 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Person Signature for Person Re-Identifications
Apr 17, 2021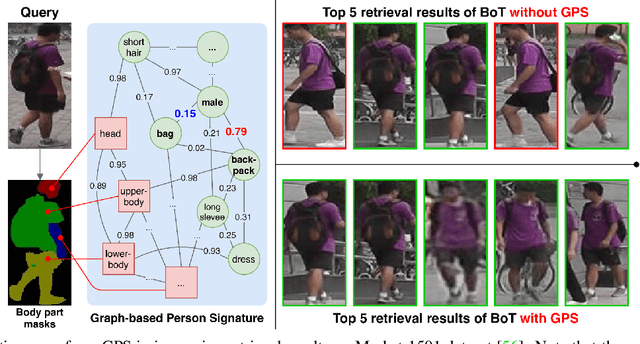


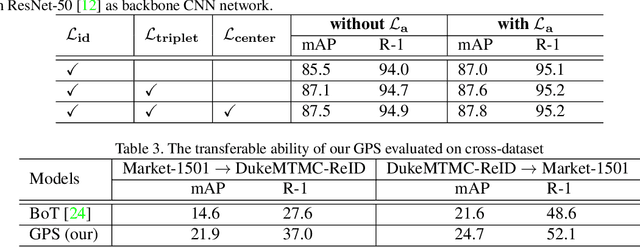
The task of person re-identification (ReID) is to match images of the same person over multiple non-overlapping camera views. Due to the variations in visual factors, previous works have investigated how the person identity, body parts, and attributes benefit the person ReID problem. However, the correlations between attributes, body parts, and within each attribute are not fully utilized. In this paper, we propose a new method to effectively aggregate detailed person descriptions (attributes labels) and visual features (body parts and global features) into a graph, namely Graph-based Person Signature, and utilize Graph Convolutional Networks to learn the topological structure of the visual signature of a person. The graph is integrated into a multi-branch multi-task framework for person re-identification. The extensive experiments are conducted to demonstrate the effectiveness of our proposed approach on two large-scale datasets, including Market-1501 and DukeMTMC-ReID. Our approach achieves competitive results among the state of the art and outperforms other attribute-based or mask-guided methods.
Deep Metric Learning Meets Deep Clustering: An Novel Unsupervised Approach for Feature Embedding
Sep 09, 2020



Unsupervised Deep Distance Metric Learning (UDML) aims to learn sample similarities in the embedding space from an unlabeled dataset. Traditional UDML methods usually use the triplet loss or pairwise loss which requires the mining of positive and negative samples w.r.t. anchor data points. This is, however, challenging in an unsupervised setting as the label information is not available. In this paper, we propose a new UDML method that overcomes that challenge. In particular, we propose to use a deep clustering loss to learn centroids, i.e., pseudo labels, that represent semantic classes. During learning, these centroids are also used to reconstruct the input samples. It hence ensures the representativeness of centroids - each centroid represents visually similar samples. Therefore, the centroids give information about positive (visually similar) and negative (visually dissimilar) samples. Based on pseudo labels, we propose a novel unsupervised metric loss which enforces the positive concentration and negative separation of samples in the embedding space. Experimental results on benchmarking datasets show that the proposed approach outperforms other UDML methods.
Overcoming Data Limitation in Medical Visual Question Answering
Sep 26, 2019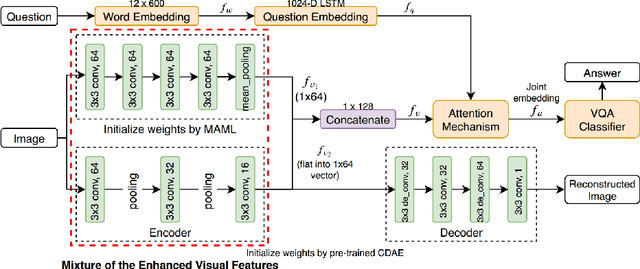
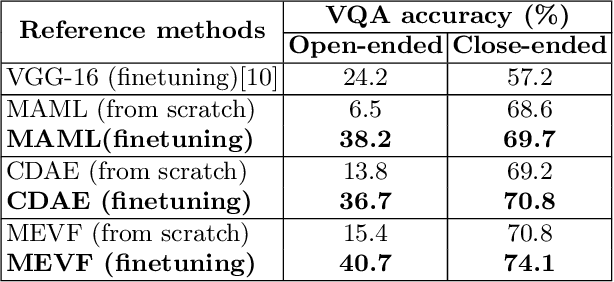

Traditional approaches for Visual Question Answering (VQA) require large amount of labeled data for training. Unfortunately, such large scale data is usually not available for medical domain. In this paper, we propose a novel medical VQA framework that overcomes the labeled data limitation. The proposed framework explores the use of the unsupervised Denoising Auto-Encoder (DAE) and the supervised Meta-Learning. The advantage of DAE is to leverage the large amount of unlabeled images while the advantage of Meta-Learning is to learn meta-weights that quickly adapt to VQA problem with limited labeled data. By leveraging the advantages of these techniques, it allows the proposed framework to be efficiently trained using a small labeled training set. The experimental results show that our proposed method significantly outperforms the state-of-the-art medical VQA.