 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpness-Aware Minimization in Logit Space Efficiently Enhances Direct Preference Optimization
Mar 18, 2026Direct Preference Optimization (DPO) has emerged as a popular algorithm for aligning pretrained large language models with human preferences, owing to its simplicity and training stability. However, DPO suffers from the recently identified squeezing effect (also known as likelihood displacement), where the probability of preferred responses decreases unintentionally during training. To understand and mitigate this phenomenon, we develop a theoretical framework that models the coordinate-wise dynamics in logit space. Our analysis reveals that negative-gradient updates cause residuals to expand rapidly along high-curvature directions, which underlies the squeezing effect, whereas Sharpness-Aware Minimization (SAM) can suppress this behavior through its curvature-regularization effect. Building on this insight, we investigate logits-SAM, a computationally efficient variant that perturbs only the output layer with negligible overhead. Extensive experiments on Pythia-2.8B, Mistral-7B, and Gemma-2B-IT across multiple datasets and benchmarks demonstrate that logits-SAM consistently improves the effectiveness of DPO and integrates seamlessly with other DPO variants. Code is available at https://github.com/RitianLuo/logits-sam-dpo.
Rethinking Output Alignment For 1-bit Post-Training Quantization of Large Language Models
Dec 25, 2025Large Language Models (LLMs) deliver strong performance across a wide range of NLP tasks, but their massive sizes hinder deployment on resource-constrained devices. To reduce their computational and memory burden, various compression techniques have been proposed, including quantization, pruning, and knowledge distillation. Among these, post-training quantization (PTQ) is widely adopted for its efficiency, as it requires no retraining and only a small dataset for calibration, enabling low-cost deployment. Recent advances for post-training quantization have demonstrated that even sub-4-bit methods can maintain most of the original model performance. However, 1-bit quantization that converts floating-point weights to \(\pm\)1, remains particularly challenging, as existing 1-bit PTQ methods often suffer from significant performance degradation compared to the full-precision models. Specifically, most of existing 1-bit PTQ approaches focus on weight alignment, aligning the full-precision model weights with those of the quantized models, rather than directly aligning their outputs. Although the output-matching approach objective is more intuitive and aligns with the quantization goal, naively applying it in 1-bit LLMs often leads to notable performance degradation. In this paper, we investigate why and under what conditions output-matching fails, in the context of 1-bit LLM quantization. Based on our findings, we propose a novel data-aware PTQ approach for 1-bit LLMs that explicitly accounts for activation error accumulation while keeping optimization efficient. Empirical experiments demonstrate that our solution consistently outperforms existing 1-bit PTQ methods with minimal overhead.
Sharpness-Aware Data Generation for Zero-shot Quantization
Oct 08, 2025Zero-shot quantization aims to learn a quantized model from a pre-trained full-precision model with no access to original real training data. The common idea in zero-shot quantization approaches is to generate synthetic data for quantizing the full-precision model. While it is well-known that deep neural networks with low sharpness have better generalization ability, none of the previous zero-shot quantization works considers the sharpness of the quantized model as a criterion for generating training data. This paper introduces a novel methodology that takes into account quantized model sharpness in synthetic data generation to enhance generalization. Specifically, we first demonstrate that sharpness minimization can be attained by maximizing gradient matching between the reconstruction loss gradients computed on synthetic and real validation data, under certain assumptions. We then circumvent the problem of the gradient matching without real validation set by approximating it with the gradient matching between each generated sample and its neighbors. Experimental evaluations on CIFAR-100 and ImageNet datasets demonstrate the superiority of the proposed method over the state-of-the-art techniques in low-bit quantization settings.
Preserving Clusters in Prompt Learning for Unsupervised Domain Adaptation
Jun 13, 2025Recent approaches leveraging multi-modal pre-trained models like CLIP for Unsupervised Domain Adaptation (UDA) have shown significant promise in bridging domain gaps and improving generalization by utilizing rich semantic knowledge and robust visual representations learned through extensive pre-training on diverse image-text datasets. While these methods achieve state-of-the-art performance across benchmarks, much of the improvement stems from base pseudo-labels (CLIP zero-shot predictions) and self-training mechanisms. Thus, the training mechanism exhibits a key limitation wherein the visual embedding distribution in target domains can deviate from the visual embedding distribution in the pre-trained model, leading to misguided signals from class descriptions. This work introduces a fresh solution to reinforce these pseudo-labels and facilitate target-prompt learning, by exploiting the geometry of visual and text embeddings - an aspect that is overlooked by existing methods. We first propose to directly leverage the reference predictions (from source prompts) based on the relationship between source and target visual embeddings. We later show that there is a strong clustering behavior observed between visual and text embeddings in pre-trained multi-modal models. Building on optimal transport theory, we transform this insight into a novel strategy to enforce the clustering property in text embeddings, further enhancing the alignment in the target domain. Our experiments and ablation studies validate the effectiveness of the proposed approach, demonstrating superior performance and improved quality of target prompts in terms of representation.
Optimizing Specific and Shared Parameters for Efficient Parameter Tuning
Apr 04, 2025Foundation models, with a vast number of parameters and pretraining on massive datasets, achieve state-of-the-art performance across various applications. However, efficiently adapting them to downstream tasks with minimal computational overhead remains a challenge. Parameter-Efficient Transfer Learning (PETL) addresses this by fine-tuning only a small subset of parameters while preserving pre-trained knowledge. In this paper, we propose SaS, a novel PETL method that effectively mitigates distributional shifts during fine-tuning. SaS integrates (1) a shared module that captures common statistical characteristics across layers using low-rank projections and (2) a layer-specific module that employs hypernetworks to generate tailored parameters for each layer. This dual design ensures an optimal balance between performance and parameter efficiency while introducing less than 0.05% additional parameters, making it significantly more compact than existing methods. Extensive experiments on diverse downstream tasks, few-shot settings and domain generalization demonstrate that SaS significantly enhances performance while maintaining superior parameter efficiency compared to existing methods, highlighting the importance of capturing both shared and layer-specific information in transfer learning. Code and data are available at https://anonymous.4open.science/r/SaS-PETL-3565.
Multi-Perspective Data Augmentation for Few-shot Object Detection
Feb 25, 2025Recent few-shot object detection (FSOD) methods have focused on augmenting synthetic samples for novel classes, show promising results to the rise of diffusion models. However, the diversity of such datasets is often limited in representativeness because they lack awareness of typical and hard samples, especially in the context of foreground and background relationships. To tackle this issue, we propose a Multi-Perspective Data Augmentation (MPAD) framework. In terms of foreground-foreground relationships, we propose in-context learning for object synthesis (ICOS) with bounding box adjustments to enhance the detail and spatial information of synthetic samples. Inspired by the large margin principle, support samples play a vital role in defining class boundaries. Therefore, we design a Harmonic Prompt Aggregation Scheduler (HPAS) to mix prompt embeddings at each time step of the generation process in diffusion models, producing hard novel samples. For foreground-background relationships, we introduce a Background Proposal method (BAP) to sample typical and hard backgrounds. Extensive experiments on multiple FSOD benchmarks demonstrate the effectiveness of our approach. Our framework significantly outperforms traditional methods, achieving an average increase of $17.5\%$ in nAP50 over the baseline on PASCAL VOC. Code is available at https://github.com/nvakhoa/MPAD.
Coverage-Constrained Human-AI Cooperation with Multiple Experts
Nov 18, 2024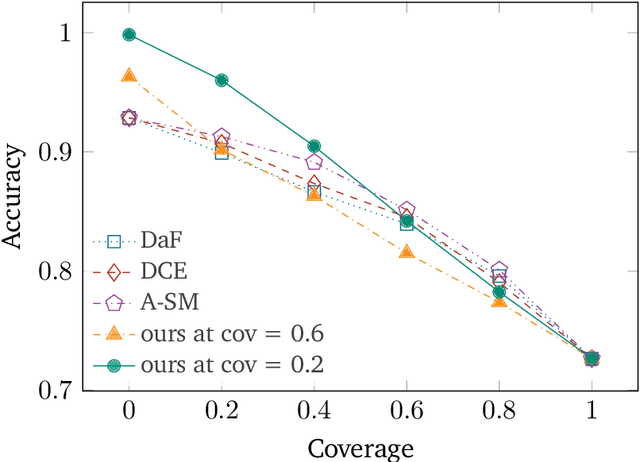

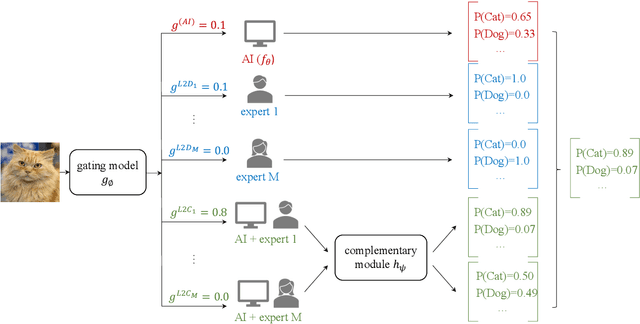
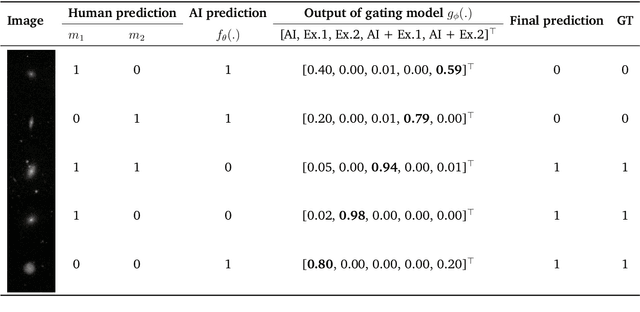
Human-AI cooperative classification (HAI-CC) approaches aim to develop hybrid intelligent systems that enhance decision-making in various high-stakes real-world scenarios by leveraging both human expertise and AI capabilities. Current HAI-CC methods primarily focus on learning-to-defer (L2D), where decisions are deferred to human experts, and learning-to-complement (L2C), where AI and human experts make predictions cooperatively. However, a notable research gap remains in effectively exploring both L2D and L2C under diverse expert knowledge to improve decision-making, particularly when constrained by the cooperation cost required to achieve a target probability for AI-only selection (i.e., coverage). In this paper, we address this research gap by proposing the Coverage-constrained Learning to Defer and Complement with Specific Experts (CL2DC) method. CL2DC makes final decisions through either AI prediction alone or by deferring to or complementing a specific expert, depending on the input data. Furthermore, we propose a coverage-constrained optimisation to control the cooperation cost, ensuring it approximates a target probability for AI-only selection. This approach enables an effective assessment of system performance within a specified budget. Also, CL2DC is designed to address scenarios where training sets contain multiple noisy-label annotations without any clean-label references. Comprehensive evaluations on both synthetic and real-world datasets demonstrate that CL2DC achieves superior performance compared to state-of-the-art HAI-CC methods.
Fair Distillation: Teaching Fairness from Biased Teachers in Medical Imaging
Nov 18, 2024



Deep learning has achieved remarkable success in image classification and segmentation tasks. However, fairness concerns persist, as models often exhibit biases that disproportionately affect demographic groups defined by sensitive attributes such as race, gender, or age. Existing bias-mitigation techniques, including Subgroup Re-balancing, Adversarial Training, and Domain Generalization, aim to balance accuracy across demographic groups, but often fail to simultaneously improve overall accuracy, group-specific accuracy, and fairness due to conflicts among these interdependent objectives. We propose the Fair Distillation (FairDi) method, a novel fairness approach that decomposes these objectives by leveraging biased ``teacher'' models, each optimized for a specific demographic group. These teacher models then guide the training of a unified ``student'' model, which distills their knowledge to maximize overall and group-specific accuracies, while minimizing inter-group disparities. Experiments on medical imaging datasets show that FairDi achieves significant gains in both overall and group-specific accuracy, along with improved fairness, compared to existing methods. FairDi is adaptable to various medical tasks, such as classification and segmentation, and provides an effective solution for equitable model performance.
Self-supervised Learning for Acoustic Few-Shot Classification
Sep 15, 2024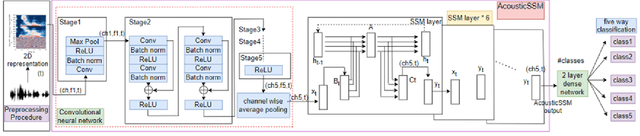
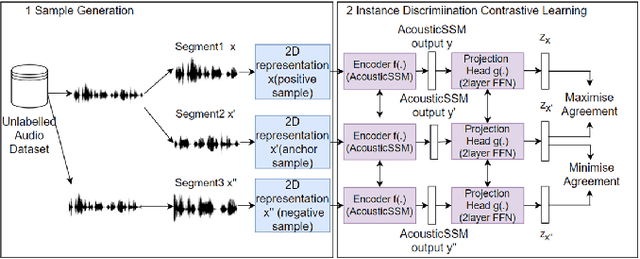

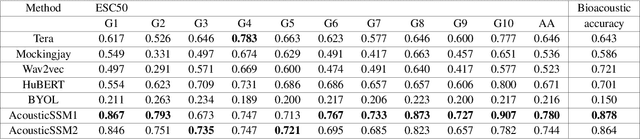
Labelled data are limited and self-supervised learning is one of the most important approaches for reducing labelling requirements. While it has been extensively explored in the image domain, it has so far not received the same amount of attention in the acoustic domain. Yet, reducing labelling is a key requirement for many acoustic applications. Specifically in bioacoustic, there are rarely sufficient labels for fully supervised learning available. This has led to the widespread use of acoustic recognisers that have been pre-trained on unrelated data for bioacoustic tasks. We posit that training on the actual task data and combining self-supervised pre-training with few-shot classification is a superior approach that has the ability to deliver high accuracy even when only a few labels are available. To this end, we introduce and evaluate a new architecture that combines CNN-based preprocessing with feature extraction based on state space models (SSMs). This combination is motivated by the fact that CNN-based networks alone struggle to capture temporal information effectively, which is crucial for classifying acoustic signals. SSMs, specifically S4 and Mamba, on the other hand, have been shown to have an excellent ability to capture long-range dependencies in sequence data. We pre-train this architecture using contrastive learning on the actual task data and subsequent fine-tuning with an extremely small amount of labelled data. We evaluate the performance of this proposed architecture for ($n$-shot, $n$-class) classification on standard benchmarks as well as real-world data. Our evaluation shows that it outperforms state-of-the-art architectures on the few-shot classification problem.
Connective Viewpoints of Signal-to-Noise Diffusion Models
Aug 08, 2024



Diffusion models (DM) have become fundamental components of generative models, excelling across various domains such as image creation, audio generation, and complex data interpolation. Signal-to-Noise diffusion models constitute a diverse family covering most state-of-the-art diffusion models. While there have been several attempts to study Signal-to-Noise (S2N) diffusion models from various perspectives, there remains a need for a comprehensive study connecting different viewpoints and exploring new perspectives. In this study, we offer a comprehensive perspective on noise schedulers, examining their role through the lens of the signal-to-noise ratio (SNR) and its connections to information theory. Building upon this framework, we have developed a generalized backward equation to enhance the performance of the inference process.