 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Radiologist's Intention from Eye Movements in Chest X-ray Diagnosis
Jul 16, 2025Radiologists rely on eye movements to navigate and interpret medical images. A trained radiologist possesses knowledge about the potential diseases that may be present in the images and, when searching, follows a mental checklist to locate them using their gaze. This is a key observation, yet existing models fail to capture the underlying intent behind each fixation. In this paper, we introduce a deep learning-based approach, RadGazeIntent, designed to model this behavior: having an intention to find something and actively searching for it. Our transformer-based architecture processes both the temporal and spatial dimensions of gaze data, transforming fine-grained fixation features into coarse, meaningful representations of diagnostic intent to interpret radiologists' goals. To capture the nuances of radiologists' varied intention-driven behaviors, we process existing medical eye-tracking datasets to create three intention-labeled subsets: RadSeq (Systematic Sequential Search), RadExplore (Uncertainty-driven Exploration), and RadHybrid (Hybrid Pattern). Experimental results demonstrate RadGazeIntent's ability to predict which findings radiologists are examining at specific moments, outperforming baseline methods across all intention-labeled datasets.
From Images to Signals: Are Large Vision Models Useful for Time Series Analysis?
May 29, 2025Transformer-based models have gained increasing attention in time series research, driving interest in Large Language Models (LLMs) and foundation models for time series analysis. As the field moves toward multi-modality, Large Vision Models (LVMs) are emerging as a promising direction. In the past, the effectiveness of Transformer and LLMs in time series has been debated. When it comes to LVMs, a similar question arises: are LVMs truely useful for time series analysis? To address it, we design and conduct the first principled study involving 4 LVMs, 8 imaging methods, 18 datasets and 26 baselines across both high-level (classification) and low-level (forecasting) tasks, with extensive ablation analysis. Our findings indicate LVMs are indeed useful for time series classification but face challenges in forecasting. Although effective, the contemporary best LVM forecasters are limited to specific types of LVMs and imaging methods, exhibit a bias toward forecasting periods, and have limited ability to utilize long look-back windows. We hope our findings could serve as a cornerstone for future research on LVM- and multimodal-based solutions to different time series tasks.
Marvel: Accelerating Safe Online Reinforcement Learning with Finetuned Offline Policy
Dec 05, 2024
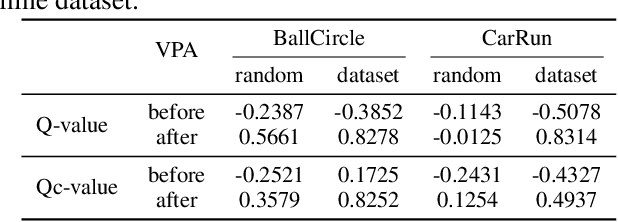

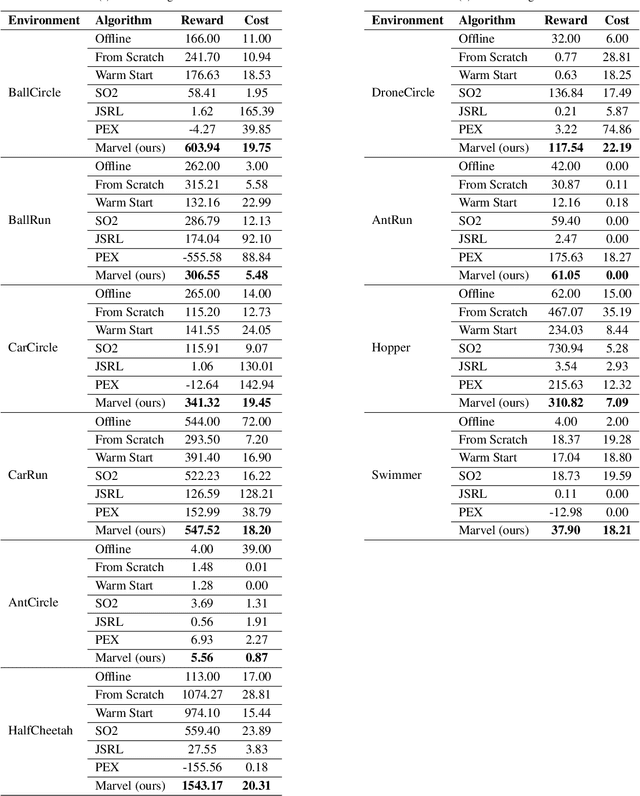
The high costs and risks involved in extensive environment interactions hinder the practical application of current online safe reinforcement learning (RL) methods. While offline safe RL addresses this by learning policies from static datasets, the performance therein is usually limited due to reliance on data quality and challenges with out-of-distribution (OOD) actions. Inspired by recent successes in offline-to-online (O2O) RL, it is crucial to explore whether offline safe RL can be leveraged to facilitate faster and safer online policy learning, a direction that has yet to be fully investigated. To fill this gap, we first demonstrate that naively applying existing O2O algorithms from standard RL would not work well in the safe RL setting due to two unique challenges: \emph{erroneous Q-estimations}, resulted from offline-online objective mismatch and offline cost sparsity, and \emph{Lagrangian mismatch}, resulted from difficulties in aligning Lagrange multipliers between offline and online policies. To address these challenges, we introduce \textbf{Marvel}, a novel framework for O2O safe RL, comprising two key components that work in concert: \emph{Value Pre-Alignment} to align the Q-functions with the underlying truth before online learning, and \emph{Adaptive PID Control} to effectively adjust the Lagrange multipliers during online finetuning. Extensive experiments demonstrate that Marvel significantly outperforms existing baselines in both reward maximization and safety constraint satisfaction. By introducing the first policy-finetuning based framework for O2O safe RL, which is compatible with many offline and online safe RL methods, our work has the great potential to advance the field towards more efficient and practical safe RL solutions.
GazeSearch: Radiology Findings Search Benchmark
Nov 08, 2024



Medical eye-tracking data is an important information source for understanding how radiologists visually interpret medical images. This information not only improves the accuracy of deep learning models for X-ray analysis but also their interpretability, enhancing transparency in decision-making. However, the current eye-tracking data is dispersed, unprocessed, and ambiguous, making it difficult to derive meaningful insights. Therefore, there is a need to create a new dataset with more focus and purposeful eyetracking data, improving its utility for diagnostic applications. In this work, we propose a refinement method inspired by the target-present visual search challenge: there is a specific finding and fixations are guided to locate it. After refining the existing eye-tracking datasets, we transform them into a curated visual search dataset, called GazeSearch, specifically for radiology findings, where each fixation sequence is purposefully aligned to the task of locating a particular finding. Subsequently, we introduce a scan path prediction baseline, called ChestSearch, specifically tailored to GazeSearch. Finally, we employ the newly introduced GazeSearch as a benchmark to evaluate the performance of current state-of-the-art methods, offering a comprehensive assessment for visual search in the medical imaging domain.
Multimodal Learning and Cognitive Processes in Radiology: MedGaze for Chest X-ray Scanpath Prediction
Jun 28, 2024



Predicting human gaze behavior within computer vision is integral for developing interactive systems that can anticipate user attention, address fundamental questions in cognitive science, and hold implications for fields like human-computer interaction (HCI) and augmented/virtual reality (AR/VR) systems. Despite methodologies introduced for modeling human eye gaze behavior, applying these models to medical imaging for scanpath prediction remains unexplored. Our proposed system aims to predict eye gaze sequences from radiology reports and CXR images, potentially streamlining data collection and enhancing AI systems using larger datasets. However, predicting human scanpaths on medical images presents unique challenges due to the diverse nature of abnormal regions. Our model predicts fixation coordinates and durations critical for medical scanpath prediction, outperforming existing models in the computer vision community. Utilizing a two-stage training process and large publicly available datasets, our approach generates static heatmaps and eye gaze videos aligned with radiology reports, facilitating comprehensive analysis. We validate our approach by comparing its performance with state-of-the-art methods and assessing its generalizability among different radiologists, introducing novel strategies to model radiologists' search patterns during CXR image diagnosis. Based on the radiologist's evaluation, MedGaze can generate human-like gaze sequences with a high focus on relevant regions over the CXR images. It sometimes also outperforms humans in terms of redundancy and randomness in the scanpaths.
Enhancing Radiological Diagnosis: A Collaborative Approach Integrating AI and Human Expertise for Visual Miss Correction
Jun 28, 2024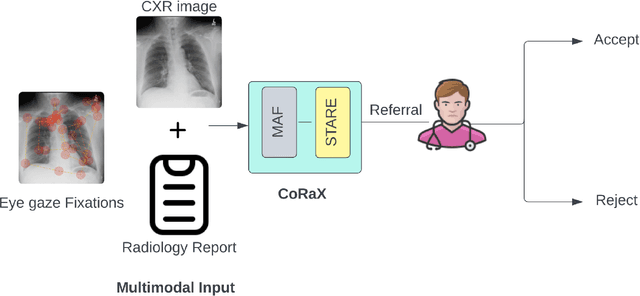

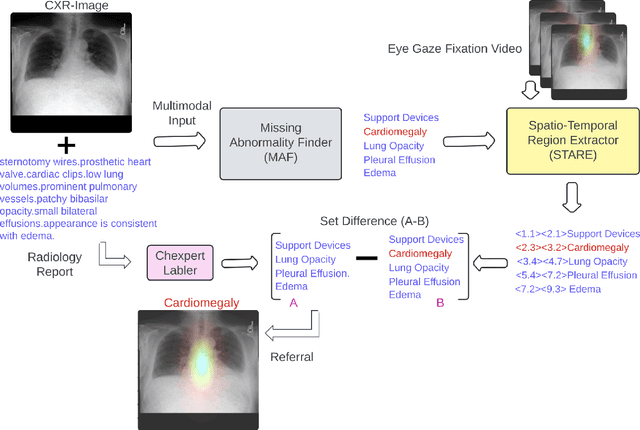

Human-AI collaboration to identify and correct perceptual errors in chest radiographs has not been previously explored. This study aimed to develop a collaborative AI system, CoRaX, which integrates eye gaze data and radiology reports to enhance diagnostic accuracy in chest radiology by pinpointing perceptual errors and refining the decision-making process. Using public datasets REFLACX and EGD-CXR, the study retrospectively developed CoRaX, employing a large multimodal model to analyze image embeddings, eye gaze data, and radiology reports. The system's effectiveness was evaluated based on its referral-making process, the quality of referrals, and performance in collaborative diagnostic settings. CoRaX was tested on a simulated error dataset of 271 samples with 28% (93 of 332) missed abnormalities. The system corrected 21% (71 of 332) of these errors, leaving 7% (22 of 312) unresolved. The Referral-Usefulness score, indicating the accuracy of predicted regions for all true referrals, was 0.63 (95% CI 0.59, 0.68). The Total-Usefulness score, reflecting the diagnostic accuracy of CoRaX's interactions with radiologists, showed that 84% (237 of 280) of these interactions had a score above 0.40. In conclusion, CoRaX efficiently collaborates with radiologists to address perceptual errors across various abnormalities, with potential applications in the education and training of novice radiologists.
Global-to-local Expression-aware Embeddings for Facial Action Unit Detection
Oct 28, 2022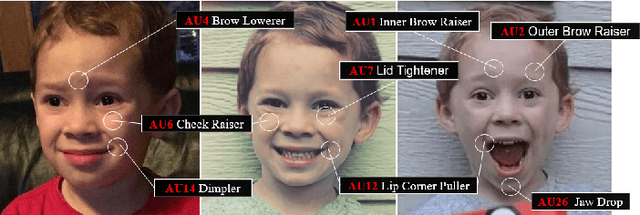
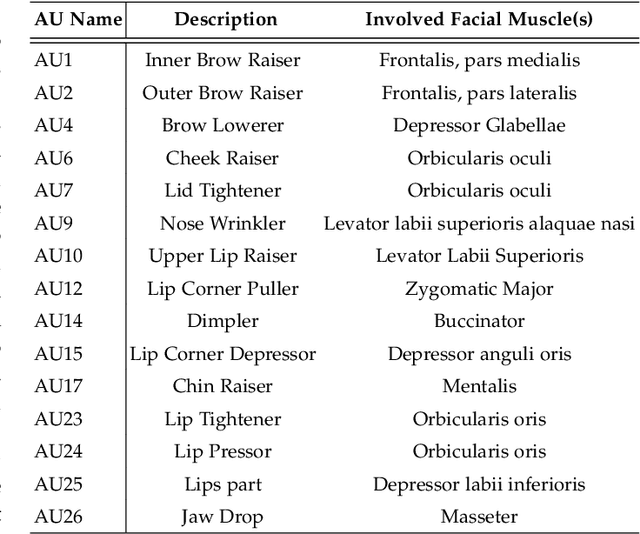
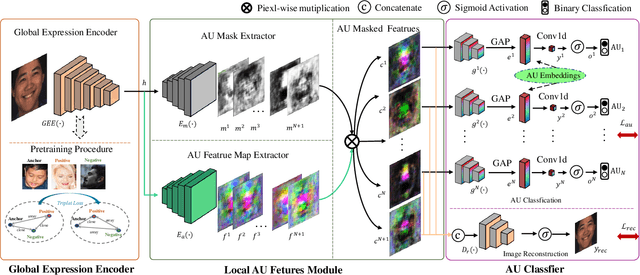

Expressions and facial action units (AUs) are two levels of facial behavior descriptors. Expression auxiliary information has been widely used to improve the AU detection performance. However, most existing expression representations can only describe pre-determined discrete categories (e.g., Angry, Disgust, Happy, Sad, etc.) and cannot capture subtle expression transformations like AUs. In this paper, we propose a novel fine-grained \textsl{Global Expression representation Encoder} to capture subtle and continuous facial movements, to promote AU detection. To obtain such a global expression representation, we propose to train an expression embedding model on a large-scale expression dataset according to global expression similarity. Moreover, considering the local definition of AUs, it is essential to extract local AU features. Therefore, we design a \textsl{Local AU Features Module} to generate local facial features for each AU. Specifically, it consists of an AU feature map extractor and a corresponding AU mask extractor. First, the two extractors transform the global expression representation into AU feature maps and masks, respectively. Then, AU feature maps and their corresponding AU masks are multiplied to generate AU masked features focusing on local facial region. Finally, the AU masked features are fed into an AU classifier for judging the AU occurrence. Extensive experiment results demonstrate the superiority of our proposed method. Our method validly outperforms previous works and achieves state-of-the-art performances on widely-used face datasets, including BP4D, DISFA, and BP4D+.
Facial Action Units Detection Aided by Global-Local Expression Embedding
Oct 25, 2022Since Facial Action Unit (AU) annotations require domain expertise, common AU datasets only contain a limited number of subjects. As a result, a crucial challenge for AU detection is addressing identity overfitting. We find that AUs and facial expressions are highly associated, and existing facial expression datasets often contain a large number of identities. In this paper, we aim to utilize the expression datasets without AU labels to facilitate AU detection. Specifically, we develop a novel AU detection framework aided by the Global-Local facial Expressions Embedding, dubbed GLEE-Net. Our GLEE-Net consists of three branches to extract identity-independent expression features for AU detection. We introduce a global branch for modeling the overall facial expression while eliminating the impacts of identities. We also design a local branch focusing on specific local face regions. The combined output of global and local branches is firstly pre-trained on an expression dataset as an identity-independent expression embedding, and then finetuned on AU datasets. Therefore, we significantly alleviate the issue of limited identities. Furthermore, we introduce a 3D global branch that extracts expression coefficients through 3D face reconstruction to consolidate 2D AU descriptions. Finally, a Transformer-based multi-label classifier is employed to fuse all the representations for AU detection. Extensive experiments demonstrate that our method significantly outperforms the state-of-the-art on the widely-used DISFA, BP4D and BP4D+ datasets.