 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic AI for Remote Sensing: Technical Challenges and Research Directions
Apr 27, 2026Earth Observation (EO) is moving beyond static prediction toward multi-step analytical workflows that require coordinated reasoning over data, tools, and geospatial state. While foundation models and vision-language models have expanded representation learning and language-grounded interaction for remote sensing, and agentic AI has demonstrated long-horizon reasoning and external tool use, EO is not a straightforward extension of generic agentic AI. EO workflows operate over georeferenced, multi-modal, and temporally structured data, where operations such as reprojection, resampling, compositing, and aggregation actively transform the underlying state and can constrain subsequent analysis. As a result, errors may propagate silently across steps, and correctness depends not only on internal coherence, but also on geospatial consistency, temporally valid comparisons, and physical validity. This position paper argues that these challenges are structural rather than incidental. We identify the implicit assumptions commonly made in generic agentic models, analyze how they break in geospatial workflows, and characterize the resulting failure modes in multi-step EO pipelines. We then outline design principles for EO-native agents centered on structured geospatial state, tool-aware reasoning, verifier-guided execution, and learning objectives aligned with geospatial and physical validity. Finally, we present research directions spanning EO-specific benchmarks, hybrid supervised and reinforcement learning, constrained self-improvement, and trajectory-level evaluation beyond final-answer accuracy. Building reliable geospatial agents therefore requires rethinking agent design around the physical, geospatial, and workflow constraints that govern EO analysis.
CoVR-R:Reason-Aware Composed Video Retrieval
Mar 20, 2026Composed Video Retrieval (CoVR) aims to find a target video given a reference video and a textual modification. Prior work assumes the modification text fully specifies the visual changes, overlooking after-effects and implicit consequences (e.g., motion, state transitions, viewpoint or duration cues) that emerge from the edit. We argue that successful CoVR requires reasoning about these after-effects. We introduce a reasoning-first, zero-shot approach that leverages large multimodal models to (i) infer causal and temporal consequences implied by the edit, and (ii) align the resulting reasoned queries to candidate videos without task-specific finetuning. To evaluate reasoning in CoVR, we also propose CoVR-Reason, a benchmark that pairs each (reference, edit, target) triplet with structured internal reasoning traces and challenging distractors that require predicting after-effects rather than keyword matching. Experiments show that our zero-shot method outperforms strong retrieval baselines on recall at K and particularly excels on implicit-effect subsets. Our automatic and human analysis confirm higher step consistency and effect factuality in our retrieved results. Our findings show that incorporating reasoning into general-purpose multimodal models enables effective CoVR by explicitly accounting for causal and temporal after-effects. This reduces dependence on task-specific supervision, improves generalization to challenging implicit-effect cases, and enhances interpretability of retrieval outcomes. These results point toward a scalable and principled framework for explainable video search. The model, code, and benchmark are available at https://github.com/mbzuai-oryx/CoVR-R.
MediX-R1: Open Ended Medical Reinforcement Learning
Feb 26, 2026We introduce MediX-R1, an open-ended Reinforcement Learning (RL) framework for medical multimodal large language models (MLLMs) that enables clinically grounded, free-form answers beyond multiple-choice formats. MediX-R1 fine-tunes a baseline vision-language backbone with Group Based RL and a composite reward tailored for medical reasoning: an LLM-based accuracy reward that judges semantic correctness with a strict YES/NO decision, a medical embedding-based semantic reward to capture paraphrases and terminology variants, and lightweight format and modality rewards that enforce interpretable reasoning and modality recognition. This multi-signal design provides stable, informative feedback for open-ended outputs where traditional verifiable or MCQ-only rewards fall short. To measure progress, we propose a unified evaluation framework for both text-only and image+text tasks that uses a Reference-based LLM-as-judge in place of brittle string-overlap metrics, capturing semantic correctness, reasoning, and contextual alignment. Despite using only $\sim51$K instruction examples, MediX-R1 achieves excellent results across standard medical LLM (text-only) and VLM (image + text) benchmarks, outperforming strong open-source baselines and delivering particularly large gains on open-ended clinical tasks. Our results demonstrate that open-ended RL with comprehensive reward signals and LLM-based evaluation is a practical path toward reliable medical reasoning in multimodal models. Our trained models, curated datasets and source code are available at https://medix.cvmbzuai.com
VideoMathQA: Benchmarking Mathematical Reasoning via Multimodal Understanding in Videos
Jun 05, 2025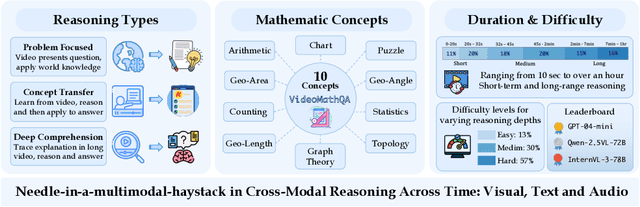
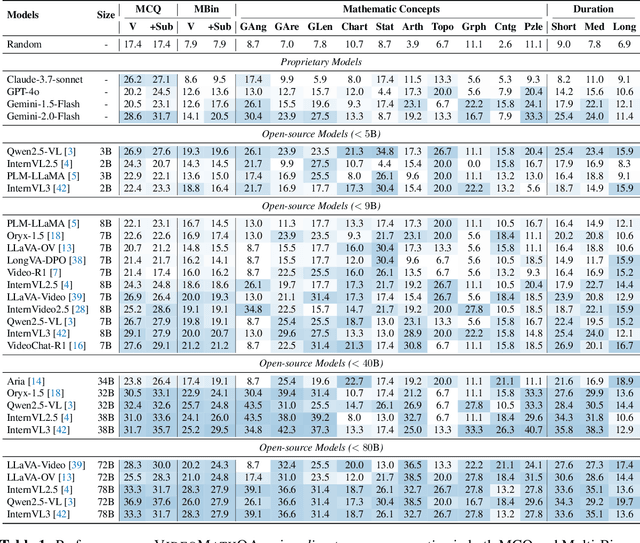

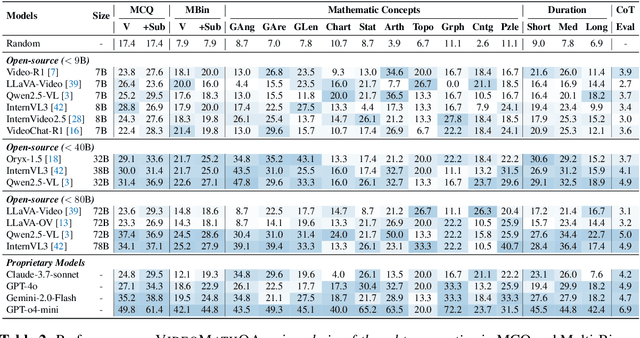
Mathematical reasoning in real-world video settings presents a fundamentally different challenge than in static images or text. It requires interpreting fine-grained visual information, accurately reading handwritten or digital text, and integrating spoken cues, often dispersed non-linearly over time. In such multimodal contexts, success hinges not just on perception, but on selectively identifying and integrating the right contextual details from a rich and noisy stream of content. To this end, we introduce VideoMathQA, a benchmark designed to evaluate whether models can perform such temporally extended cross-modal reasoning on videos. The benchmark spans 10 diverse mathematical domains, covering videos ranging from 10 seconds to over 1 hour. It requires models to interpret structured visual content, understand instructional narratives, and jointly ground concepts across visual, audio, and textual modalities. We employ graduate-level experts to ensure high quality, totaling over $920$ man-hours of annotation. To reflect real-world scenarios, questions are designed around three core reasoning challenges: direct problem solving, where answers are grounded in the presented question; conceptual transfer, which requires applying learned methods to new problems; and deep instructional comprehension, involving multi-step reasoning over extended explanations and partially worked-out solutions. Each question includes multi-step reasoning annotations, enabling fine-grained diagnosis of model capabilities. Through this benchmark, we highlight the limitations of existing approaches and establish a systematic evaluation framework for models that must reason, rather than merely perceive, across temporally extended and modality-rich mathematical problem settings. Our benchmark and evaluation code are available at: https://mbzuai-oryx.github.io/VideoMathQA
How Good is my Histopathology Vision-Language Foundation Model? A Holistic Benchmark
Mar 17, 2025



Recently, histopathology vision-language foundation models (VLMs) have gained popularity due to their enhanced performance and generalizability across different downstream tasks. However, most existing histopathology benchmarks are either unimodal or limited in terms of diversity of clinical tasks, organs, and acquisition instruments, as well as their partial availability to the public due to patient data privacy. As a consequence, there is a lack of comprehensive evaluation of existing histopathology VLMs on a unified benchmark setting that better reflects a wide range of clinical scenarios. To address this gap, we introduce HistoVL, a fully open-source comprehensive benchmark comprising images acquired using up to 11 various acquisition tools that are paired with specifically crafted captions by incorporating class names and diverse pathology descriptions. Our Histo-VL includes 26 organs, 31 cancer types, and a wide variety of tissue obtained from 14 heterogeneous patient cohorts, totaling more than 5 million patches obtained from over 41K WSIs viewed under various magnification levels. We systematically evaluate existing histopathology VLMs on Histo-VL to simulate diverse tasks performed by experts in real-world clinical scenarios. Our analysis reveals interesting findings, including large sensitivity of most existing histopathology VLMs to textual changes with a drop in balanced accuracy of up to 25% in tasks such as Metastasis detection, low robustness to adversarial attacks, as well as improper calibration of models evident through high ECE values and low model prediction confidence, all of which can affect their clinical implementation.
LLMVoX: Autoregressive Streaming Text-to-Speech Model for Any LLM
Mar 06, 2025Recent advancements in speech-to-speech dialogue systems leverage LLMs for multimodal interactions, yet they remain hindered by fine-tuning requirements, high computational overhead, and text-speech misalignment. Existing speech-enabled LLMs often degrade conversational quality by modifying the LLM, thereby compromising its linguistic capabilities. In contrast, we propose LLMVoX, a lightweight 30M-parameter, LLM-agnostic, autoregressive streaming TTS system that generates high-quality speech with low latency, while fully preserving the capabilities of the base LLM. Our approach achieves a significantly lower Word Error Rate compared to speech-enabled LLMs, while operating at comparable latency and UTMOS score. By decoupling speech synthesis from LLM processing via a multi-queue token streaming system, LLMVoX supports seamless, infinite-length dialogues. Its plug-and-play design also facilitates extension to various tasks with different backbones. Furthermore, LLMVoX generalizes to new languages with only dataset adaptation, attaining a low Character Error Rate on an Arabic speech task. Additionally, we have integrated LLMVoX with a Vision-Language Model to create an omni-model with speech, text, and vision capabilities, without requiring additional multimodal training. Our code base and project page is available at https://mbzuai-oryx.github.io/LLMVoX .
KITAB-Bench: A Comprehensive Multi-Domain Benchmark for Arabic OCR and Document Understanding
Feb 20, 2025



With the growing adoption of Retrieval-Augmented Generation (RAG) in document processing, robust text recognition has become increasingly critical for knowledge extraction. While OCR (Optical Character Recognition) for English and other languages benefits from large datasets and well-established benchmarks, Arabic OCR faces unique challenges due to its cursive script, right-to-left text flow, and complex typographic and calligraphic features. We present KITAB-Bench, a comprehensive Arabic OCR benchmark that fills the gaps in current evaluation systems. Our benchmark comprises 8,809 samples across 9 major domains and 36 sub-domains, encompassing diverse document types including handwritten text, structured tables, and specialized coverage of 21 chart types for business intelligence. Our findings show that modern vision-language models (such as GPT-4, Gemini, and Qwen) outperform traditional OCR approaches (like EasyOCR, PaddleOCR, and Surya) by an average of 60% in Character Error Rate (CER). Furthermore, we highlight significant limitations of current Arabic OCR models, particularly in PDF-to-Markdown conversion, where the best model Gemini-2.0-Flash achieves only 65% accuracy. This underscores the challenges in accurately recognizing Arabic text, including issues with complex fonts, numeral recognition errors, word elongation, and table structure detection. This work establishes a rigorous evaluation framework that can drive improvements in Arabic document analysis methods and bridge the performance gap with English OCR technologies.
Robust-LLaVA: On the Effectiveness of Large-Scale Robust Image Encoders for Multi-modal Large Language Models
Feb 03, 2025



Multi-modal Large Language Models (MLLMs) excel in vision-language tasks but remain vulnerable to visual adversarial perturbations that can induce hallucinations, manipulate responses, or bypass safety mechanisms. Existing methods seek to mitigate these risks by applying constrained adversarial fine-tuning to CLIP vision encoders on ImageNet-scale data, ensuring their generalization ability is preserved. However, this limited adversarial training restricts robustness and broader generalization. In this work, we explore an alternative approach of leveraging existing vision classification models that have been adversarially pre-trained on large-scale data. Our analysis reveals two principal contributions: (1) the extensive scale and diversity of adversarial pre-training enables these models to demonstrate superior robustness against diverse adversarial threats, ranging from imperceptible perturbations to advanced jailbreaking attempts, without requiring additional adversarial training, and (2) end-to-end MLLM integration with these robust models facilitates enhanced adaptation of language components to robust visual features, outperforming existing plug-and-play methodologies on complex reasoning tasks. Through systematic evaluation across visual question-answering, image captioning, and jail-break attacks, we demonstrate that MLLMs trained with these robust models achieve superior adversarial robustness while maintaining favorable clean performance. Our framework achieves 2x and 1.5x average robustness gains in captioning and VQA tasks, respectively, and delivers over 10% improvement against jailbreak attacks. Code and pretrained models will be available at https://github.com/HashmatShadab/Robust-LLaVA.
BiMediX2: Bio-Medical EXpert LMM for Diverse Medical Modalities
Dec 10, 2024



This paper introduces BiMediX2, a bilingual (Arabic-English) Bio-Medical EXpert Large Multimodal Model (LMM) with a unified architecture that integrates text and visual modalities, enabling advanced image understanding and medical applications. BiMediX2 leverages the Llama3.1 architecture and integrates text and visual capabilities to facilitate seamless interactions in both English and Arabic, supporting text-based inputs and multi-turn conversations involving medical images. The model is trained on an extensive bilingual healthcare dataset consisting of 1.6M samples of diverse medical interactions for both text and image modalities, mixed in Arabic and English. We also propose the first bilingual GPT-4o based medical LMM benchmark named BiMed-MBench. BiMediX2 is benchmarked on both text-based and image-based tasks, achieving state-of-the-art performance across several medical benchmarks. It outperforms recent state-of-the-art models in medical LLM evaluation benchmarks. Our model also sets a new benchmark in multimodal medical evaluations with over 9% improvement in English and over 20% in Arabic evaluations. Additionally, it surpasses GPT-4 by around 9% in UPHILL factual accuracy evaluations and excels in various medical Visual Question Answering, Report Generation, and Report Summarization tasks. The project page including source code and the trained model, is available at https://github.com/mbzuai-oryx/BiMediX2.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.