 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShortcut Learning in Glomerular AI: Adversarial Penalties Hurt, Entropy Helps
Apr 09, 2026Stain variability is a pervasive source of distribution shift and potential shortcut learning in renal pathology AI. We ask whether lupus nephritis glomerular lesion classifiers exploit stain as a shortcut, and how to mitigate such bias without stain or site labels. We curate a multi-center, multi-stain dataset of 9{,}674 glomerular patches (224$\times$224) from 365 WSIs across three centers and four stains (PAS, H\&E, Jones, Trichrome), labeled as proliferative vs.\ non-proliferative. We evaluate Bayesian CNN and ViT backbones with Monte Carlo dropout in three settings: (1) stain-only classification; (2) a dual-head model jointly predicting lesion and stain with supervised stain loss; and (3) a dual-head model with label-free stain regularization via entropy maximization on the stain head. In (1), stain identity is trivially learnable, confirming a strong candidate shortcut. In (2), varying the strength and sign of stain supervision strongly modulates stain performance but leaves lesion metrics essentially unchanged, indicating no measurable stain-driven shortcut learning on this multi-stain, multi-center dataset, while overly adversarial stain penalties inflate predictive uncertainty. In (3), entropy-based regularization holds stain predictions near chance without degrading lesion accuracy or calibration. Overall, a carefully curated multi-stain dataset can be inherently robust to stain shortcuts, and a Bayesian dual-head architecture with label-free entropy regularization offers a simple, deployment-friendly safeguard against potential stain-related drift in glomerular AI.
GazeQwen: Lightweight Gaze-Conditioned LLM Modulation for Streaming Video Understanding
Mar 26, 2026Current multimodal large language models (MLLMs) cannot effectively utilize eye-gaze information for video understanding, even when gaze cues are supplied via visual overlays or text descriptions. We introduce GazeQwen, a parameter efficient approach that equips an open-source MLLM with gaze awareness through hidden-state modulation. At its core is a compact gaze resampler (~1-5 M trainable parameters) that encodes V-JEPA 2.1 video features together with fixation-derived positional encodings and produces additive residuals injected into selected LLM decoder layers via forward hooks. An optional second training stage adds low-rank adapters (LoRA) to the LLM for tighter integration. Evaluated on all 10 tasks of the StreamGaze benchmark, GazeQwen reaches 63.9% accuracy, a +16.1 point gain over the same Qwen2.5-VL-7B backbone with gaze as visual prompts and +10.5 points over GPT-4o, the highest score among all open-source and proprietary models tested. These results suggest that learning where to inject gaze within an LLM is more effective than scaling model size or engineering better prompts. All code and checkpoints are available at https://github.com/phamtrongthang123/gazeqwen .
VietNormalizer: An Open-Source, Dependency-Free Python Library for Vietnamese Text Normalization in TTS and NLP Applications
Mar 04, 2026We present VietNormalizer1, an open-source, zero-dependency Python library for Vietnamese text normalization targeting Text-to-Speech (TTS) and Natural Language Processing (NLP) applications. Vietnamese text normalization is a critical yet underserved preprocessing step: real-world Vietnamese text is densely populated with non-standard words (NSWs), including numbers, dates, times, currency amounts, percentages, acronyms, and foreign-language terms, all of which must be converted to fully pronounceable Vietnamese words before TTS synthesis or downstream language processing. Existing Vietnamese normalization tools either require heavy neural dependencies while covering only a narrow subset of NSW classes, or are embedded within larger NLP toolkits without standalone installability. VietNormalizer addresses these gaps through a unified, rule-based pipeline that: (1) converts arbitrary integers, decimals, and large numbers to Vietnamese words; (2) normalizes dates and times to their spoken Vietnamese forms; (3) handles VND and USD currency amounts; (4) expands percentages; (5) resolves acronyms via a customizable CSV dictionary; (6) transliterates non-Vietnamese loanwords and foreign terms to Vietnamese phonetic approximations; and (7) performs Unicode normalization and emoji/special-character removal. All regular expression patterns are pre-compiled at initialization, enabling high-throughput batch processing with minimal memory overhead and no GPU or external API dependency. The library is installable via pip install vietnormalizer, available on PyPI and GitHub at https://github.com/nghimestudio/vietnormalizer, and released under the MIT license. We discuss the design decisions, limitations of existing approaches, and the generalizability of the rule-based normalization paradigm to other low-resource tonal and agglutinative languages.
FG-CXR: A Radiologist-Aligned Gaze Dataset for Enhancing Interpretability in Chest X-Ray Report Generation
Nov 23, 2024



Developing an interpretable system for generating reports in chest X-ray (CXR) analysis is becoming increasingly crucial in Computer-aided Diagnosis (CAD) systems, enabling radiologists to comprehend the decisions made by these systems. Despite the growth of diverse datasets and methods focusing on report generation, there remains a notable gap in how closely these models' generated reports align with the interpretations of real radiologists. In this study, we tackle this challenge by initially introducing Fine-Grained CXR (FG-CXR) dataset, which provides fine-grained paired information between the captions generated by radiologists and the corresponding gaze attention heatmaps for each anatomy. Unlike existing datasets that include a raw sequence of gaze alongside a report, with significant misalignment between gaze location and report content, our FG-CXR dataset offers a more grained alignment between gaze attention and diagnosis transcript. Furthermore, our analysis reveals that simply applying black-box image captioning methods to generate reports cannot adequately explain which information in CXR is utilized and how long needs to attend to accurately generate reports. Consequently, we propose a novel explainable radiologist's attention generator network (Gen-XAI) that mimics the diagnosis process of radiologists, explicitly constraining its output to closely align with both radiologist's gaze attention and transcript. Finally, we perform extensive experiments to illustrate the effectiveness of our method. Our datasets and checkpoint is available at https://github.com/UARK-AICV/FG-CXR.
GazeSearch: Radiology Findings Search Benchmark
Nov 08, 2024



Medical eye-tracking data is an important information source for understanding how radiologists visually interpret medical images. This information not only improves the accuracy of deep learning models for X-ray analysis but also their interpretability, enhancing transparency in decision-making. However, the current eye-tracking data is dispersed, unprocessed, and ambiguous, making it difficult to derive meaningful insights. Therefore, there is a need to create a new dataset with more focus and purposeful eyetracking data, improving its utility for diagnostic applications. In this work, we propose a refinement method inspired by the target-present visual search challenge: there is a specific finding and fixations are guided to locate it. After refining the existing eye-tracking datasets, we transform them into a curated visual search dataset, called GazeSearch, specifically for radiology findings, where each fixation sequence is purposefully aligned to the task of locating a particular finding. Subsequently, we introduce a scan path prediction baseline, called ChestSearch, specifically tailored to GazeSearch. Finally, we employ the newly introduced GazeSearch as a benchmark to evaluate the performance of current state-of-the-art methods, offering a comprehensive assessment for visual search in the medical imaging domain.
Controllable Group Choreography using Contrastive Diffusion
Nov 03, 2023
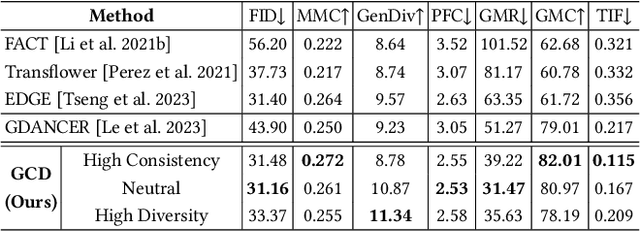
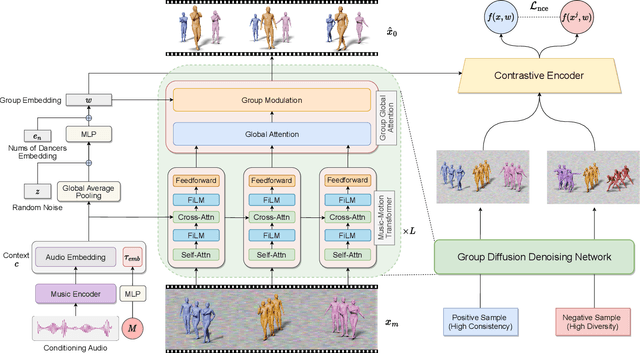
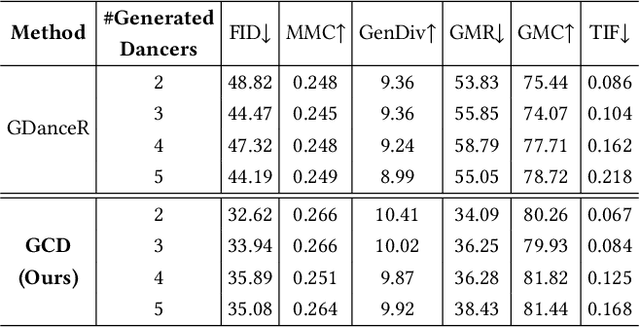
Music-driven group choreography poses a considerable challenge but holds significant potential for a wide range of industrial applications. The ability to generate synchronized and visually appealing group dance motions that are aligned with music opens up opportunities in many fields such as entertainment, advertising, and virtual performances. However, most of the recent works are not able to generate high-fidelity long-term motions, or fail to enable controllable experience. In this work, we aim to address the demand for high-quality and customizable group dance generation by effectively governing the consistency and diversity of group choreographies. In particular, we utilize a diffusion-based generative approach to enable the synthesis of flexible number of dancers and long-term group dances, while ensuring coherence to the input music. Ultimately, we introduce a Group Contrastive Diffusion (GCD) strategy to enhance the connection between dancers and their group, presenting the ability to control the consistency or diversity level of the synthesized group animation via the classifier-guidance sampling technique. Through intensive experiments and evaluation, we demonstrate the effectiveness of our approach in producing visually captivating and consistent group dance motions. The experimental results show the capability of our method to achieve the desired levels of consistency and diversity, while maintaining the overall quality of the generated group choreography. The source code can be found at https://aioz-ai.github.io/GCD
Decoding Radiologists Intense Focus for Accurate CXR Diagnoses: A Controllable and Interpretable AI System
Sep 26, 2023



In the field of chest X-ray (CXR) diagnosis, existing works often focus solely on determining where a radiologist looks, typically through tasks such as detection, segmentation, or classification. However, these approaches are often designed as black-box models, lacking interpretability. In this paper, we introduce a novel and unified controllable interpretable pipeline for decoding the intense focus of radiologists in CXR diagnosis. Our approach addresses three key questions: where a radiologist looks, how long they focus on specific areas, and what findings they diagnose. By capturing the intensity of the radiologist's gaze, we provide a unified solution that offers insights into the cognitive process underlying radiological interpretation. Unlike current methods that rely on black-box machine learning models, which can be prone to extracting erroneous information from the entire input image during the diagnosis process, we tackle this issue by effectively masking out irrelevant information. Our approach leverages a vision-language model, allowing for precise control over the interpretation process while ensuring the exclusion of irrelevant features. To train our model, we utilize an eye gaze dataset to extract anatomical gaze information and generate ground truth heatmaps. Through extensive experimentation, we demonstrate the efficacy of our method. We showcase that the attention heatmaps, designed to mimic radiologists' focus, encode sufficient and relevant information, enabling accurate classification tasks using only a portion of CXR.
Automated wildlife image classification: An active learning tool for ecological applications
Mar 28, 2023



Wildlife camera trap images are being used extensively to investigate animal abundance, habitat associations, and behavior, which is complicated by the fact that experts must first classify the images manually. Artificial intelligence systems can take over this task but usually need a large number of already-labeled training images to achieve sufficient performance. This requirement necessitates human expert labor and poses a particular challenge for projects with few cameras or short durations. We propose a label-efficient learning strategy that enables researchers with small or medium-sized image databases to leverage the potential of modern machine learning, thus freeing crucial resources for subsequent analyses. Our methodological proposal is two-fold: (1) We improve current strategies of combining object detection and image classification by tuning the hyperparameters of both models. (2) We provide an active learning (AL) system that allows training deep learning models very efficiently in terms of required human-labeled training images. We supply a software package that enables researchers to use these methods directly and thereby ensure the broad applicability of the proposed framework in ecological practice. We show that our tuning strategy improves predictive performance. We demonstrate how the AL pipeline reduces the amount of pre-labeled data needed to achieve a specific predictive performance and that it is especially valuable for improving out-of-sample predictive performance. We conclude that the combination of tuning and AL increases predictive performance substantially. Furthermore, we argue that our work can broadly impact the community through the ready-to-use software package provided. Finally, the publication of our models tailored to European wildlife data enriches existing model bases mostly trained on data from Africa and North America.
Addressing Non-IID Problem in Federated Autonomous Driving with Contrastive Divergence Loss
Mar 11, 2023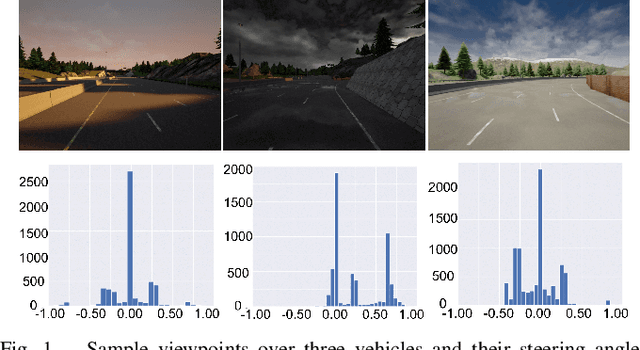
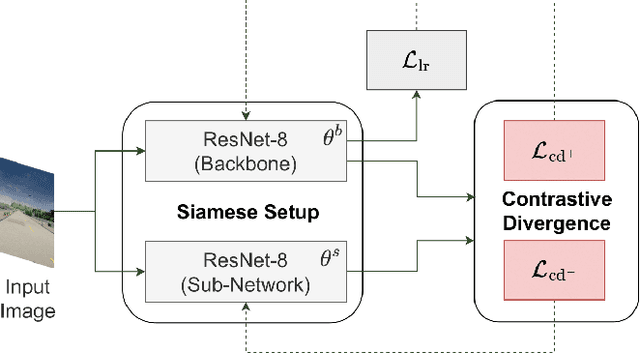
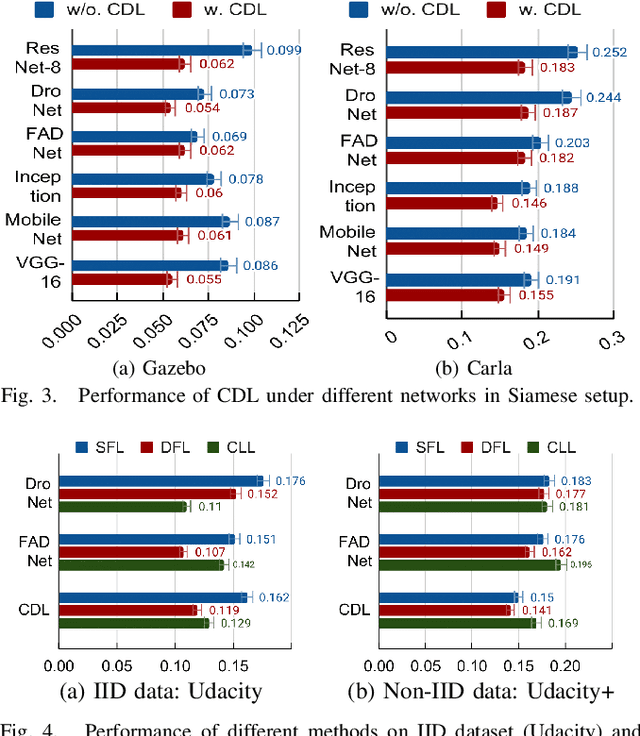
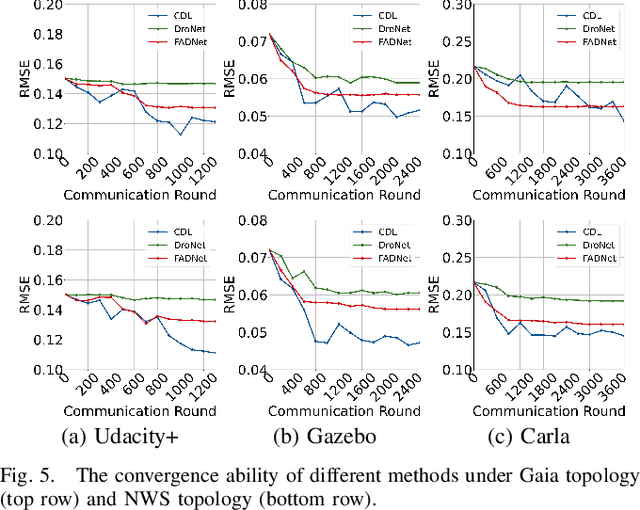
Federated learning has been widely applied in autonomous driving since it enables training a learning model among vehicles without sharing users' data. However, data from autonomous vehicles usually suffer from the non-independent-and-identically-distributed (non-IID) problem, which may cause negative effects on the convergence of the learning process. In this paper, we propose a new contrastive divergence loss to address the non-IID problem in autonomous driving by reducing the impact of divergence factors from transmitted models during the local learning process of each silo. We also analyze the effects of contrastive divergence in various autonomous driving scenarios, under multiple network infrastructures, and with different centralized/distributed learning schemes. Our intensive experiments on three datasets demonstrate that our proposed contrastive divergence loss further improves the performance over current state-of-the-art approaches.
Multigraph Topology Design for Cross-Silo Federated Learning
Jul 21, 2022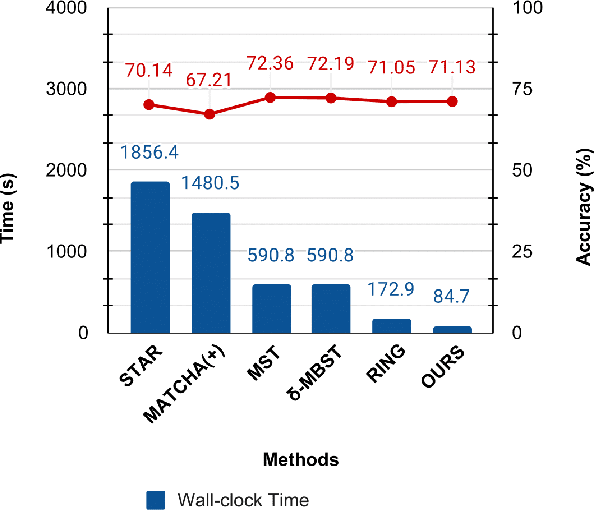
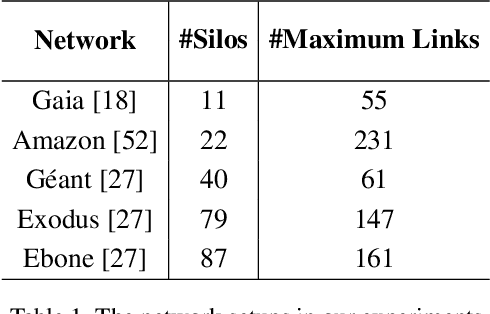
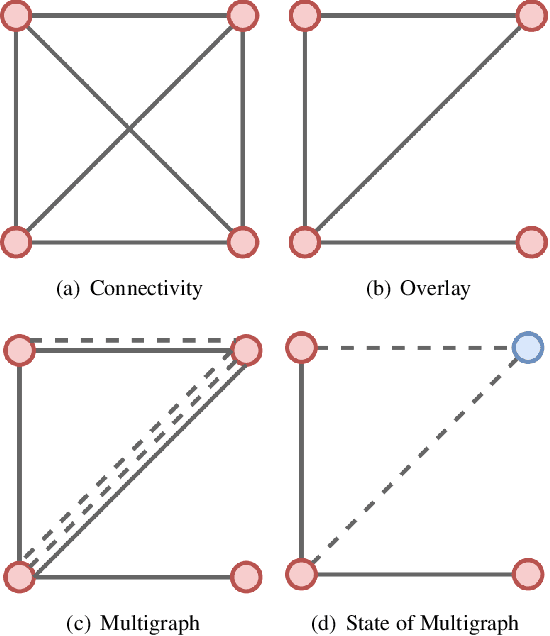
Cross-silo federated learning utilizes a few hundred reliable data silos with high-speed access links to jointly train a model. While this approach becomes a popular setting in federated learning, designing a robust topology to reduce the training time is still an open problem. In this paper, we present a new multigraph topology for cross-silo federated learning. We first construct the multigraph using the overlay graph. We then parse this multigraph into different simple graphs with isolated nodes. The existence of isolated nodes allows us to perform model aggregation without waiting for other nodes, hence reducing the training time. We further propose a new distributed learning algorithm to use with our multigraph topology. The intensive experiments on public datasets show that our proposed method significantly reduces the training time compared with recent state-of-the-art topologies while ensuring convergence and maintaining the model's accuracy.