 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIF: A Conditional Multimodal Generative Framework for IR Drop Imaging in Chip Layouts
Apr 11, 2026IR drop analysis is essential in physical chip design to ensure the power integrity of on-chip power delivery networks. Traditional Electronic Design Automation (EDA) tools have become slow and expensive as transistor density scales. Recent works have introduced machine learning (ML)-based methods that formulate IR drop analysis as an image prediction problem. These existing ML approaches fail to capture both local and long-range dependencies and ignore crucial geometrical and topological information from physical layouts and logical connectivity. To address these limitations, we propose GIF, a Generative IR drop Framework that uses both geometrical and topological information to generate IR drop images. GIF fuses image and graph features to guide a conditional diffusion process, producing high-quality IR drop images. For instance, On the CircuitNet-N28 dataset, GIF achieves 0.78 SSIM, 0.95 Pearson correlation, 21.77 PSNR, and 0.026 NMAE, outperforming prior methods. These results demonstrate that our framework, using diffusion based multimodal conditioning, reliably generates high quality IR drop images. This shows that IR drop analysis can effectively leverage recent advances in generative modeling when geometric layout features and logical circuit topology are jointly modeled. By combining geometry aware spatial features with logical graph representations, GIF enables IR drop analysis to benefit from recent advances in generative modeling for structured image generation.
GSR-GNN: Training Acceleration and Memory-Saving Framework of Deep GNNs on Circuit Graph
Mar 28, 2026Graph Neural Networks (GNNs) show strong promise for circuit analysis, but scaling to modern large-scale circuit graphs is limited by GPU memory and training cost, especially for deep models. We revisit deep GNNs for circuit graphs and show that, when trainable, they significantly outperform shallow architectures, motivating an efficient, domain-specific training framework. We propose Grouped-Sparse-Reversible GNN (GSR-GNN), which enables training GNNs with up to hundreds of layers while reducing both compute and memory overhead. GSR-GNN integrates reversible residual modules with a group-wise sparse nonlinear operator that compresses node embeddings without sacrificing task-relevant information, and employs an optimized execution pipeline to eliminate fragmented activation storage and reduce data movement. On sampled circuit graphs, GSR-GNN achieves up to 87.2\% peak memory reduction and over 30$\times$ training speedup with negligible degradation in correlation-based quality metrics, making deep GNNs practical for large-scale EDA workloads.
StitchCUDA: An Automated Multi-Agents End-to-End GPU Programing Framework with Rubric-based Agentic Reinforcement Learning
Mar 03, 2026Modern machine learning (ML) workloads increasingly rely on GPUs, yet achieving high end-to-end performance remains challenging due to dependencies on both GPU kernel efficiency and host-side settings. Although LLM-based methods show promise on automated GPU kernel generation, prior works mainly focus on single-kernel optimization and do not extend to end-to-end programs, hindering practical deployment. To address the challenge, in this work, we propose StitchCUDA, a multi-agent framework for end-to-end GPU program generation, with three specialized agents: a Planner to orchestrate whole system design, a Coder dedicated to implementing it step-by-step, and a Verifier for correctness check and performance profiling using Nsys/NCU. To fundamentally improve the Coder's ability in end-to-end GPU programming, StitchCUDA integrates rubric-based agentic reinforcement learning over two atomic skills, task-to-code generation and feedback-driven code optimization, with combined rubric reward and rule-based reward from real executions. Therefore, the Coder learns how to implement advanced CUDA programming techniques (e.g., custom kernel fusion, cublas epilogue), and we also effectively prevent Coder's reward hacking (e.g., just copy PyTorch code or hardcoding output) during benchmarking. Experiments on KernelBench show that StitchCUDA achieves nearly 100% success rate on end-to-end GPU programming tasks, with 1.72x better speedup over the multi-agent baseline and 2.73x than the RL model baselines.
HDLxGraph: Bridging Large Language Models and HDL Repositories via HDL Graph Databases
May 21, 2025Large Language Models (LLMs) have demonstrated their potential in hardware design tasks, such as Hardware Description Language (HDL) generation and debugging. Yet, their performance in real-world, repository-level HDL projects with thousands or even tens of thousands of code lines is hindered. To this end, we propose HDLxGraph, a novel framework that integrates Graph Retrieval Augmented Generation (Graph RAG) with LLMs, introducing HDL-specific graph representations by incorporating Abstract Syntax Trees (ASTs) and Data Flow Graphs (DFGs) to capture both code graph view and hardware graph view. HDLxGraph utilizes a dual-retrieval mechanism that not only mitigates the limited recall issues inherent in similarity-based semantic retrieval by incorporating structural information, but also enhances its extensibility to various real-world tasks by a task-specific retrieval finetuning. Additionally, to address the lack of comprehensive HDL search benchmarks, we introduce HDLSearch, a multi-granularity evaluation dataset derived from real-world repository-level projects. Experimental results demonstrate that HDLxGraph significantly improves average search accuracy, debugging efficiency and completion quality by 12.04%, 12.22% and 5.04% compared to similarity-based RAG, respectively. The code of HDLxGraph and collected HDLSearch benchmark are available at https://github.com/Nick-Zheng-Q/HDLxGraph.
InfantAgent-Next: A Multimodal Generalist Agent for Automated Computer Interaction
May 16, 2025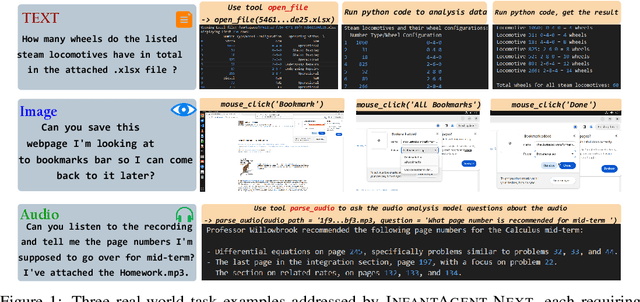

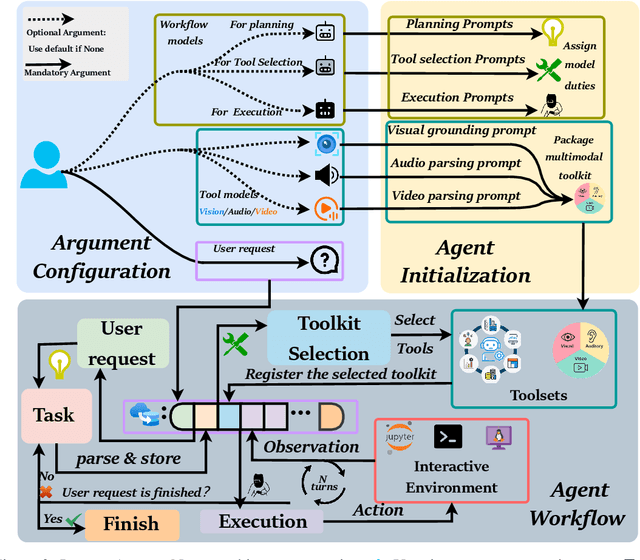
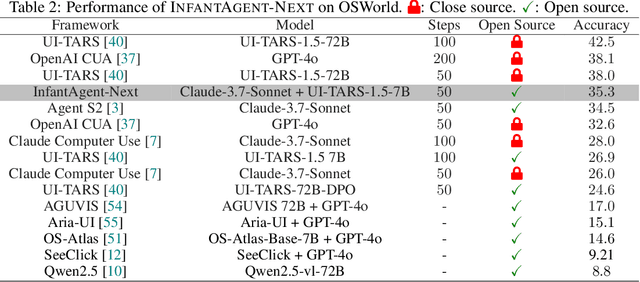
This paper introduces \textsc{InfantAgent-Next}, a generalist agent capable of interacting with computers in a multimodal manner, encompassing text, images, audio, and video. Unlike existing approaches that either build intricate workflows around a single large model or only provide workflow modularity, our agent integrates tool-based and pure vision agents within a highly modular architecture, enabling different models to collaboratively solve decoupled tasks in a step-by-step manner. Our generality is demonstrated by our ability to evaluate not only pure vision-based real-world benchmarks (i.e., OSWorld), but also more general or tool-intensive benchmarks (e.g., GAIA and SWE-Bench). Specifically, we achieve $\mathbf{7.27\%}$ accuracy on OSWorld, higher than Claude-Computer-Use. Codes and evaluation scripts are open-sourced at https://github.com/bin123apple/InfantAgent.
RankFlow: A Multi-Role Collaborative Reranking Workflow Utilizing Large Language Models
Feb 04, 2025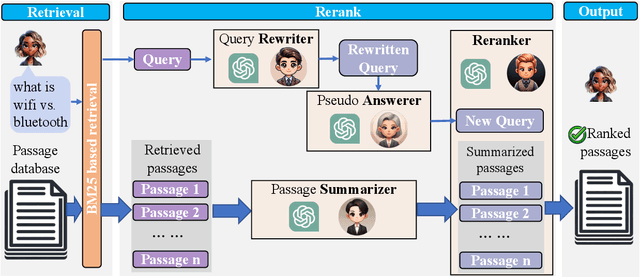
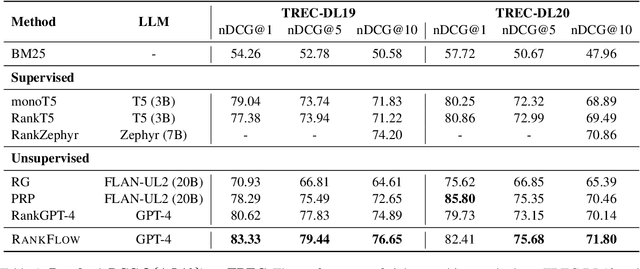
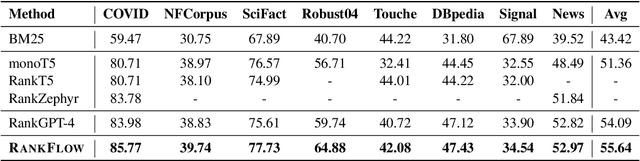
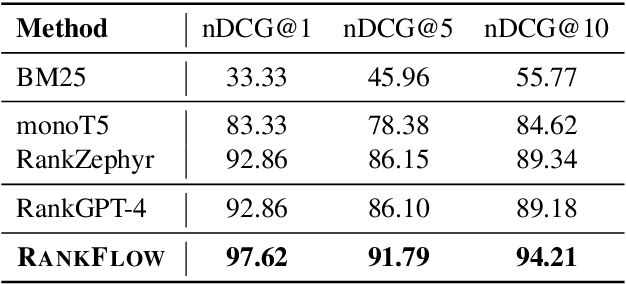
In an Information Retrieval (IR) system, reranking plays a critical role by sorting candidate passages according to their relevance to a specific query. This process demands a nuanced understanding of the variations among passages linked to the query. In this work, we introduce RankFlow, a multi-role reranking workflow that leverages the capabilities of Large Language Models (LLMs) and role specializations to improve reranking performance. RankFlow enlists LLMs to fulfill four distinct roles: the query Rewriter, the pseudo Answerer, the passage Summarizer, and the Reranker. This orchestrated approach enables RankFlow to: (1) accurately interpret queries, (2) draw upon LLMs' extensive pre-existing knowledge, (3) distill passages into concise versions, and (4) assess passages in a comprehensive manner, resulting in notably better reranking results. Our experimental results reveal that RankFlow outperforms existing leading approaches on widely recognized IR benchmarks, such as TREC-DL, BEIR, and NovelEval. Additionally, we investigate the individual contributions of each role in RankFlow. Code is available at https://github.com/jincan333/RankFlow.
Fortran2CPP: Automating Fortran-to-C++ Migration using LLMs via Multi-Turn Dialogue and Dual-Agent Integration
Dec 27, 2024



Migrating Fortran code to C++ is a common task for many scientific computing teams, driven by the need to leverage modern programming paradigms, enhance cross-platform compatibility, and improve maintainability. Automating this translation process using large language models (LLMs) has shown promise, but the lack of high-quality, specialized datasets has hindered their effectiveness. In this paper, we address this challenge by introducing a novel multi-turn dialogue dataset, Fortran2CPP, specifically designed for Fortran-to-C++ code migration. Our dataset, significantly larger than existing alternatives, is generated using a unique LLM-driven, dual-agent pipeline incorporating iterative compilation, execution, and code repair to ensure high quality and functional correctness. To demonstrate the effectiveness of our dataset, we fine-tuned several open-weight LLMs on Fortran2CPP and evaluated their performance on two independent benchmarks. Fine-tuning on our dataset led to remarkable gains, with models achieving up to a 3.31x increase in CodeBLEU score and a 92\% improvement in compilation success rate. This highlights the dataset's ability to enhance both the syntactic accuracy and compilability of the translated C++ code. Our dataset and model have been open-sourced and are available on our public GitHub repository\footnote{\url{https://github.com/HPC-Fortran2CPP/Fortran2Cpp}}.
HiVeGen -- Hierarchical LLM-based Verilog Generation for Scalable Chip Design
Dec 06, 2024



With Large Language Models (LLMs) recently demonstrating impressive proficiency in code generation, it is promising to extend their abilities to Hardware Description Language (HDL). However, LLMs tend to generate single HDL code blocks rather than hierarchical structures for hardware designs, leading to hallucinations, particularly in complex designs like Domain-Specific Accelerators (DSAs). To address this, we propose HiVeGen, a hierarchical LLM-based Verilog generation framework that decomposes generation tasks into LLM-manageable hierarchical submodules. HiVeGen further harnesses the advantages of such hierarchical structures by integrating automatic Design Space Exploration (DSE) into hierarchy-aware prompt generation, introducing weight-based retrieval to enhance code reuse, and enabling real-time human-computer interaction to lower error-correction cost, significantly improving the quality of generated designs.
Theoretical Corrections and the Leveraging of Reinforcement Learning to Enhance Triangle Attack
Nov 18, 2024



Adversarial examples represent a serious issue for the application of machine learning models in many sensitive domains. For generating adversarial examples, decision based black-box attacks are one of the most practical techniques as they only require query access to the model. One of the most recently proposed state-of-the-art decision based black-box attacks is Triangle Attack (TA). In this paper, we offer a high-level description of TA and explain potential theoretical limitations. We then propose a new decision based black-box attack, Triangle Attack with Reinforcement Learning (TARL). Our new attack addresses the limits of TA by leveraging reinforcement learning. This creates an attack that can achieve similar, if not better, attack accuracy than TA with half as many queries on state-of-the-art classifiers and defenses across ImageNet and CIFAR-10.
Quasar-ViT: Hardware-Oriented Quantization-Aware Architecture Search for Vision Transformers
Jul 25, 2024

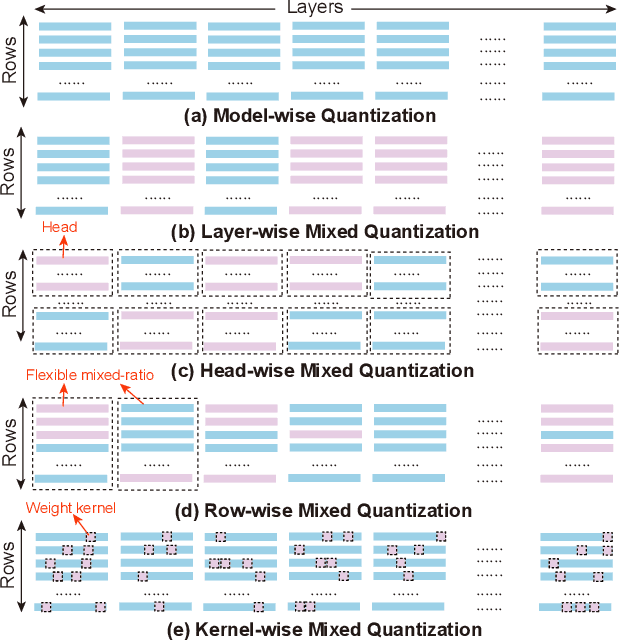

Vision transformers (ViTs) have demonstrated their superior accuracy for computer vision tasks compared to convolutional neural networks (CNNs). However, ViT models are often computation-intensive for efficient deployment on resource-limited edge devices. This work proposes Quasar-ViT, a hardware-oriented quantization-aware architecture search framework for ViTs, to design efficient ViT models for hardware implementation while preserving the accuracy. First, Quasar-ViT trains a supernet using our row-wise flexible mixed-precision quantization scheme, mixed-precision weight entanglement, and supernet layer scaling techniques. Then, it applies an efficient hardware-oriented search algorithm, integrated with hardware latency and resource modeling, to determine a series of optimal subnets from supernet under different inference latency targets. Finally, we propose a series of model-adaptive designs on the FPGA platform to support the architecture search and mitigate the gap between the theoretical computation reduction and the practical inference speedup. Our searched models achieve 101.5, 159.6, and 251.6 frames-per-second (FPS) inference speed on the AMD/Xilinx ZCU102 FPGA with 80.4%, 78.6%, and 74.9% top-1 accuracy, respectively, for the ImageNet dataset, consistently outperforming prior works.