 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAeroScene: Progressive Scene Synthesis for Aerial Robotics
Mar 24, 2026Generative models have shown substantial impact across multiple domains, their potential for scene synthesis remains underexplored in robotics. This gap is more evident in drone simulators, where simulation environments still rely heavily on manual efforts, which are time-consuming to create and difficult to scale. In this work, we introduce AeroScene, a hierarchical diffusion model for progressive 3D scene synthesis. Our approach leverages hierarchy-aware tokenization and multi-branch feature extraction to reason across both global layouts and local details, ensuring physical plausibility and semantic consistency. This makes AeroScene particularly suited for generating realistic scenes for aerial robotics tasks such as navigation, landing, and perching. We demonstrate its effectiveness through extensive experiments on our newly collected dataset and a public benchmark, showing that AeroScene significantly outperforms prior methods. Furthermore, we use AeroScene to generate a large-scale dataset of over 1,000 physics-ready, high fidelity 3D scenes that can be directly integrated into NVIDIA Isaac Sim. Finally, we illustrate the utility of these generated environments on downstream drone navigation tasks. Our code and dataset are publicly available at aioz-ai.github.io/AeroScene/
Addressing Non-IID Problem in Federated Autonomous Driving with Contrastive Divergence Loss
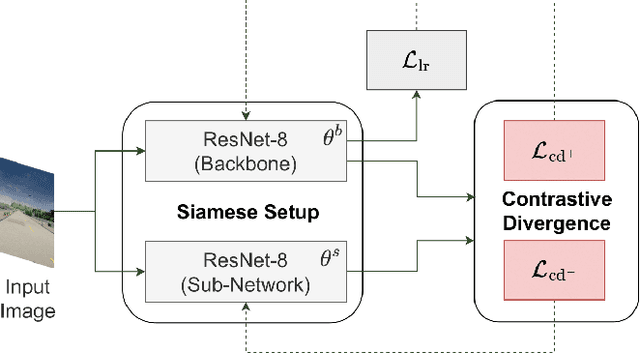
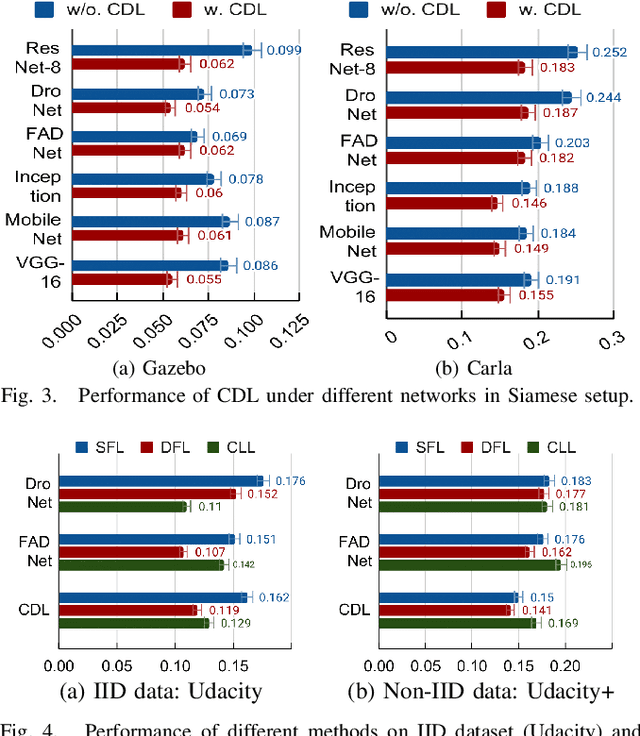
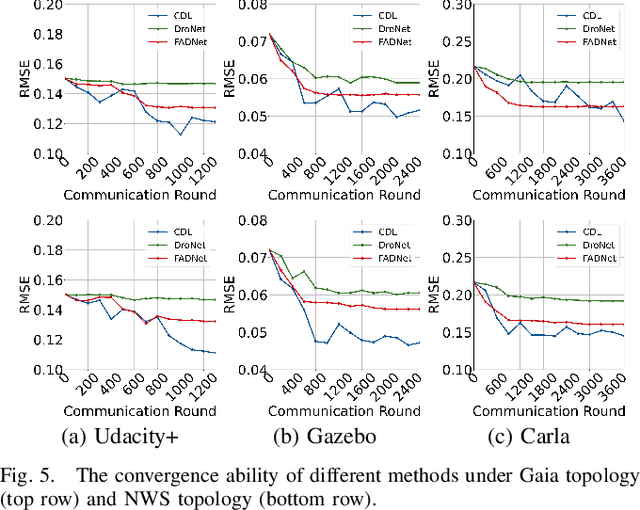
Mar 11, 2023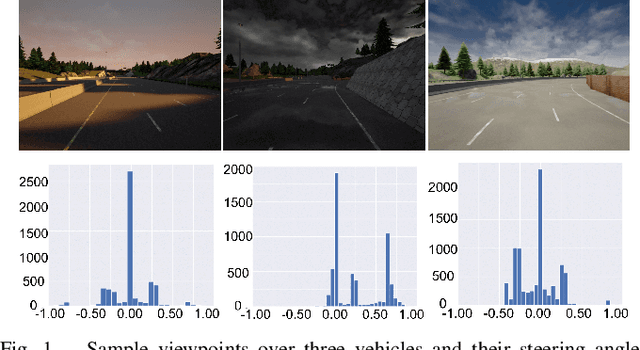
Federated learning has been widely applied in autonomous driving since it enables training a learning model among vehicles without sharing users' data. However, data from autonomous vehicles usually suffer from the non-independent-and-identically-distributed (non-IID) problem, which may cause negative effects on the convergence of the learning process. In this paper, we propose a new contrastive divergence loss to address the non-IID problem in autonomous driving by reducing the impact of divergence factors from transmitted models during the local learning process of each silo. We also analyze the effects of contrastive divergence in various autonomous driving scenarios, under multiple network infrastructures, and with different centralized/distributed learning schemes. Our intensive experiments on three datasets demonstrate that our proposed contrastive divergence loss further improves the performance over current state-of-the-art approaches.
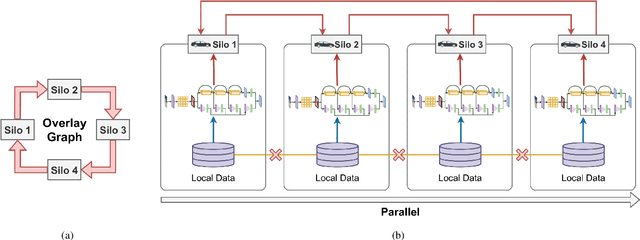
Multigraph Topology Design for Cross-Silo Federated Learning
Jul 21, 2022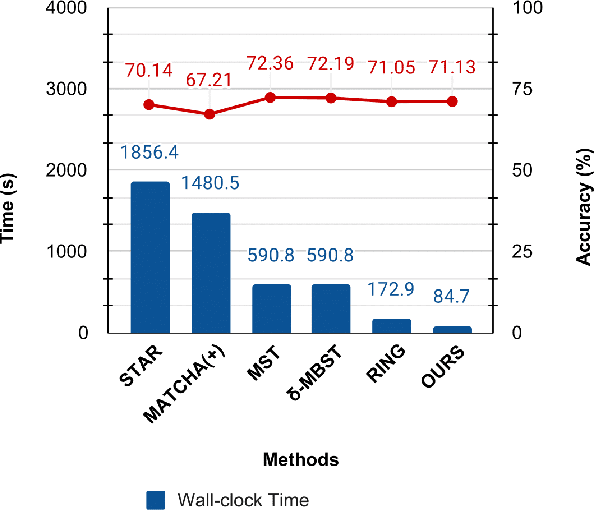
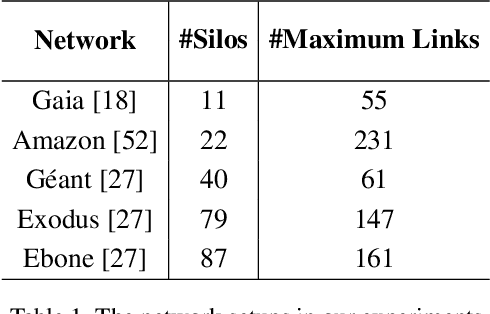
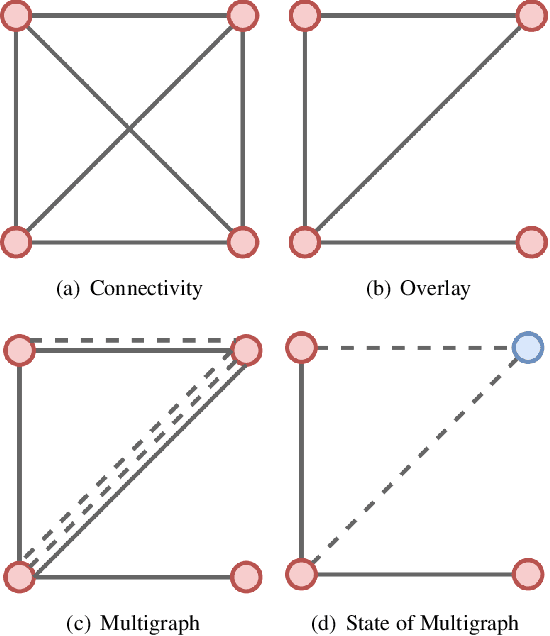
Cross-silo federated learning utilizes a few hundred reliable data silos with high-speed access links to jointly train a model. While this approach becomes a popular setting in federated learning, designing a robust topology to reduce the training time is still an open problem. In this paper, we present a new multigraph topology for cross-silo federated learning. We first construct the multigraph using the overlay graph. We then parse this multigraph into different simple graphs with isolated nodes. The existence of isolated nodes allows us to perform model aggregation without waiting for other nodes, hence reducing the training time. We further propose a new distributed learning algorithm to use with our multigraph topology. The intensive experiments on public datasets show that our proposed method significantly reduces the training time compared with recent state-of-the-art topologies while ensuring convergence and maintaining the model's accuracy.
Deep Federated Learning for Autonomous Driving
Oct 12, 2021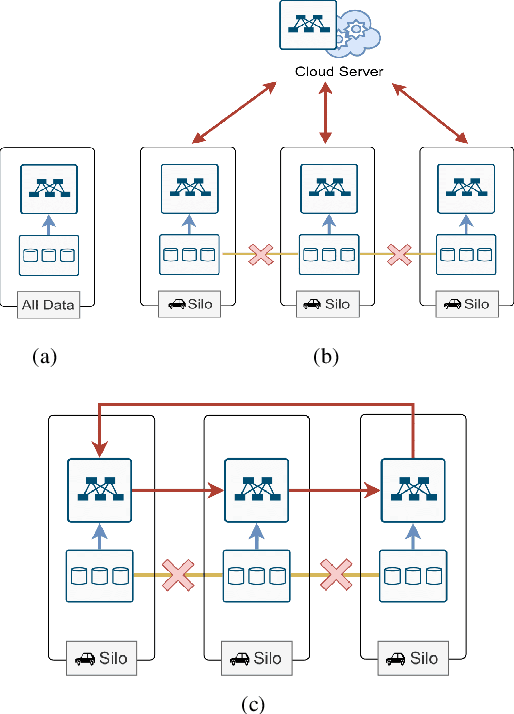
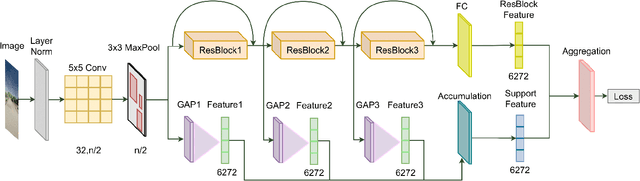

Autonomous driving is an active research topic in both academia and industry. However, most of the existing solutions focus on improving the accuracy by training learnable models with centralized large-scale data. Therefore, these methods do not take into account the user's privacy. In this paper, we present a new approach to learn autonomous driving policy while respecting privacy concerns. We propose a peer-to-peer Deep Federated Learning (DFL) approach to train deep architectures in a fully decentralized manner and remove the need for central orchestration. We design a new Federated Autonomous Driving network (FADNet) that can improve the model stability, ensure convergence, and handle imbalanced data distribution problems while is being trained with federated learning methods. Intensively experimental results on three datasets show that our approach with FADNet and DFL achieves superior accuracy compared with other recent methods. Furthermore, our approach can maintain privacy by not collecting user data to a central server.
Coarse-to-Fine Reasoning for Visual Question Answering
Oct 06, 2021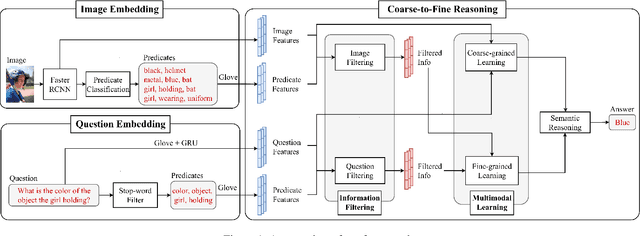
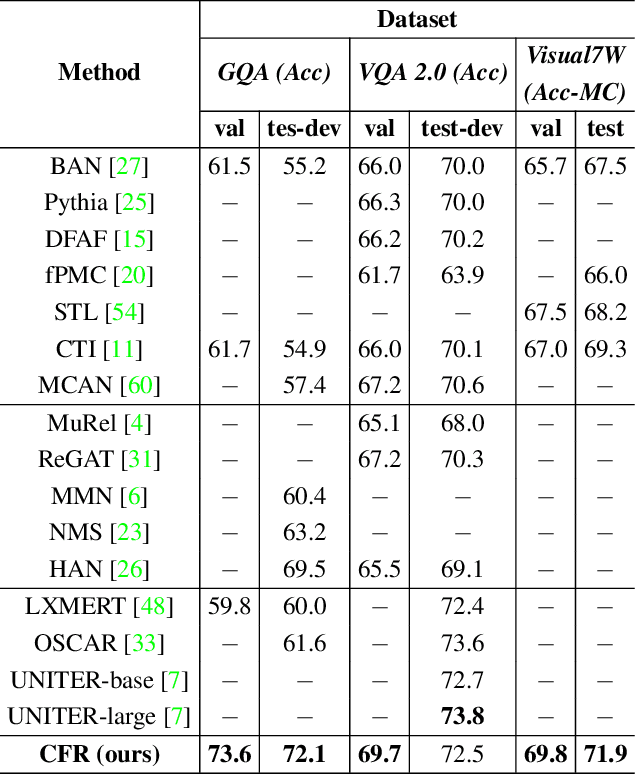
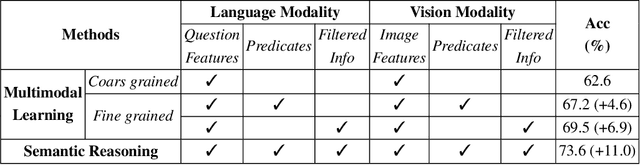
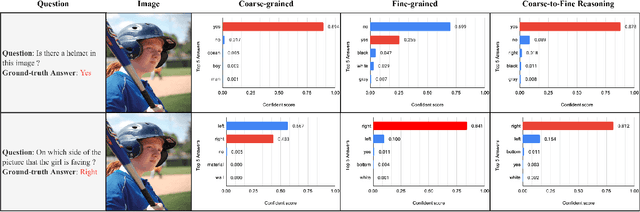
Bridging the semantic gap between image and question is an important step to improve the accuracy of the Visual Question Answering (VQA) task. However, most of the existing VQA methods focus on attention mechanisms or visual relations for reasoning the answer, while the features at different semantic levels are not fully utilized. In this paper, we present a new reasoning framework to fill the gap between visual features and semantic clues in the VQA task. Our method first extracts the features and predicates from the image and question. We then propose a new reasoning framework to effectively jointly learn these features and predicates in a coarse-to-fine manner. The intensively experimental results on three large-scale VQA datasets show that our proposed approach achieves superior accuracy comparing with other state-of-the-art methods. Furthermore, our reasoning framework also provides an explainable way to understand the decision of the deep neural network when predicting the answer.
Multiple Meta-model Quantifying for Medical Visual Question Answering
May 19, 2021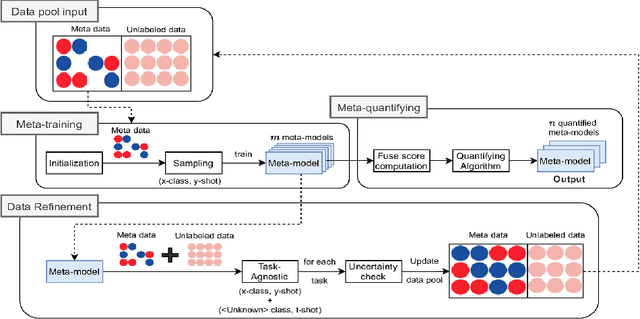
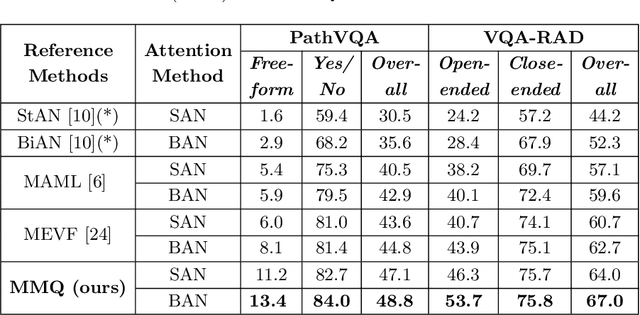
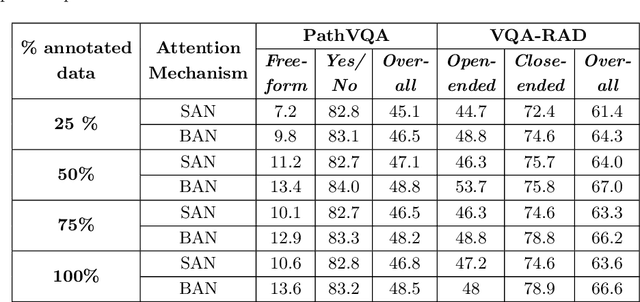
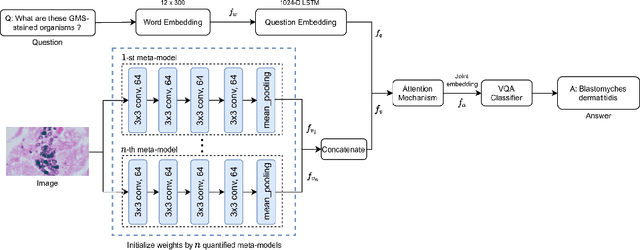
Transfer learning is an important step to extract meaningful features and overcome the data limitation in the medical Visual Question Answering (VQA) task. However, most of the existing medical VQA methods rely on external data for transfer learning, while the meta-data within the dataset is not fully utilized. In this paper, we present a new multiple meta-model quantifying method that effectively learns meta-annotation and leverages meaningful features to the medical VQA task. Our proposed method is designed to increase meta-data by auto-annotation, deal with noisy labels, and output meta-models which provide robust features for medical VQA tasks. Extensively experimental results on two public medical VQA datasets show that our approach achieves superior accuracy in comparison with other state-of-the-art methods, while does not require external data to train meta-models.
Graph-based Person Signature for Person Re-Identifications
Apr 17, 2021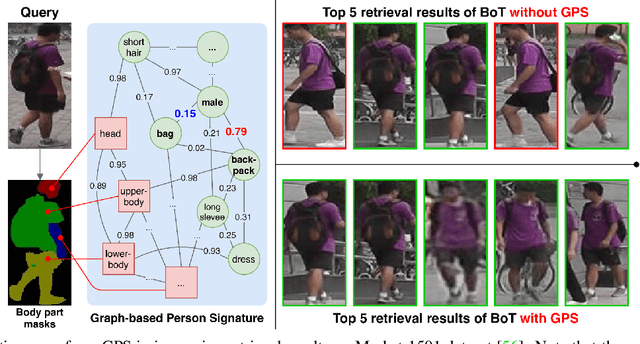


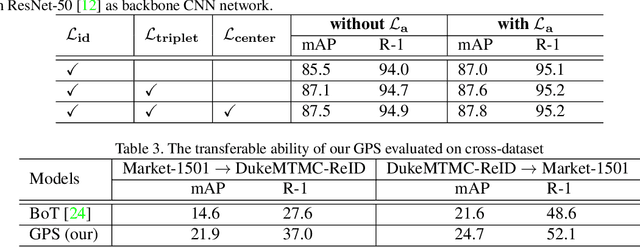
The task of person re-identification (ReID) is to match images of the same person over multiple non-overlapping camera views. Due to the variations in visual factors, previous works have investigated how the person identity, body parts, and attributes benefit the person ReID problem. However, the correlations between attributes, body parts, and within each attribute are not fully utilized. In this paper, we propose a new method to effectively aggregate detailed person descriptions (attributes labels) and visual features (body parts and global features) into a graph, namely Graph-based Person Signature, and utilize Graph Convolutional Networks to learn the topological structure of the visual signature of a person. The graph is integrated into a multi-branch multi-task framework for person re-identification. The extensive experiments are conducted to demonstrate the effectiveness of our proposed approach on two large-scale datasets, including Market-1501 and DukeMTMC-ReID. Our approach achieves competitive results among the state of the art and outperforms other attribute-based or mask-guided methods.
Multiple interaction learning with question-type prior knowledge for constraining answer search space in visual question answering
Sep 23, 2020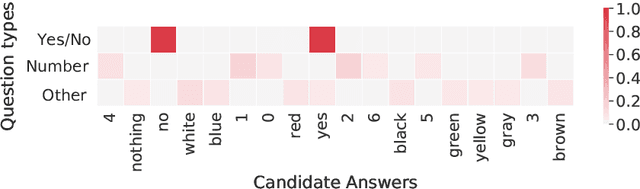



Different approaches have been proposed to Visual Question Answering (VQA). However, few works are aware of the behaviors of varying joint modality methods over question type prior knowledge extracted from data in constraining answer search space, of which information gives a reliable cue to reason about answers for questions asked in input images. In this paper, we propose a novel VQA model that utilizes the question-type prior information to improve VQA by leveraging the multiple interactions between different joint modality methods based on their behaviors in answering questions from different types. The solid experiments on two benchmark datasets, i.e., VQA 2.0 and TDIUC, indicate that the proposed method yields the best performance with the most competitive approaches.
Deep Metric Learning Meets Deep Clustering: An Novel Unsupervised Approach for Feature Embedding
Sep 09, 2020



Unsupervised Deep Distance Metric Learning (UDML) aims to learn sample similarities in the embedding space from an unlabeled dataset. Traditional UDML methods usually use the triplet loss or pairwise loss which requires the mining of positive and negative samples w.r.t. anchor data points. This is, however, challenging in an unsupervised setting as the label information is not available. In this paper, we propose a new UDML method that overcomes that challenge. In particular, we propose to use a deep clustering loss to learn centroids, i.e., pseudo labels, that represent semantic classes. During learning, these centroids are also used to reconstruct the input samples. It hence ensures the representativeness of centroids - each centroid represents visually similar samples. Therefore, the centroids give information about positive (visually similar) and negative (visually dissimilar) samples. Based on pseudo labels, we propose a novel unsupervised metric loss which enforces the positive concentration and negative separation of samples in the embedding space. Experimental results on benchmarking datasets show that the proposed approach outperforms other UDML methods.
Overcoming Data Limitation in Medical Visual Question Answering
Sep 26, 2019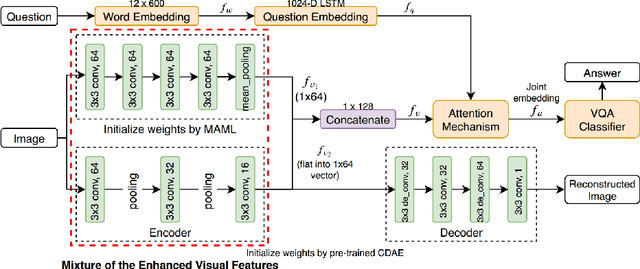
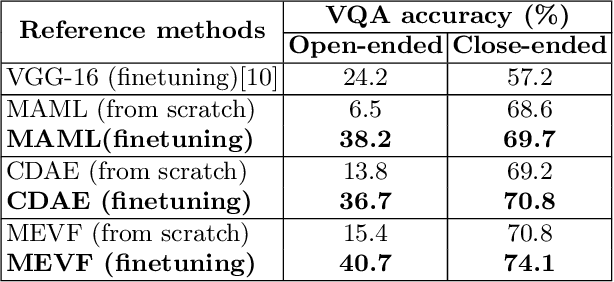

Traditional approaches for Visual Question Answering (VQA) require large amount of labeled data for training. Unfortunately, such large scale data is usually not available for medical domain. In this paper, we propose a novel medical VQA framework that overcomes the labeled data limitation. The proposed framework explores the use of the unsupervised Denoising Auto-Encoder (DAE) and the supervised Meta-Learning. The advantage of DAE is to leverage the large amount of unlabeled images while the advantage of Meta-Learning is to learn meta-weights that quickly adapt to VQA problem with limited labeled data. By leveraging the advantages of these techniques, it allows the proposed framework to be efficiently trained using a small labeled training set. The experimental results show that our proposed method significantly outperforms the state-of-the-art medical VQA.