 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudit After Segmentation: Reference-Free Mask Quality Assessment for Language-Referred Audio-Visual Segmentation
Feb 03, 2026Language-referred audio-visual segmentation (Ref-AVS) aims to segment target objects described by natural language by jointly reasoning over video, audio, and text. Beyond generating segmentation masks, providing rich and interpretable diagnoses of mask quality remains largely underexplored. In this work, we introduce Mask Quality Assessment in the Ref-AVS context (MQA-RefAVS), a new task that evaluates the quality of candidate segmentation masks without relying on ground-truth annotations as references at inference time. Given audio-visual-language inputs and each provided segmentation mask, the task requires estimating its IoU with the unobserved ground truth, identifying the corresponding error type, and recommending an actionable quality-control decision. To support this task, we construct MQ-RAVSBench, a benchmark featuring diverse and representative mask error modes that span both geometric and semantic issues. We further propose MQ-Auditor, a multimodal large language model (MLLM)-based auditor that explicitly reasons over multimodal cues and mask information to produce quantitative and qualitative mask quality assessments. Extensive experiments demonstrate that MQ-Auditor outperforms strong open-source and commercial MLLMs and can be integrated with existing Ref-AVS systems to detect segmentation failures and support downstream segmentation improvement. Data and codes will be released at https://github.com/jasongief/MQA-RefAVS.
DuwatBench: Bridging Language and Visual Heritage through an Arabic Calligraphy Benchmark for Multimodal Understanding
Jan 27, 2026Arabic calligraphy represents one of the richest visual traditions of the Arabic language, blending linguistic meaning with artistic form. Although multimodal models have advanced across languages, their ability to process Arabic script, especially in artistic and stylized calligraphic forms, remains largely unexplored. To address this gap, we present DuwatBench, a benchmark of 1,272 curated samples containing about 1,475 unique words across six classical and modern calligraphic styles, each paired with sentence-level detection annotations. The dataset reflects real-world challenges in Arabic writing, such as complex stroke patterns, dense ligatures, and stylistic variations that often challenge standard text recognition systems. Using DuwatBench, we evaluated 13 leading Arabic and multilingual multimodal models and showed that while they perform well on clean text, they struggle with calligraphic variation, artistic distortions, and precise visual-text alignment. By publicly releasing DuwatBench and its annotations, we aim to advance culturally grounded multimodal research, foster fair inclusion of the Arabic language and visual heritage in AI systems, and support continued progress in this area. Our dataset (https://huggingface.co/datasets/MBZUAI/DuwatBench) and evaluation suit (https://github.com/mbzuai-oryx/DuwatBench) are publicly available.
A Benchmark and Agentic Framework for Omni-Modal Reasoning and Tool Use in Long Videos
Dec 18, 2025Long-form multimodal video understanding requires integrating vision, speech, and ambient audio with coherent long-range reasoning. Existing benchmarks emphasize either temporal length or multimodal richness, but rarely both and while some incorporate open-ended questions and advanced metrics, they mostly rely on single-score accuracy, obscuring failure modes. We introduce LongShOTBench, a diagnostic benchmark with open-ended, intent-driven questions; single- and multi-turn dialogues; and tasks requiring multimodal reasoning and agentic tool use across video, audio, and speech. Each item includes a reference answer and graded rubric for interpretable, and traceable evaluation. LongShOTBench is produced via a scalable, human-validated pipeline to ensure coverage and reproducibility. All samples in our LongShOTBench are human-verified and corrected. Furthermore, we present LongShOTAgent, an agentic system that analyzes long videos via preprocessing, search, and iterative refinement. On LongShOTBench, state-of-the-art MLLMs show large gaps: Gemini-2.5-Flash achieves 52.95%, open-source models remain below 30%, and LongShOTAgent attains 44.66%. These results underscore the difficulty of real-world long-form video understanding. LongShOTBench provides a practical, reproducible foundation for evaluating and improving MLLMs. All resources are available on GitHub: https://github.com/mbzuai-oryx/longshot.
Beyond Simple Edits: Composed Video Retrieval with Dense Modifications
Aug 19, 2025Composed video retrieval is a challenging task that strives to retrieve a target video based on a query video and a textual description detailing specific modifications. Standard retrieval frameworks typically struggle to handle the complexity of fine-grained compositional queries and variations in temporal understanding limiting their retrieval ability in the fine-grained setting. To address this issue, we introduce a novel dataset that captures both fine-grained and composed actions across diverse video segments, enabling more detailed compositional changes in retrieved video content. The proposed dataset, named Dense-WebVid-CoVR, consists of 1.6 million samples with dense modification text that is around seven times more than its existing counterpart. We further develop a new model that integrates visual and textual information through Cross-Attention (CA) fusion using grounded text encoder, enabling precise alignment between dense query modifications and target videos. The proposed model achieves state-of-the-art results surpassing existing methods on all metrics. Notably, it achieves 71.3\% Recall@1 in visual+text setting and outperforms the state-of-the-art by 3.4\%, highlighting its efficacy in terms of leveraging detailed video descriptions and dense modification texts. Our proposed dataset, code, and model are available at :https://github.com/OmkarThawakar/BSE-CoVR
RAGNet: Large-scale Reasoning-based Affordance Segmentation Benchmark towards General Grasping
Jul 31, 2025



General robotic grasping systems require accurate object affordance perception in diverse open-world scenarios following human instructions. However, current studies suffer from the problem of lacking reasoning-based large-scale affordance prediction data, leading to considerable concern about open-world effectiveness. To address this limitation, we build a large-scale grasping-oriented affordance segmentation benchmark with human-like instructions, named RAGNet. It contains 273k images, 180 categories, and 26k reasoning instructions. The images cover diverse embodied data domains, such as wild, robot, ego-centric, and even simulation data. They are carefully annotated with an affordance map, while the difficulty of language instructions is largely increased by removing their category name and only providing functional descriptions. Furthermore, we propose a comprehensive affordance-based grasping framework, named AffordanceNet, which consists of a VLM pre-trained on our massive affordance data and a grasping network that conditions an affordance map to grasp the target. Extensive experiments on affordance segmentation benchmarks and real-robot manipulation tasks show that our model has a powerful open-world generalization ability. Our data and code is available at https://github.com/wudongming97/AffordanceNet.
AI in Agriculture: A Survey of Deep Learning Techniques for Crops, Fisheries and Livestock
Jul 29, 2025



Crops, fisheries and livestock form the backbone of global food production, essential to feed the ever-growing global population. However, these sectors face considerable challenges, including climate variability, resource limitations, and the need for sustainable management. Addressing these issues requires efficient, accurate, and scalable technological solutions, highlighting the importance of artificial intelligence (AI). This survey presents a systematic and thorough review of more than 200 research works covering conventional machine learning approaches, advanced deep learning techniques (e.g., vision transformers), and recent vision-language foundation models (e.g., CLIP) in the agriculture domain, focusing on diverse tasks such as crop disease detection, livestock health management, and aquatic species monitoring. We further cover major implementation challenges such as data variability and experimental aspects: datasets, performance evaluation metrics, and geographical focus. We finish the survey by discussing potential open research directions emphasizing the need for multimodal data integration, efficient edge-device deployment, and domain-adaptable AI models for diverse farming environments. Rapid growth of evolving developments in this field can be actively tracked on our project page: https://github.com/umair1221/AI-in-Agriculture
TAViS: Text-bridged Audio-Visual Segmentation with Foundation Models
Jun 13, 2025Audio-Visual Segmentation (AVS) faces a fundamental challenge of effectively aligning audio and visual modalities. While recent approaches leverage foundation models to address data scarcity, they often rely on single-modality knowledge or combine foundation models in an off-the-shelf manner, failing to address the cross-modal alignment challenge. In this paper, we present TAViS, a novel framework that \textbf{couples} the knowledge of multimodal foundation models (ImageBind) for cross-modal alignment and a segmentation foundation model (SAM2) for precise segmentation. However, effectively combining these models poses two key challenges: the difficulty in transferring the knowledge between SAM2 and ImageBind due to their different feature spaces, and the insufficiency of using only segmentation loss for supervision. To address these challenges, we introduce a text-bridged design with two key components: (1) a text-bridged hybrid prompting mechanism where pseudo text provides class prototype information while retaining modality-specific details from both audio and visual inputs, and (2) an alignment supervision strategy that leverages text as a bridge to align shared semantic concepts within audio-visual modalities. Our approach achieves superior performance on single-source, multi-source, semantic datasets, and excels in zero-shot settings.
TerraFM: A Scalable Foundation Model for Unified Multisensor Earth Observation
Jun 06, 2025Modern Earth observation (EO) increasingly leverages deep learning to harness the scale and diversity of satellite imagery across sensors and regions. While recent foundation models have demonstrated promising generalization across EO tasks, many remain limited by the scale, geographical coverage, and spectral diversity of their training data, factors critical for learning globally transferable representations. In this work, we introduce TerraFM, a scalable self-supervised learning model that leverages globally distributed Sentinel-1 and Sentinel-2 imagery, combined with large spatial tiles and land-cover aware sampling to enrich spatial and semantic coverage. By treating sensing modalities as natural augmentations in our self-supervised approach, we unify radar and optical inputs via modality-specific patch embeddings and adaptive cross-attention fusion. Our training strategy integrates local-global contrastive learning and introduces a dual-centering mechanism that incorporates class-frequency-aware regularization to address long-tailed distributions in land cover.TerraFM achieves strong generalization on both classification and segmentation tasks, outperforming prior models on GEO-Bench and Copernicus-Bench. Our code and pretrained models are publicly available at: https://github.com/mbzuai-oryx/TerraFM .
Agent-X: Evaluating Deep Multimodal Reasoning in Vision-Centric Agentic Tasks
May 30, 2025Deep reasoning is fundamental for solving complex tasks, especially in vision-centric scenarios that demand sequential, multimodal understanding. However, existing benchmarks typically evaluate agents with fully synthetic, single-turn queries, limited visual modalities, and lack a framework to assess reasoning quality over multiple steps as required in real-world settings. To address this, we introduce Agent-X, a large-scale benchmark for evaluating vision-centric agents multi-step and deep reasoning capabilities in real-world, multimodal settings. Agent- X features 828 agentic tasks with authentic visual contexts, including images, multi-image comparisons, videos, and instructional text. These tasks span six major agentic environments: general visual reasoning, web browsing, security and surveillance, autonomous driving, sports, and math reasoning. Our benchmark requires agents to integrate tool use with explicit, stepwise decision-making in these diverse settings. In addition, we propose a fine-grained, step-level evaluation framework that assesses the correctness and logical coherence of each reasoning step and the effectiveness of tool usage throughout the task. Our results reveal that even the best-performing models, including GPT, Gemini, and Qwen families, struggle to solve multi-step vision tasks, achieving less than 50% full-chain success. These findings highlight key bottlenecks in current LMM reasoning and tool-use capabilities and identify future research directions in vision-centric agentic reasoning models. Our data and code are publicly available at https://github.com/mbzuai-oryx/Agent-X
Fann or Flop: A Multigenre, Multiera Benchmark for Arabic Poetry Understanding in LLMs
May 26, 2025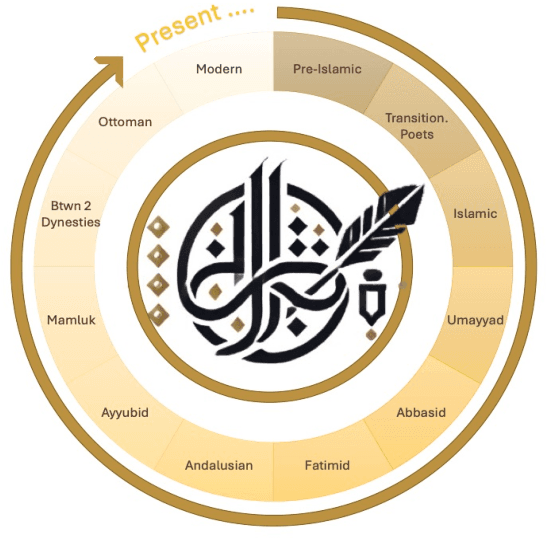
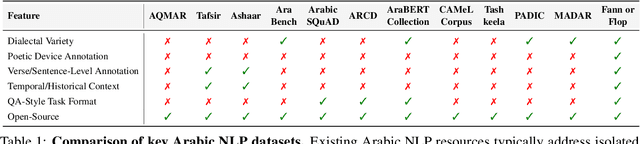
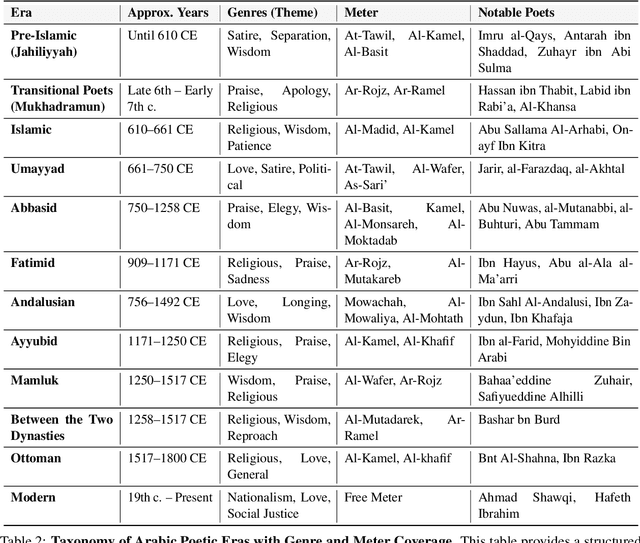
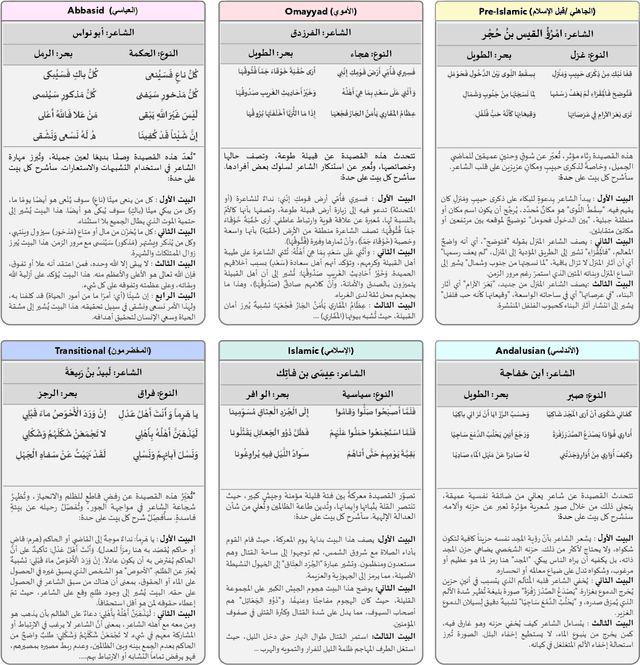
Arabic poetry is one of the richest and most culturally rooted forms of expression in the Arabic language, known for its layered meanings, stylistic diversity, and deep historical continuity. Although large language models (LLMs) have demonstrated strong performance across languages and tasks, their ability to understand Arabic poetry remains largely unexplored. In this work, we introduce \emph{Fann or Flop}, the first benchmark designed to assess the comprehension of Arabic poetry by LLMs in 12 historical eras, covering 14 core poetic genres and a variety of metrical forms, from classical structures to contemporary free verse. The benchmark comprises a curated corpus of poems with explanations that assess semantic understanding, metaphor interpretation, prosodic awareness, and cultural context. We argue that poetic comprehension offers a strong indicator for testing how good the LLM understands classical Arabic through Arabic poetry. Unlike surface-level tasks, this domain demands deeper interpretive reasoning and cultural sensitivity. Our evaluation of state-of-the-art LLMs shows that most models struggle with poetic understanding despite strong results on standard Arabic benchmarks. We release "Fann or Flop" along with the evaluation suite as an open-source resource to enable rigorous evaluation and advancement for Arabic language models. Code is available at: https://github.com/mbzuai-oryx/FannOrFlop.