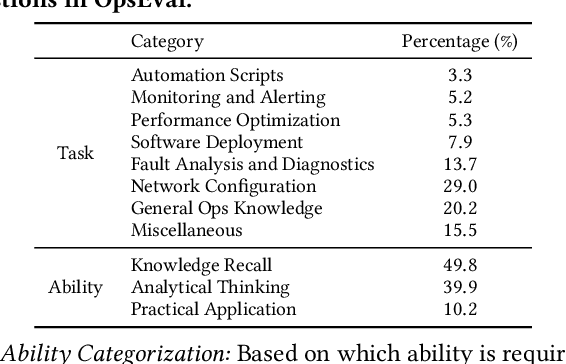

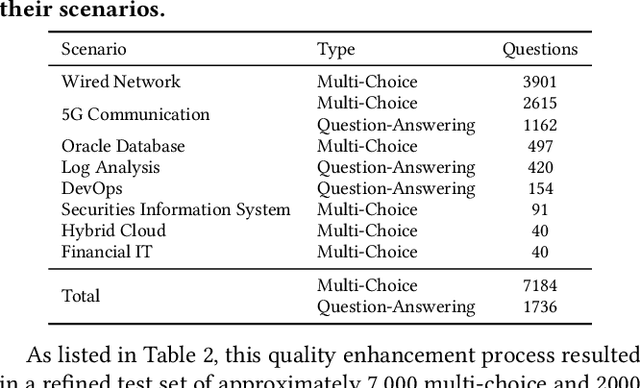
Large language models (LLMs) have exhibited remarkable capabilities in NLP-related tasks such as translation, summarizing, and generation. The application of LLMs in specific areas, notably AIOps (Artificial Intelligence for IT Operations), holds great potential due to their advanced abilities in information summarizing, report analyzing, and ability of API calling. Nevertheless, the performance of current LLMs in AIOps tasks is yet to be determined. Furthermore, a comprehensive benchmark is required to steer the optimization of LLMs tailored for AIOps. Compared with existing benchmarks that focus on evaluating specific fields like network configuration, in this paper, we present \textbf{OpsEval}, a comprehensive task-oriented AIOps benchmark designed for LLMs. For the first time, OpsEval assesses LLMs' proficiency in three crucial scenarios (Wired Network Operation, 5G Communication Operation, and Database Operation) at various ability levels (knowledge recall, analytical thinking, and practical application). The benchmark includes 7,200 questions in both multiple-choice and question-answer (QA) formats, available in English and Chinese. With quantitative and qualitative results, we show how various LLM tricks can affect the performance of AIOps, including zero-shot, chain-of-thought, and few-shot in-context learning. We find that GPT4-score is more consistent with experts than widely used Bleu and Rouge, which can be used to replace automatic metrics for large-scale qualitative evaluations.
Boosting Semantic Segmentation from the Perspective of Explicit Class Embeddings
Aug 24, 2023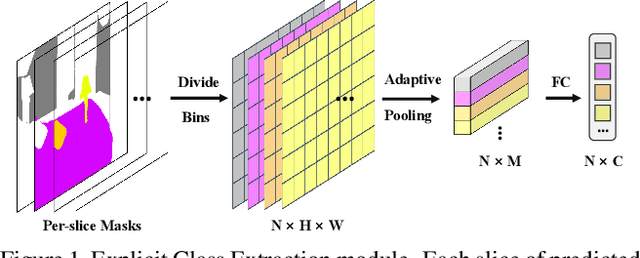
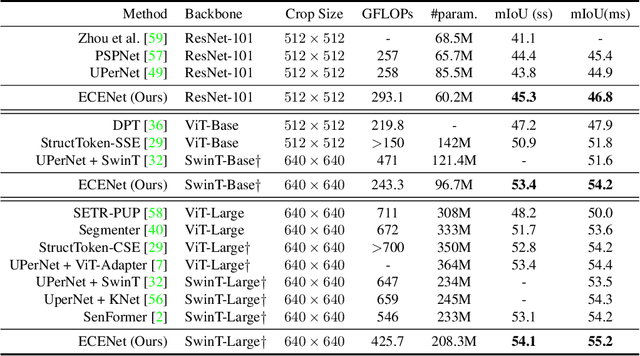
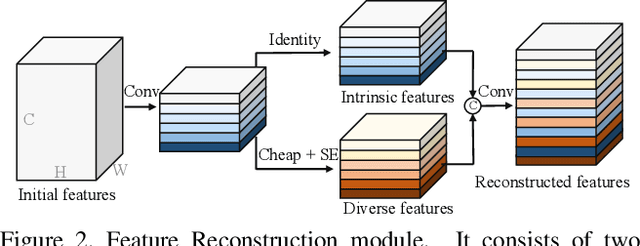
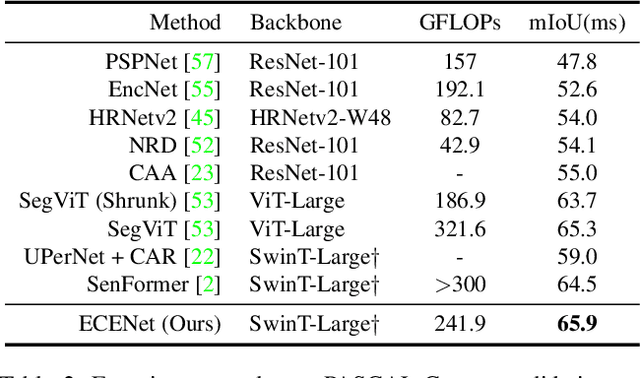
Semantic segmentation is a computer vision task that associates a label with each pixel in an image. Modern approaches tend to introduce class embeddings into semantic segmentation for deeply utilizing category semantics, and regard supervised class masks as final predictions. In this paper, we explore the mechanism of class embeddings and have an insight that more explicit and meaningful class embeddings can be generated based on class masks purposely. Following this observation, we propose ECENet, a new segmentation paradigm, in which class embeddings are obtained and enhanced explicitly during interacting with multi-stage image features. Based on this, we revisit the traditional decoding process and explore inverted information flow between segmentation masks and class embeddings. Furthermore, to ensure the discriminability and informativity of features from backbone, we propose a Feature Reconstruction module, which combines intrinsic and diverse branches together to ensure the concurrence of diversity and redundancy in features. Experiments show that our ECENet outperforms its counterparts on the ADE20K dataset with much less computational cost and achieves new state-of-the-art results on PASCAL-Context dataset. The code will be released at https://gitee.com/mindspore/models and https://github.com/Carol-lyh/ECENet.