 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Layer Normalization for Universal Approximation
May 19, 2025Universal approximation theorem (UAT) is a fundamental theory for deep neural networks (DNNs), demonstrating their powerful representation capacity to represent and approximate any function. The analyses and proofs of UAT are based on traditional network with only linear and nonlinear activation functions, but omitting normalization layers, which are commonly employed to enhance the training of modern networks. This paper conducts research on UAT of DNNs with normalization layers for the first time. We theoretically prove that an infinitely wide network -- composed solely of parallel layer normalization (PLN) and linear layers -- has universal approximation capacity. Additionally, we investigate the minimum number of neurons required to approximate $L$-Lipchitz continuous functions, with a single hidden-layer network. We compare the approximation capacity of PLN with traditional activation functions in theory. Different from the traditional activation functions, we identify that PLN can act as both activation function and normalization in deep neural networks at the same time. We also find that PLN can improve the performance when replacing LN in transformer architectures, which reveals the potential of PLN used in neural architectures.
On the Nonlinearity of Layer Normalization
Jun 03, 2024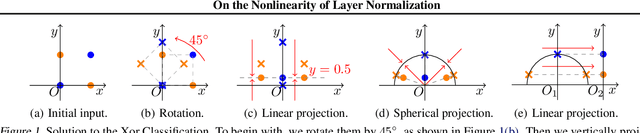
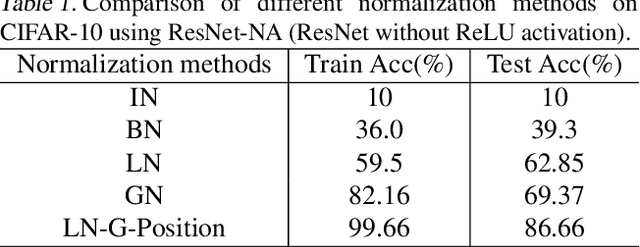
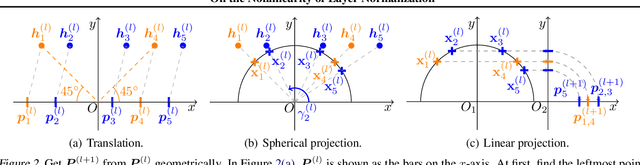
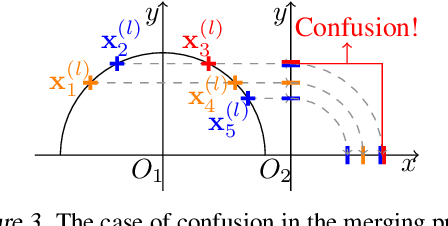
Layer normalization (LN) is a ubiquitous technique in deep learning but our theoretical understanding to it remains elusive. This paper investigates a new theoretical direction for LN, regarding to its nonlinearity and representation capacity. We investigate the representation capacity of a network with layerwise composition of linear and LN transformations, referred to as LN-Net. We theoretically show that, given $m$ samples with any label assignment, an LN-Net with only 3 neurons in each layer and $O(m)$ LN layers can correctly classify them. We further show the lower bound of the VC dimension of an LN-Net. The nonlinearity of LN can be amplified by group partition, which is also theoretically demonstrated with mild assumption and empirically supported by our experiments. Based on our analyses, we consider to design neural architecture by exploiting and amplifying the nonlinearity of LN, and the effectiveness is supported by our experiments.
Modulate Your Spectrum in Self-Supervised Learning
May 26, 2023Whitening loss provides theoretical guarantee in avoiding feature collapse for self-supervised learning (SSL) using joint embedding architectures. One typical implementation of whitening loss is hard whitening that designs whitening transformation over embedding and imposes the loss on the whitened output. In this paper, we propose spectral transformation (ST) framework to map the spectrum of embedding to a desired distribution during forward pass, and to modulate the spectrum of embedding by implicit gradient update during backward pass. We show that whitening transformation is a special instance of ST by definition, and there exist other instances that can avoid collapse by our empirical investigation. Furthermore, we propose a new instance of ST, called IterNorm with trace loss (INTL). We theoretically prove that INTL can avoid collapse and modulate the spectrum of embedding towards an equal-eigenvalue distribution during the course of optimization. Moreover, INTL achieves 76.6% top-1 accuracy in linear evaluation on ImageNet using ResNet-50, which exceeds the performance of the supervised baseline, and this result is obtained by using a batch size of only 256. Comprehensive experiments show that INTL is a promising SSL method in practice. The code is available at https://github.com/winci-ai/intl.