 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeRouter: Efficient and Adaptive Routing of Time-Series Foundation Models
Jun 10, 2026Time-series foundation models (TSFMs) are increasingly explored as predictive experts within emerging agentic time-series systems. However, TSFMs exhibit heterogeneous inductive biases, and no single model consistently dominates across forecasting regimes, making expert selection a critical challenge. Existing systems often delegate this decision to LLM-based controllers, incurring substantial inference overhead. We present TimeRouter, an efficient routing framework that leverages empirical complementarity across a pool of pretrained TSFMs through lightweight discriminative routing, selective gating, and ensemble fallback. Concretely, TimeRouter combines a learned routing head, a selective gate, and an ensemble fallback, enabling adaptive expert selection without invoking an LLM at inference time. TimeRouter achieves state-of-the-art performance on the GIFT-EVAL leaderboard, with an LB MASE of 0.6765. Beyond benchmark performance, our ablation studies provide empirical insights into TSFM routing design, highlighting the importance of pool composition and selective gating. Taken together, these results position TimeRouter as a modular and lightweight routing layer for future agentic time-series systems built upon foundation-model pools. Our code is available at https://github.com/UConn-DSIS/TimeRouter.
DRIFT: A Benchmark for Task-Free Continual Graph Learning with Continuous Distribution Shifts
May 14, 2026Continual graph learning (CGL) aims to learn from dynamically evolving graphs while mitigating catastrophic forgetting. Existing CGL approaches typically adopt a task-based formulation, where the data stream is partitioned into a sequence of discrete tasks with pre-defined boundaries. However, such assumptions rarely hold in real-world environments, where data distributions evolve continuously and task identity is often unavailable. To better reflect realistic non-stationary environments, we revisit continual graph learning from a task-free perspective. We propose a unified formulation that models the data stream as a time-varying mixture of latent task distributions, enabling continuous modeling of distribution drift. Based on this formulation, we construct \emph{DRIFT}, a benchmark that spans a spectrum of transition dynamics ranging from hard task switches to smooth distributional drift through a Gaussian parameterization. We evaluate representative continual learning methods under this task-free setting and observe substantial performance degradation compared to traditional task-based protocols. Our findings indicate that many existing approaches implicitly rely on task boundary information and struggle under realistic task-free graph streams. This work highlights the importance of studying continual graph learning under realistic non-stationary conditions and provides a benchmark for future research in this direction. Our code is available at https://github.com/UConn-DSIS/DRIFT.
Learning Feature Encoder with Synthetic Anomalies for Weakly Supervised Graph Anomaly Detection
May 12, 2026Weakly supervised graph anomaly detection aims to unveil unusual graph instances, e.g., nodes, whose behaviors significantly differ from normal ones, given only a limited number of annotated anomalies and abundant unlabeled samples. A major challenge is to learn a meaningful latent feature representation that reduces intra-class variance among normal data while remaining highly sensitive to anomalies. Although recent works have applied self-supervised feature learning for graph anomaly detection, their strategies are not specifically tailored to its unique requirements, motivating our exploration of a more domain-specific approach. In this paper, we introduce a weakly supervised graph anomaly detection method that leverages a feature learning strategy tailored for graph anomalies. Our approach is built upon a multi-task learning scheme that extracts robust feature representations through synthesized anomalies. We generate synthetic anomalies by perturbing the normal graph in various ways and assign a dedicated detection head to each anomaly type, ensuring that learned features are sensitive to potential deviations from normal patterns. Although synthetic anomalies may not perfectly replicate real-world patterns, they provide valuable auxiliary data for effective feature learnin, much like features learned from ImageNet classification transfer to downstream vision tasks. Additionally, we adopt a two-phase learning strategy: an initial warm-up phase using only synthetic samples, followed by a full-training phase integrating both tasks, to balance the influence of synthetic and real data. Extensive experiments on public datasets demonstrate the superior performance of our method over its competitors. Code is available at https://github.com/yj-zhou/SAWGAD.
* 14 pages, 7 figures, published by IEEE Transactions on Knowledge and Data Engineering,2026
Uncertainty-Guided Latent Diagnostic Trajectory Learning for Sequential Clinical Diagnosis
Apr 06, 2026Clinical diagnosis requires sequential evidence acquisition under uncertainty. However, most Large Language Model (LLM) based diagnostic systems assume fully observed patient information and therefore do not explicitly model how clinical evidence should be sequentially acquired over time. Even when diagnosis is formulated as a sequential decision process, it is still challenging to learn effective diagnostic trajectories. This is because the space of possible evidence-acquisition paths is relatively large, while clinical datasets rarely provide explicit supervision information for desirable diagnostic paths. To this end, we formulate sequential diagnosis as a Latent Diagnostic Trajectory Learning (LDTL) framework based on a planning LLM agent and a diagnostic LLM agent. For the diagnostic LLM agent, diagnostic action sequences are treated as latent paths and we introduce a posterior distribution that prioritizes trajectories providing more diagnostic information. The planning LLM agent is then trained to follow this distribution, encouraging coherent diagnostic trajectories that progressively reduce uncertainty. Experiments on the MIMIC-CDM benchmark demonstrate that our proposed LDTL framework outperforms existing baselines in diagnostic accuracy under a sequential clinical diagnosis setting, while requiring fewer diagnostic tests. Furthermore, ablation studies highlight the critical role of trajectory-level posterior alignment in achieving these improvements.
Empowering Power Outage Prediction with Spatially Aware Hybrid Graph Neural Networks and Contrastive Learning
Apr 06, 2026Extreme weather events, such as severe storms, hurricanes, snowstorms, and ice storms, which are exacerbated by climate change, frequently cause widespread power outages. These outages halt industrial operations, impact communities, damage critical infrastructure, profoundly disrupt economies, and have far-reaching effects across various sectors. To mitigate these effects, the University of Connecticut and Eversource Energy Center have developed an outage prediction modeling (OPM) system to provide pre-emptive forecasts for electric distribution networks before such weather events occur. However, existing predictive models in the system do not incorporate the spatial effect of extreme weather events. To this end, we develop Spatially Aware Hybrid Graph Neural Networks (SA-HGNN) with contrastive learning to enhance the OPM predictions for extreme weather-induced power outages. Specifically, we first encode spatial relationships of both static features (e.g., land cover, infrastructure) and event-specific dynamic features (e.g., wind speed, precipitation) via Spatially Aware Hybrid Graph Neural Networks (SA-HGNN). Next, we leverage contrastive learning to handle the imbalance problem associated with different types of extreme weather events and generate location-specific embeddings by minimizing intra-event distances between similar locations while maximizing inter-event distances across all locations. Thorough empirical studies in four utility service territories, i.e., Connecticut, Western Massachusetts, Eastern Massachusetts, and New Hampshire, demonstrate that SA-HGNN can achieve state-of-the-art performance for power outage prediction.
Early GVHD Prediction in Liver Transplantation via Multi-Modal Deep Learning on Imbalanced EHR Data
Nov 06, 2025Graft-versus-host disease (GVHD) is a rare but often fatal complication in liver transplantation, with a very high mortality rate. By harnessing multi-modal deep learning methods to integrate heterogeneous and imbalanced electronic health records (EHR), we aim to advance early prediction of GVHD, paving the way for timely intervention and improved patient outcomes. In this study, we analyzed pre-transplant electronic health records (EHR) spanning the period before surgery for 2,100 liver transplantation patients, including 42 cases of graft-versus-host disease (GVHD), from a cohort treated at Mayo Clinic between 1992 and 2025. The dataset comprised four major modalities: patient demographics, laboratory tests, diagnoses, and medications. We developed a multi-modal deep learning framework that dynamically fuses these modalities, handles irregular records with missing values, and addresses extreme class imbalance through AUC-based optimization. The developed framework outperforms all single-modal and multi-modal machine learning baselines, achieving an AUC of 0.836, an AUPRC of 0.157, a recall of 0.768, and a specificity of 0.803. It also demonstrates the effectiveness of our approach in capturing complementary information from different modalities, leading to improved performance. Our multi-modal deep learning framework substantially improves existing approaches for early GVHD prediction. By effectively addressing the challenges of heterogeneity and extreme class imbalance in real-world EHR, it achieves accurate early prediction. Our proposed multi-modal deep learning method demonstrates promising results for early prediction of a GVHD in liver transplantation, despite the challenge of extremely imbalanced EHR data.
From Images to Signals: Are Large Vision Models Useful for Time Series Analysis?
May 29, 2025Transformer-based models have gained increasing attention in time series research, driving interest in Large Language Models (LLMs) and foundation models for time series analysis. As the field moves toward multi-modality, Large Vision Models (LVMs) are emerging as a promising direction. In the past, the effectiveness of Transformer and LLMs in time series has been debated. When it comes to LVMs, a similar question arises: are LVMs truely useful for time series analysis? To address it, we design and conduct the first principled study involving 4 LVMs, 8 imaging methods, 18 datasets and 26 baselines across both high-level (classification) and low-level (forecasting) tasks, with extensive ablation analysis. Our findings indicate LVMs are indeed useful for time series classification but face challenges in forecasting. Although effective, the contemporary best LVM forecasters are limited to specific types of LVMs and imaging methods, exhibit a bias toward forecasting periods, and have limited ability to utilize long look-back windows. We hope our findings could serve as a cornerstone for future research on LVM- and multimodal-based solutions to different time series tasks.
Multi-Modal View Enhanced Large Vision Models for Long-Term Time Series Forecasting
May 29, 2025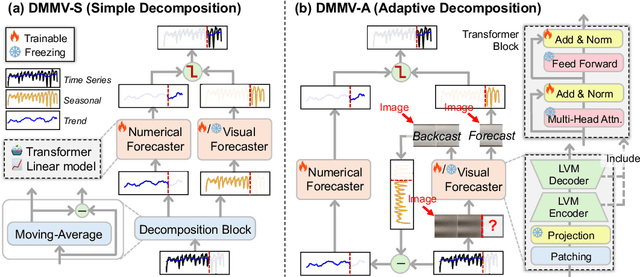
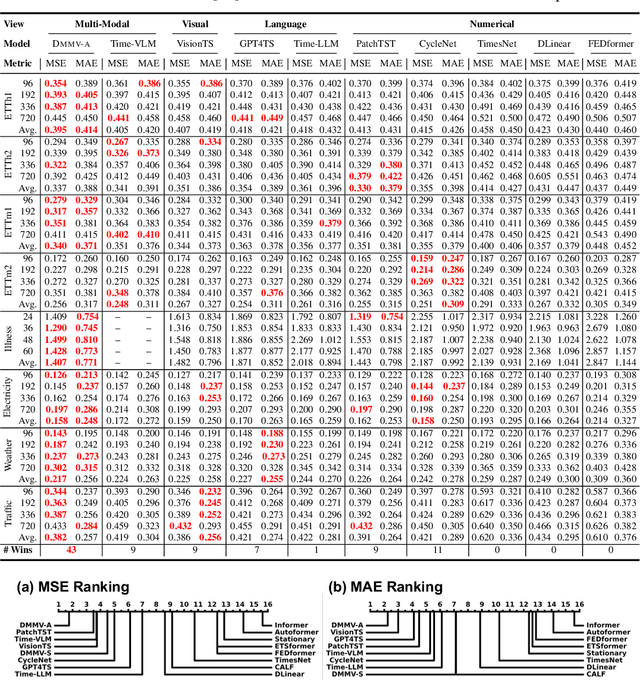
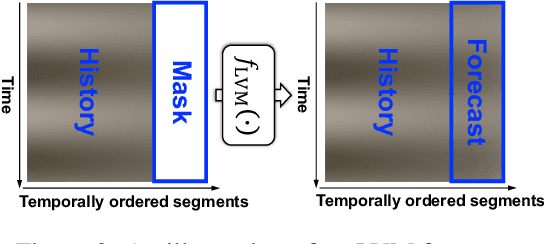
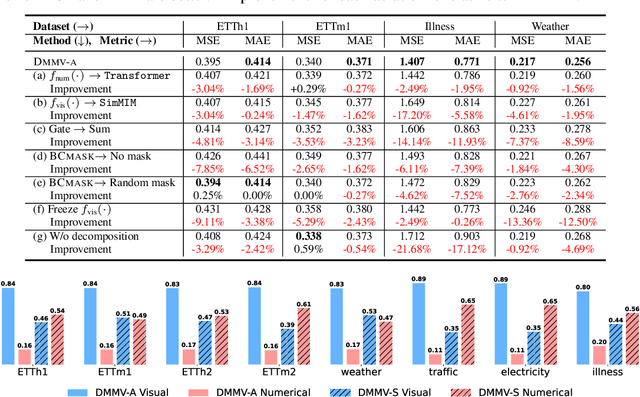
Time series, typically represented as numerical sequences, can also be transformed into images and texts, offering multi-modal views (MMVs) of the same underlying signal. These MMVs can reveal complementary patterns and enable the use of powerful pre-trained large models, such as large vision models (LVMs), for long-term time series forecasting (LTSF). However, as we identified in this work, applying LVMs to LTSF poses an inductive bias towards "forecasting periods". To harness this bias, we propose DMMV, a novel decomposition-based multi-modal view framework that leverages trend-seasonal decomposition and a novel backcast residual based adaptive decomposition to integrate MMVs for LTSF. Comparative evaluations against 14 state-of-the-art (SOTA) models across diverse datasets show that DMMV outperforms single-view and existing multi-modal baselines, achieving the best mean squared error (MSE) on 6 out of 8 benchmark datasets.
Towards Heterogeneous Continual Graph Learning via Meta-knowledge Distillation
May 23, 2025Machine learning on heterogeneous graphs has experienced rapid advancement in recent years, driven by the inherently heterogeneous nature of real-world data. However, existing studies typically assume the graphs to be static, while real-world graphs are continuously expanding. This dynamic nature requires models to adapt to new data while preserving existing knowledge. To this end, this work addresses the challenge of continual learning on heterogeneous graphs by introducing the Meta-learning based Knowledge Distillation framework (MKD), designed to mitigate catastrophic forgetting in evolving heterogeneous graph structures. MKD combines rapid task adaptation through meta-learning on limited samples with knowledge distillation to achieve an optimal balance between incorporating new information and maintaining existing knowledge. To improve the efficiency and effectiveness of sample selection, MKD incorporates a novel sampling strategy that selects a small number of target-type nodes based on node diversity and maintains fixed-size buffers for other types. The strategy retrieves first-order neighbors along metapaths and selects important neighbors based on their structural relevance, enabling the sampled subgraphs to retain key topological and semantic information. In addition, MKD introduces a semantic-level distillation module that aligns the attention distributions over different metapaths between teacher and student models, encouraging semantic consistency beyond the logit level. Comprehensive evaluations across three benchmark datasets validate MKD's effectiveness in handling continual learning scenarios on expanding heterogeneous graphs.
Multi-modal Time Series Analysis: A Tutorial and Survey
Mar 17, 2025Multi-modal time series analysis has recently emerged as a prominent research area in data mining, driven by the increasing availability of diverse data modalities, such as text, images, and structured tabular data from real-world sources. However, effective analysis of multi-modal time series is hindered by data heterogeneity, modality gap, misalignment, and inherent noise. Recent advancements in multi-modal time series methods have exploited the multi-modal context via cross-modal interactions based on deep learning methods, significantly enhancing various downstream tasks. In this tutorial and survey, we present a systematic and up-to-date overview of multi-modal time series datasets and methods. We first state the existing challenges of multi-modal time series analysis and our motivations, with a brief introduction of preliminaries. Then, we summarize the general pipeline and categorize existing methods through a unified cross-modal interaction framework encompassing fusion, alignment, and transference at different levels (\textit{i.e.}, input, intermediate, output), where key concepts and ideas are highlighted. We also discuss the real-world applications of multi-modal analysis for both standard and spatial time series, tailored to general and specific domains. Finally, we discuss future research directions to help practitioners explore and exploit multi-modal time series. The up-to-date resources are provided in the GitHub repository: https://github.com/UConn-DSIS/Multi-modal-Time-Series-Analysis