 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Re-ranking Method using K-nearest Weighted Fusion for Person Re-identification
Sep 04, 2025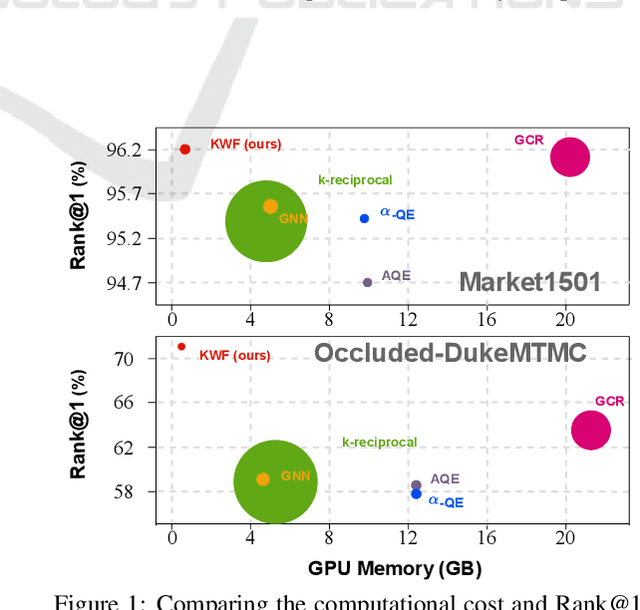
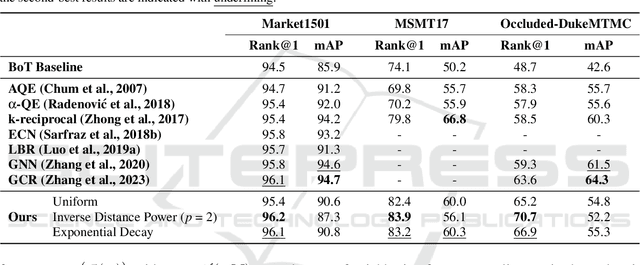

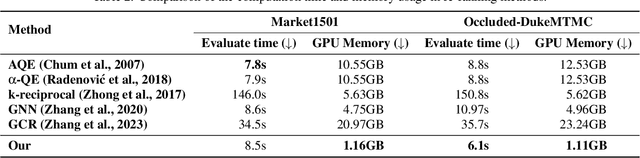
In person re-identification, re-ranking is a crucial step to enhance the overall accuracy by refining the initial ranking of retrieved results. Previous studies have mainly focused on features from single-view images, which can cause view bias and issues like pose variation, viewpoint changes, and occlusions. Using multi-view features to present a person can help reduce view bias. In this work, we present an efficient re-ranking method that generates multi-view features by aggregating neighbors' features using K-nearest Weighted Fusion (KWF) method. Specifically, we hypothesize that features extracted from re-identification models are highly similar when representing the same identity. Thus, we select K neighboring features in an unsupervised manner to generate multi-view features. Additionally, this study explores the weight selection strategies during feature aggregation, allowing us to identify an effective strategy. Our re-ranking approach does not require model fine-tuning or extra annotations, making it applicable to large-scale datasets. We evaluate our method on the person re-identification datasets Market1501, MSMT17, and Occluded-DukeMTMC. The results show that our method significantly improves Rank@1 and mAP when re-ranking the top M candidates from the initial ranking results. Specifically, compared to the initial results, our re-ranking method achieves improvements of 9.8%/22.0% in Rank@1 on the challenging datasets: MSMT17 and Occluded-DukeMTMC, respectively. Furthermore, our approach demonstrates substantial enhancements in computational efficiency compared to other re-ranking methods.
* Published in ICPRAM 2025, ISBN 978-989-758-730-6, ISSN 2184-4313
SHREC 2025: Retrieval of Optimal Objects for Multi-modal Enhanced Language and Spatial Assistance (ROOMELSA)
Aug 12, 2025Recent 3D retrieval systems are typically designed for simple, controlled scenarios, such as identifying an object from a cropped image or a brief description. However, real-world scenarios are more complex, often requiring the recognition of an object in a cluttered scene based on a vague, free-form description. To this end, we present ROOMELSA, a new benchmark designed to evaluate a system's ability to interpret natural language. Specifically, ROOMELSA attends to a specific region within a panoramic room image and accurately retrieves the corresponding 3D model from a large database. In addition, ROOMELSA includes over 1,600 apartment scenes, nearly 5,200 rooms, and more than 44,000 targeted queries. Empirically, while coarse object retrieval is largely solved, only one top-performing model consistently ranked the correct match first across nearly all test cases. Notably, a lightweight CLIP-based model also performed well, although it struggled with subtle variations in materials, part structures, and contextual cues, resulting in occasional errors. These findings highlight the importance of tightly integrating visual and language understanding. By bridging the gap between scene-level grounding and fine-grained 3D retrieval, ROOMELSA establishes a new benchmark for advancing robust, real-world 3D recognition systems.
FaR: Enhancing Multi-Concept Text-to-Image Diffusion via Concept Fusion and Localized Refinement
Apr 04, 2025Generating multiple new concepts remains a challenging problem in the text-to-image task. Current methods often overfit when trained on a small number of samples and struggle with attribute leakage, particularly for class-similar subjects (e.g., two specific dogs). In this paper, we introduce Fuse-and-Refine (FaR), a novel approach that tackles these challenges through two key contributions: Concept Fusion technique and Localized Refinement loss function. Concept Fusion systematically augments the training data by separating reference subjects from backgrounds and recombining them into composite images to increase diversity. This augmentation technique tackles the overfitting problem by mitigating the narrow distribution of the limited training samples. In addition, Localized Refinement loss function is introduced to preserve subject representative attributes by aligning each concept's attention map to its correct region. This approach effectively prevents attribute leakage by ensuring that the diffusion model distinguishes similar subjects without mixing their attention maps during the denoising process. By fine-tuning specific modules at the same time, FaR balances the learning of new concepts with the retention of previously learned knowledge. Empirical results show that FaR not only prevents overfitting and attribute leakage while maintaining photorealism, but also outperforms other state-of-the-art methods.
Multi-Perspective Data Augmentation for Few-shot Object Detection
Feb 25, 2025Recent few-shot object detection (FSOD) methods have focused on augmenting synthetic samples for novel classes, show promising results to the rise of diffusion models. However, the diversity of such datasets is often limited in representativeness because they lack awareness of typical and hard samples, especially in the context of foreground and background relationships. To tackle this issue, we propose a Multi-Perspective Data Augmentation (MPAD) framework. In terms of foreground-foreground relationships, we propose in-context learning for object synthesis (ICOS) with bounding box adjustments to enhance the detail and spatial information of synthetic samples. Inspired by the large margin principle, support samples play a vital role in defining class boundaries. Therefore, we design a Harmonic Prompt Aggregation Scheduler (HPAS) to mix prompt embeddings at each time step of the generation process in diffusion models, producing hard novel samples. For foreground-background relationships, we introduce a Background Proposal method (BAP) to sample typical and hard backgrounds. Extensive experiments on multiple FSOD benchmarks demonstrate the effectiveness of our approach. Our framework significantly outperforms traditional methods, achieving an average increase of $17.5\%$ in nAP50 over the baseline on PASCAL VOC. Code is available at https://github.com/nvakhoa/MPAD.
Enhanced Generative Data Augmentation for Semantic Segmentation via Stronger Guidance
Sep 09, 2024Data augmentation is a widely used technique for creating training data for tasks that require labeled data, such as semantic segmentation. This method benefits pixel-wise annotation tasks requiring much effort and intensive labor. Traditional data augmentation methods involve simple transformations like rotations and flips to create new images from existing ones. However, these new images may lack diversity along the main semantic axes in the data and not change high-level semantic properties. To address this issue, generative models have emerged as an effective solution for augmenting data by generating synthetic images. Controllable generative models offer a way to augment data for semantic segmentation tasks using a prompt and visual reference from the original image. However, using these models directly presents challenges, such as creating an effective prompt and visual reference to generate a synthetic image that accurately reflects the content and structure of the original. In this work, we introduce an effective data augmentation method for semantic segmentation using the Controllable Diffusion Model. Our proposed method includes efficient prompt generation using Class-Prompt Appending and Visual Prior Combination to enhance attention to labeled classes in real images. These techniques allow us to generate images that accurately depict segmented classes in the real image. In addition, we employ the class balancing algorithm to ensure efficiency when merging the synthetic and original images to generate balanced data for the training dataset. We evaluated our method on the PASCAL VOC datasets and found it highly effective for synthesizing images in semantic segmentation.
Enhancing Person Re-Identification via Uncertainty Feature Fusion and Wise Distance Aggregation
May 02, 2024The quest for robust Person re-identification (Re-ID) systems capable of accurately identifying subjects across diverse scenarios remains a formidable challenge in surveillance and security applications. This study presents a novel methodology that significantly enhances Person Re-Identification (Re-ID) by integrating Uncertainty Feature Fusion (UFFM) with Wise Distance Aggregation (WDA). Tested on benchmark datasets - Market-1501, DukeMTMC-ReID, and MSMT17 - our approach demonstrates substantial improvements in Rank-1 accuracy and mean Average Precision (mAP). Specifically, UFFM capitalizes on the power of feature synthesis from multiple images to overcome the limitations imposed by the variability of subject appearances across different views. WDA further refines the process by intelligently aggregating similarity metrics, thereby enhancing the system's ability to discern subtle but critical differences between subjects. The empirical results affirm the superiority of our method over existing approaches, achieving new performance benchmarks across all evaluated datasets. Code is available on Github.
TwinLiteNetPlus: A Stronger Model for Real-time Drivable Area and Lane Segmentation
Mar 25, 2024Semantic segmentation is crucial for autonomous driving, particularly for Drivable Area and Lane Segmentation, ensuring safety and navigation. To address the high computational costs of current state-of-the-art (SOTA) models, this paper introduces TwinLiteNetPlus (TwinLiteNet$^+$), a model adept at balancing efficiency and accuracy. TwinLiteNet$^+$ incorporates standard and depth-wise separable dilated convolutions, reducing complexity while maintaining high accuracy. It is available in four configurations, from the robust 1.94 million-parameter TwinLiteNet$^+_{\text{Large}}$ to the ultra-compact 34K-parameter TwinLiteNet$^+_{\text{Nano}}$. Notably, TwinLiteNet$^+_{\text{Large}}$ attains a 92.9\% mIoU for Drivable Area Segmentation and a 34.2\% IoU for Lane Segmentation. These results notably outperform those of current SOTA models while requiring a computational cost that is approximately 11 times lower in terms of Floating Point Operations (FLOPs) compared to the existing SOTA model. Extensively tested on various embedded devices, TwinLiteNet$^+$ demonstrates promising latency and power efficiency, underscoring its suitability for real-world autonomous vehicle applications.
Efficient Finetuning Large Language Models For Vietnamese Chatbot
Sep 09, 2023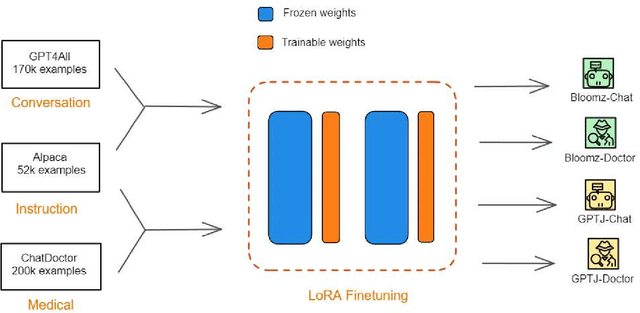

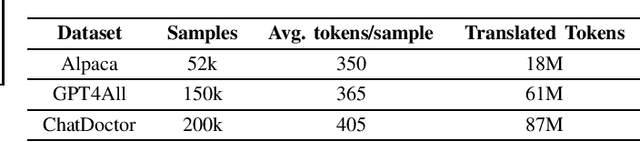
Large language models (LLMs), such as GPT-4, PaLM, and LLaMa, have been shown to achieve remarkable performance across a variety of natural language tasks. Recent advancements in instruction tuning bring LLMs with ability in following user's instructions and producing human-like responses. However, the high costs associated with training and implementing LLMs pose challenges to academic research. Furthermore, the availability of pretrained LLMs and instruction-tune datasets for Vietnamese language is limited. To tackle these concerns, we leverage large-scale instruction-following datasets from open-source projects, namely Alpaca, GPT4All, and Chat-Doctor, which cover general domain and specific medical domain. To the best of our knowledge, these are the first instructional dataset for Vietnamese. Subsequently, we utilize parameter-efficient tuning through Low-Rank Adaptation (LoRA) on two open LLMs: Bloomz (Multilingual) and GPTJ-6B (Vietnamese), resulting four models: Bloomz-Chat, Bloomz-Doctor, GPTJ-Chat, GPTJ-Doctor.Finally, we assess the effectiveness of our methodology on a per-sample basis, taking into consideration the helpfulness, relevance, accuracy, level of detail in their responses. This evaluation process entails the utilization of GPT-4 as an automated scoring mechanism. Despite utilizing a low-cost setup, our method demonstrates about 20-30\% improvement over the original models in our evaluation tasks.
Few-Shot Object Detection via Synthetic Features with Optimal Transport
Aug 30, 2023



Few-shot object detection aims to simultaneously localize and classify the objects in an image with limited training samples. However, most existing few-shot object detection methods focus on extracting the features of a few samples of novel classes that lack diversity. Hence, they may not be sufficient to capture the data distribution. To address that limitation, in this paper, we propose a novel approach in which we train a generator to generate synthetic data for novel classes. Still, directly training a generator on the novel class is not effective due to the lack of novel data. To overcome that issue, we leverage the large-scale dataset of base classes. Our overarching goal is to train a generator that captures the data variations of the base dataset. We then transform the captured variations into novel classes by generating synthetic data with the trained generator. To encourage the generator to capture data variations on base classes, we propose to train the generator with an optimal transport loss that minimizes the optimal transport distance between the distributions of real and synthetic data. Extensive experiments on two benchmark datasets demonstrate that the proposed method outperforms the state of the art. Source code will be available.
Few-shot Camouflaged Animal Detection and Segmentation
Apr 15, 2023



Camouflaged object detection and segmentation is a new and challenging research topic in computer vision. There is a serious issue of lacking data of camouflaged objects such as camouflaged animals in natural scenes. In this paper, we address the problem of few-shot learning for camouflaged object detection and segmentation. To this end, we first collect a new dataset, CAMO-FS, for the benchmark. We then propose a novel method to efficiently detect and segment the camouflaged objects in the images. In particular, we introduce the instance triplet loss and the instance memory storage. The extensive experiments demonstrated that our proposed method achieves state-of-the-art performance on the newly collected dataset.