 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIMER: Calibration-Free Task-Agnostic MoE Pruning
Mar 19, 2026Mixture-of-Experts (MoE) language models increase parameter capacity without proportional per-token compute, but the deployment still requires storing all experts, making expert pruning important for reducing memory and serving overhead. Existing task-agnostic expert pruning methods are typically calibration-dependent: they estimate expert importance from routing or activation statistics on a calibration set, which makes pruning outcomes sensitive to the choice of calibration set and adds substantial preprocessing cost. We introduce AIMER (\textbf{A}bsolute mean over root mean square \textbf{IM}portance for \textbf{E}xpert \textbf{R}anking), a simple calibration-free criterion that yields clear within-layer score separation and distinct expert stratification. Across 7B to 30B MoE language models at 25\% and 50\% pruning ratios over 16 benchmarks, AIMER consistently delivers competitive or stronger overall performance against state-of-the-art calibration-based expert pruning baselines with only 0.22--1.27 seconds for scoring the experts.
BiGain: Unified Token Compression for Joint Generation and Classification
Mar 12, 2026Acceleration methods for diffusion models (e.g., token merging or downsampling) typically optimize synthesis quality under reduced compute, yet often ignore discriminative capacity. We revisit token compression with a joint objective and present BiGain, a training-free, plug-and-play framework that preserves generation quality while improving classification in accelerated diffusion models. Our key insight is frequency separation: mapping feature-space signals into a frequency-aware representation disentangles fine detail from global semantics, enabling compression that respects both generative fidelity and discriminative utility. BiGain reflects this principle with two frequency-aware operators: (1) Laplacian-gated token merging, which encourages merges among spectrally smooth tokens while discouraging merges of high-contrast tokens, thereby retaining edges and textures; and (2) Interpolate-Extrapolate KV Downsampling, which downsamples keys/values via a controllable interextrapolation between nearest and average pooling while keeping queries intact, thereby conserving attention precision. Across DiT- and U-Net-based backbones and ImageNet-1K, ImageNet-100, Oxford-IIIT Pets, and COCO-2017, our operators consistently improve the speed-accuracy trade-off for diffusion-based classification, while maintaining or enhancing generation quality under comparable acceleration. For instance, on ImageNet-1K, with 70% token merging on Stable Diffusion 2.0, BiGain increases classification accuracy by 7.15% while improving FID by 0.34 (1.85%). Our analyses indicate that balanced spectral retention, preserving high-frequency detail and low/mid-frequency semantics, is a reliable design rule for token compression in diffusion models. To our knowledge, BiGain is the first framework to jointly study and advance both generation and classification under accelerated diffusion, supporting lower-cost deployment.
Diff-ES: Stage-wise Structural Diffusion Pruning via Evolutionary Search
Mar 05, 2026Diffusion models have achieved remarkable success in high-fidelity image generation but remain computationally demanding due to their multi-step denoising process and large model sizes. Although prior work improves efficiency either by reducing sampling steps or by compressing model parameters, existing structured pruning approaches still struggle to balance real acceleration and image quality preservation. In particular, prior methods such as MosaicDiff rely on heuristic, manually tuned stage-wise sparsity schedules and stitch multiple independently pruned models during inference, which increases memory overhead. However, the importance of diffusion steps is highly non-uniform and model-dependent. As a result, schedules derived from simple heuristics or empirical observations often fail to generalize and may lead to suboptimal performance. To this end, we introduce \textbf{Diff-ES}, a stage-wise structural \textbf{Diff}usion pruning framework via \textbf{E}volutionary \textbf{S}earch, which optimizes the stage-wise sparsity schedule and executes it through memory-efficient weight routing without model duplication. Diff-ES divides the diffusion trajectory into multiple stages, automatically discovers an optimal stage-wise sparsity schedule via evolutionary search, and activates stage-conditioned weights dynamically without duplicating model parameters. Our framework naturally integrates with existing structured pruning methods for diffusion models including depth and width pruning. Extensive experiments on DiT and SDXL demonstrate that Diff-ES consistently achieves wall-clock speedups while incurring minimal degradation in generation quality, establishing state-of-the-art performance for structured diffusion model pruning.
Sink-Aware Pruning for Diffusion Language Models
Feb 19, 2026Diffusion Language Models (DLMs) incur high inference cost due to iterative denoising, motivating efficient pruning. Existing pruning heuristics largely inherited from autoregressive (AR) LLMs, typically preserve attention sink tokens because AR sinks serve as stable global anchors. We show that this assumption does not hold for DLMs: the attention-sink position exhibits substantially higher variance over the full generation trajectory (measured by how the dominant sink locations shift across timesteps), indicating that sinks are often transient and less structurally essential than in AR models. Based on this observation, we propose ${\bf \texttt{Sink-Aware Pruning}}$, which automatically identifies and prunes unstable sinks in DLMs (prior studies usually keep sinks for AR LLMs). Without retraining, our method achieves a better quality-efficiency trade-off and outperforms strong prior pruning baselines under matched compute. Our code is available at https://github.com/VILA-Lab/Sink-Aware-Pruning.
Canzona: A Unified, Asynchronous, and Load-Balanced Framework for Distributed Matrix-based Optimizers
Feb 04, 2026The scaling of Large Language Models (LLMs) drives interest in matrix-based optimizers (e.g., Shampoo, Muon, SOAP) for their convergence efficiency; yet their requirement for holistic updates conflicts with the tensor fragmentation in distributed frameworks like Megatron. Existing solutions are suboptimal: synchronous approaches suffer from computational redundancy, while layer-wise partitioning fails to reconcile this conflict without violating the geometric constraints of efficient communication primitives. To bridge this gap, we propose Canzona, a Unified, Asynchronous, and Load-Balanced framework that decouples logical optimizer assignment from physical parameter distribution. For Data Parallelism, we introduce an alpha-Balanced Static Partitioning strategy that respects atomicity while neutralizing the load imbalance. For Tensor Parallelism, we design an Asynchronous Compute pipeline utilizing Micro-Group Scheduling to batch fragmented updates and hide reconstruction overhead. Extensive evaluations on the Qwen3 model family (up to 32B parameters) on 256 GPUs demonstrate that our approach preserves the efficiency of established parallel architectures, achieving a 1.57x speedup in end-to-end iteration time and reducing optimizer step latency by 5.8x compared to the baseline.
Mobile-MMLU: A Mobile Intelligence Language Understanding Benchmark
Mar 26, 2025
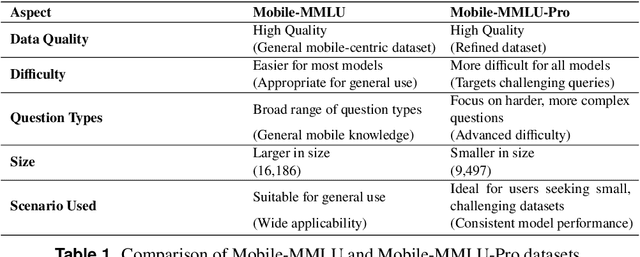

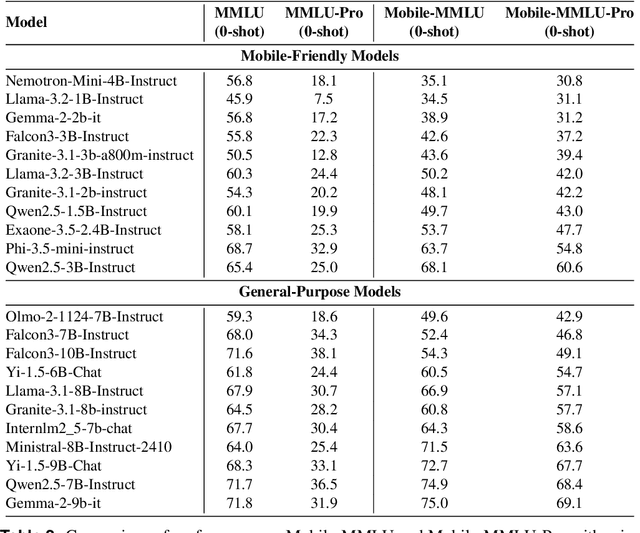
Rapid advancements in large language models (LLMs) have increased interest in deploying them on mobile devices for on-device AI applications. Mobile users interact differently with LLMs compared to desktop users, creating unique expectations and data biases. Current benchmark datasets primarily target at server and desktop environments, and there is a notable lack of extensive datasets specifically designed for mobile contexts. Additionally, mobile devices face strict limitations in storage and computing resources, constraining model size and capabilities, thus requiring optimized efficiency and prioritized knowledge. To address these challenges, we introduce Mobile-MMLU, a large-scale benchmark dataset tailored for mobile intelligence. It consists of 16,186 questions across 80 mobile-related fields, designed to evaluate LLM performance in realistic mobile scenarios. A challenging subset, Mobile-MMLU-Pro, provides advanced evaluation similar in size to MMLU-Pro but significantly more difficult than our standard full set. Both benchmarks use multiple-choice, order-invariant questions focused on practical mobile interactions, such as recipe suggestions, travel planning, and essential daily tasks. The dataset emphasizes critical mobile-specific metrics like inference latency, energy consumption, memory usage, and response quality, offering comprehensive insights into model performance under mobile constraints. Moreover, it prioritizes privacy and adaptability, assessing models' ability to perform on-device processing, maintain user privacy, and adapt to personalized usage patterns. Mobile-MMLU family offers a standardized framework for developing and comparing mobile-optimized LLMs, enabling advancements in productivity and decision-making within mobile computing environments. Our code and data are available at: https://github.com/VILA-Lab/Mobile-MMLU.
DarwinLM: Evolutionary Structured Pruning of Large Language Models
Feb 11, 2025



Large Language Models (LLMs) have achieved significant success across various NLP tasks. However, their massive computational costs limit their widespread use, particularly in real-time applications. Structured pruning offers an effective solution by compressing models and directly providing end-to-end speed improvements, regardless of the hardware environment. Meanwhile, different components of the model exhibit varying sensitivities towards pruning, calling for \emph{non-uniform} model compression. However, a pruning method should not only identify a capable substructure, but also account for post-compression training. To this end, we propose \sysname, a method for \emph{training-aware} structured pruning. \sysname builds upon an evolutionary search process, generating multiple offspring models in each generation through mutation, and selecting the fittest for survival. To assess the effect of post-training, we incorporate a lightweight, multistep training process within the offspring population, progressively increasing the number of tokens and eliminating poorly performing models in each selection stage. We validate our method through extensive experiments on Llama-2-7B, Llama-3.1-8B and Qwen-2.5-14B-Instruct, achieving state-of-the-art performance for structured pruning. For instance, \sysname surpasses ShearedLlama while requiring $5\times$ less training data during post-compression training.
Bi-Mamba: Towards Accurate 1-Bit State Space Models
Nov 18, 2024The typical selective state-space model (SSM) of Mamba addresses several limitations of Transformers, such as quadratic computational complexity with sequence length and significant inference-time memory requirements due to the key-value cache. However, the growing size of Mamba models continues to pose training and deployment challenges and raises environmental concerns due to considerable energy consumption. In this work, we introduce Bi-Mamba, a scalable and powerful 1-bit Mamba architecture designed for more efficient large language models with multiple sizes across 780M, 1.3B, and 2.7B. Bi-Mamba models are trained from scratch on data volume as regular LLM pertaining using an autoregressive distillation loss. Extensive experimental results on language modeling demonstrate that Bi-Mamba achieves performance comparable to its full-precision counterparts (e.g., FP16 or BF16) and much better accuracy than post-training-binarization (PTB) Mamba baselines, while significantly reducing memory footprint and energy consumption compared to the original Mamba model. Our study pioneers a new linear computational complexity LLM framework under low-bit representation and facilitates the future design of specialized hardware tailored for efficient 1-bit Mamba-based LLMs.
Improving Logits-based Detector without Logits from Black-box LLMs
Jun 11, 2024



The advent of Large Language Models (LLMs) has revolutionized text generation, producing outputs that closely mimic human writing. This blurring of lines between machine- and human-written text presents new challenges in distinguishing one from the other a task further complicated by the frequent updates and closed nature of leading proprietary LLMs. Traditional logits-based detection methods leverage surrogate models for identifying LLM-generated content when the exact logits are unavailable from black-box LLMs. However, these methods grapple with the misalignment between the distributions of the surrogate and the often undisclosed target models, leading to performance degradation, particularly with the introduction of new, closed-source models. Furthermore, while current methodologies are generally effective when the source model is identified, they falter in scenarios where the model version remains unknown, or the test set comprises outputs from various source models. To address these limitations, we present Distribution-Aligned LLMs Detection (DALD), an innovative framework that redefines the state-of-the-art performance in black-box text detection even without logits from source LLMs. DALD is designed to align the surrogate model's distribution with that of unknown target LLMs, ensuring enhanced detection capability and resilience against rapid model iterations with minimal training investment. By leveraging corpus samples from publicly accessible outputs of advanced models such as ChatGPT, GPT-4 and Claude-3, DALD fine-tunes surrogate models to synchronize with unknown source model distributions effectively.
DeeDiff: Dynamic Uncertainty-Aware Early Exiting for Accelerating Diffusion Model Generation
Sep 29, 2023Diffusion models achieve great success in generating diverse and high-fidelity images. The performance improvements come with low generation speed per image, which hinders the application diffusion models in real-time scenarios. While some certain predictions benefit from the full computation of the model in each sample iteration, not every iteration requires the same amount of computation, potentially leading to computation waste. In this work, we propose DeeDiff, an early exiting framework that adaptively allocates computation resources in each sampling step to improve the generation efficiency of diffusion models. Specifically, we introduce a timestep-aware uncertainty estimation module (UEM) for diffusion models which is attached to each intermediate layer to estimate the prediction uncertainty of each layer. The uncertainty is regarded as the signal to decide if the inference terminates. Moreover, we propose uncertainty-aware layer-wise loss to fill the performance gap between full models and early-exited models. With such loss strategy, our model is able to obtain comparable results as full-layer models. Extensive experiments of class-conditional, unconditional, and text-guided generation on several datasets show that our method achieves state-of-the-art performance and efficiency trade-off compared with existing early exiting methods on diffusion models. More importantly, our method even brings extra benefits to baseline models and obtains better performance on CIFAR-10 and Celeb-A datasets. Full code and model are released for reproduction.