 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Is All You Need for KV Cache in Diffusion LLMs
Oct 16, 2025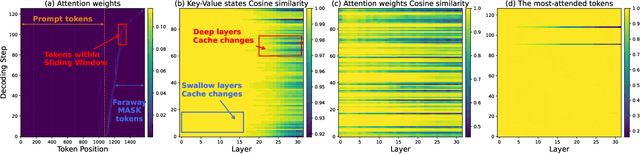
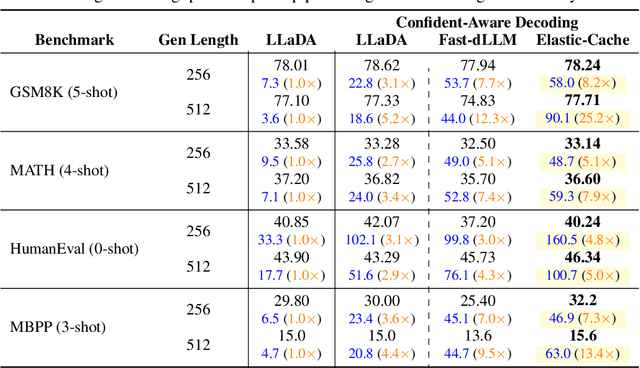
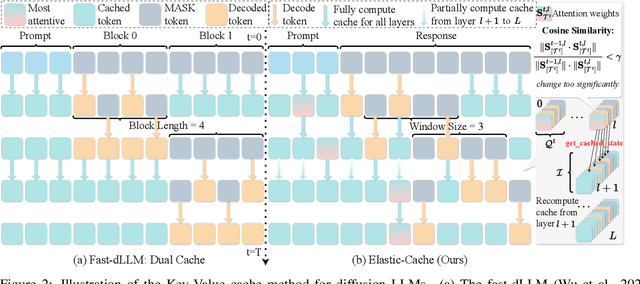
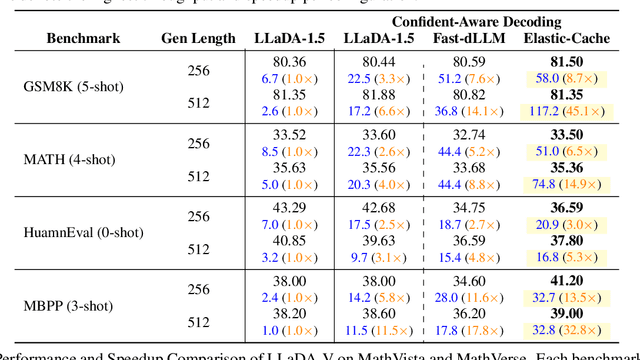
This work studies how to adaptively recompute key-value (KV) caches for diffusion large language models (DLMs) to maximize prediction accuracy while minimizing decoding latency. Prior methods' decoders recompute QKV for all tokens at every denoising step and layer, despite KV states changing little across most steps, especially in shallow layers, leading to substantial redundancy. We make three observations: (1) distant ${\bf MASK}$ tokens primarily act as a length-bias and can be cached block-wise beyond the active prediction window; (2) KV dynamics increase with depth, suggesting that selective refresh starting from deeper layers is sufficient; and (3) the most-attended token exhibits the smallest KV drift, providing a conservative lower bound on cache change for other tokens. Building on these, we propose ${\bf Elastic-Cache}$, a training-free, architecture-agnostic strategy that jointly decides ${when}$ to refresh (via an attention-aware drift test on the most-attended token) and ${where}$ to refresh (via a depth-aware schedule that recomputes from a chosen layer onward while reusing shallow-layer caches and off-window MASK caches). Unlike fixed-period schemes, Elastic-Cache performs adaptive, layer-aware cache updates for diffusion LLMs, reducing redundant computation and accelerating decoding with negligible loss in generation quality. Experiments on LLaDA-Instruct, LLaDA-1.5, and LLaDA-V across mathematical reasoning and code generation tasks demonstrate consistent speedups: $8.7\times$ on GSM8K (256 tokens), $45.1\times$ on longer sequences, and $4.8\times$ on HumanEval, while consistently maintaining higher accuracy than the baseline. Our method achieves significantly higher throughput ($6.8\times$ on GSM8K) than existing confidence-based approaches while preserving generation quality, enabling practical deployment of diffusion LLMs.
Time Blindness: Why Video-Language Models Can't See What Humans Can?
May 30, 2025Recent advances in vision-language models (VLMs) have made impressive strides in understanding spatio-temporal relationships in videos. However, when spatial information is obscured, these models struggle to capture purely temporal patterns. We introduce $\textbf{SpookyBench}$, a benchmark where information is encoded solely in temporal sequences of noise-like frames, mirroring natural phenomena from biological signaling to covert communication. Interestingly, while humans can recognize shapes, text, and patterns in these sequences with over 98% accuracy, state-of-the-art VLMs achieve 0% accuracy. This performance gap highlights a critical limitation: an over-reliance on frame-level spatial features and an inability to extract meaning from temporal cues. Furthermore, when trained in data sets with low spatial signal-to-noise ratios (SNR), temporal understanding of models degrades more rapidly than human perception, especially in tasks requiring fine-grained temporal reasoning. Overcoming this limitation will require novel architectures or training paradigms that decouple spatial dependencies from temporal processing. Our systematic analysis shows that this issue persists across model scales and architectures. We release SpookyBench to catalyze research in temporal pattern recognition and bridge the gap between human and machine video understanding. Dataset and code has been made available on our project website: https://timeblindness.github.io/.
Mobile-MMLU: A Mobile Intelligence Language Understanding Benchmark
Mar 26, 2025

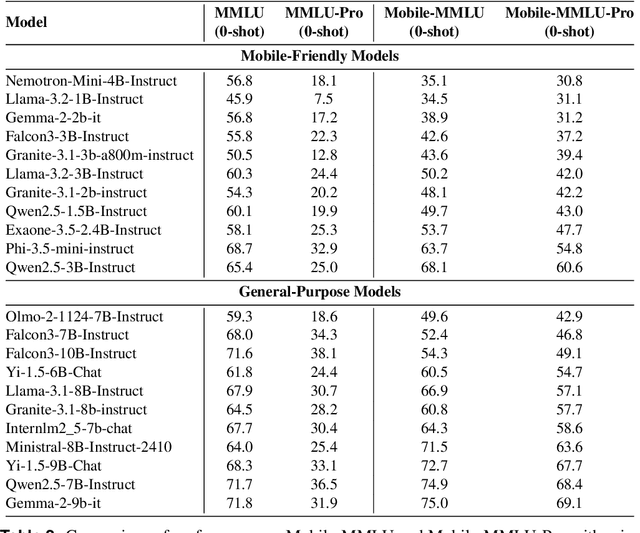
Rapid advancements in large language models (LLMs) have increased interest in deploying them on mobile devices for on-device AI applications. Mobile users interact differently with LLMs compared to desktop users, creating unique expectations and data biases. Current benchmark datasets primarily target at server and desktop environments, and there is a notable lack of extensive datasets specifically designed for mobile contexts. Additionally, mobile devices face strict limitations in storage and computing resources, constraining model size and capabilities, thus requiring optimized efficiency and prioritized knowledge. To address these challenges, we introduce Mobile-MMLU, a large-scale benchmark dataset tailored for mobile intelligence. It consists of 16,186 questions across 80 mobile-related fields, designed to evaluate LLM performance in realistic mobile scenarios. A challenging subset, Mobile-MMLU-Pro, provides advanced evaluation similar in size to MMLU-Pro but significantly more difficult than our standard full set. Both benchmarks use multiple-choice, order-invariant questions focused on practical mobile interactions, such as recipe suggestions, travel planning, and essential daily tasks. The dataset emphasizes critical mobile-specific metrics like inference latency, energy consumption, memory usage, and response quality, offering comprehensive insights into model performance under mobile constraints. Moreover, it prioritizes privacy and adaptability, assessing models' ability to perform on-device processing, maintain user privacy, and adapt to personalized usage patterns. Mobile-MMLU family offers a standardized framework for developing and comparing mobile-optimized LLMs, enabling advancements in productivity and decision-making within mobile computing environments. Our code and data are available at: https://github.com/VILA-Lab/Mobile-MMLU.
KITAB-Bench: A Comprehensive Multi-Domain Benchmark for Arabic OCR and Document Understanding
Feb 20, 2025



With the growing adoption of Retrieval-Augmented Generation (RAG) in document processing, robust text recognition has become increasingly critical for knowledge extraction. While OCR (Optical Character Recognition) for English and other languages benefits from large datasets and well-established benchmarks, Arabic OCR faces unique challenges due to its cursive script, right-to-left text flow, and complex typographic and calligraphic features. We present KITAB-Bench, a comprehensive Arabic OCR benchmark that fills the gaps in current evaluation systems. Our benchmark comprises 8,809 samples across 9 major domains and 36 sub-domains, encompassing diverse document types including handwritten text, structured tables, and specialized coverage of 21 chart types for business intelligence. Our findings show that modern vision-language models (such as GPT-4, Gemini, and Qwen) outperform traditional OCR approaches (like EasyOCR, PaddleOCR, and Surya) by an average of 60% in Character Error Rate (CER). Furthermore, we highlight significant limitations of current Arabic OCR models, particularly in PDF-to-Markdown conversion, where the best model Gemini-2.0-Flash achieves only 65% accuracy. This underscores the challenges in accurately recognizing Arabic text, including issues with complex fonts, numeral recognition errors, word elongation, and table structure detection. This work establishes a rigorous evaluation framework that can drive improvements in Arabic document analysis methods and bridge the performance gap with English OCR technologies.
An evaluation of Google Translate for Sanskrit to English translation via sentiment and semantic analysis
Feb 28, 2023



Google Translate has been prominent for language translation; however, limited work has been done in evaluating the quality of translation when compared to human experts. Sanskrit one of the oldest written languages in the world. In 2022, the Sanskrit language was added to the Google Translate engine. Sanskrit is known as the mother of languages such as Hindi and an ancient source of the Indo-European group of languages. Sanskrit is the original language for sacred Hindu texts such as the Bhagavad Gita. In this study, we present a framework that evaluates the Google Translate for Sanskrit using the Bhagavad Gita. We first publish a translation of the Bhagavad Gita in Sanskrit using Google Translate. Our framework then compares Google Translate version of Bhagavad Gita with expert translations using sentiment and semantic analysis via BERT-based language models. Our results indicate that in terms of sentiment and semantic analysis, there is low level of similarity in selected verses of Google Translate when compared to expert translations. In the qualitative evaluation, we find that Google translate is unsuitable for translation of certain Sanskrit words and phrases due to its poetic nature, contextual significance, metaphor and imagery. The mistranslations are not surprising since the Bhagavad Gita is known as a difficult text not only to translate, but also to interpret since it relies on contextual, philosophical and historical information. Our framework lays the foundation for automatic evaluation of other languages by Google Translate
Artificial intelligence for topic modelling in Hindu philosophy: mapping themes between the Upanishads and the Bhagavad Gita
May 23, 2022
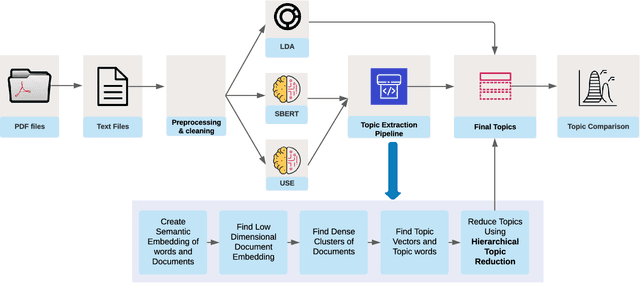

A distinct feature of Hindu religious and philosophical text is that they come from a library of texts rather than single source. The Upanishads is known as one of the oldest philosophical texts in the world that forms the foundation of Hindu philosophy. The Bhagavad Gita is core text of Hindu philosophy and is known as a text that summarises the key philosophies of the Upanishads with major focus on the philosophy of karma. These texts have been translated into many languages and there exists studies about themes and topics that are prominent; however, there is not much study of topic modelling using language models which are powered by deep learning. In this paper, we use advanced language produces such as BERT to provide topic modelling of the key texts of the Upanishads and the Bhagavad Gita. We analyse the distinct and overlapping topics amongst the texts and visualise the link of selected texts of the Upanishads with Bhagavad Gita. Our results show a very high similarity between the topics of these two texts with the mean cosine similarity of 73%. We find that out of the fourteen topics extracted from the Bhagavad Gita, nine of them have a cosine similarity of more than 70% with the topics of the Upanishads. We also found that topics generated by the BERT-based models show very high coherence as compared to that of conventional models. Our best performing model gives a coherence score of 73% on the Bhagavad Gita and 69% on The Upanishads. The visualization of the low dimensional embeddings of these texts shows very clear overlapping among their topics adding another level of validation to our results.
Deep-ASPECTS: A Segmentation-Assisted Model for Stroke Severity Measurement
Mar 17, 2022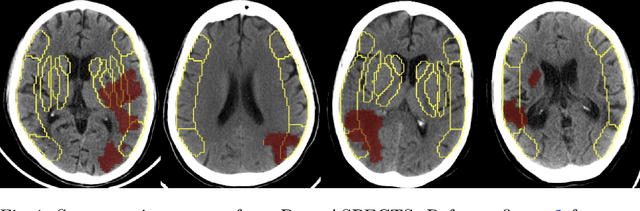
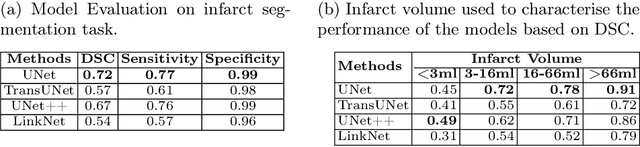
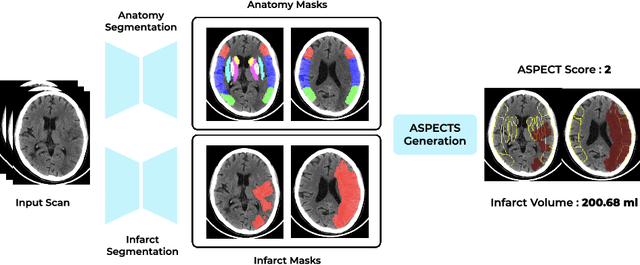

A stroke occurs when an artery in the brain ruptures and bleeds or when the blood supply to the brain is cut off. Blood and oxygen cannot reach the brain's tissues due to the rupture or obstruction resulting in tissue death. The Middle cerebral artery (MCA) is the largest cerebral artery and the most commonly damaged vessel in stroke. The quick onset of a focused neurological deficit caused by interruption of blood flow in the territory supplied by the MCA is known as an MCA stroke. Alberta stroke programme early CT score (ASPECTS) is used to estimate the extent of early ischemic changes in patients with MCA stroke. This study proposes a deep learning-based method to score the CT scan for ASPECTS. Our work has three highlights. First, we propose a novel method for medical image segmentation for stroke detection. Second, we show the effectiveness of AI solution for fully-automated ASPECT scoring with reduced diagnosis time for a given non-contrast CT (NCCT) Scan. Our algorithms show a dice similarity coefficient of 0.64 for the MCA anatomy segmentation and 0.72 for the infarcts segmentation. Lastly, we show that our model's performance is inline with inter-reader variability between radiologists.