 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViMultiChoice: Toward a Method That Gives Explanation for Multiple-Choice Reading Comprehension in Vietnamese
Feb 10, 2026Multiple-choice Reading Comprehension (MCRC) models aim to select the correct answer from a set of candidate options for a given question. However, they typically lack the ability to explain the reasoning behind their choices. In this paper, we introduce a novel Vietnamese dataset designed to train and evaluate MCRC models with explanation generation capabilities. Furthermore, we propose ViMultiChoice, a new method specifically designed for modeling Vietnamese reading comprehension that jointly predicts the correct answer and generates a corresponding explanation. Experimental results demonstrate that ViMultiChoice outperforms existing MCRC baselines, achieving state-of-the-art (SotA) performance on both the ViMMRC 2.0 benchmark and the newly introduced dataset. Additionally, we show that jointly training option decision and explanation generation leads to significant improvements in multiple-choice accuracy.
SHREC 2025: Retrieval of Optimal Objects for Multi-modal Enhanced Language and Spatial Assistance (ROOMELSA)
Aug 12, 2025Recent 3D retrieval systems are typically designed for simple, controlled scenarios, such as identifying an object from a cropped image or a brief description. However, real-world scenarios are more complex, often requiring the recognition of an object in a cluttered scene based on a vague, free-form description. To this end, we present ROOMELSA, a new benchmark designed to evaluate a system's ability to interpret natural language. Specifically, ROOMELSA attends to a specific region within a panoramic room image and accurately retrieves the corresponding 3D model from a large database. In addition, ROOMELSA includes over 1,600 apartment scenes, nearly 5,200 rooms, and more than 44,000 targeted queries. Empirically, while coarse object retrieval is largely solved, only one top-performing model consistently ranked the correct match first across nearly all test cases. Notably, a lightweight CLIP-based model also performed well, although it struggled with subtle variations in materials, part structures, and contextual cues, resulting in occasional errors. These findings highlight the importance of tightly integrating visual and language understanding. By bridging the gap between scene-level grounding and fine-grained 3D retrieval, ROOMELSA establishes a new benchmark for advancing robust, real-world 3D recognition systems.
Coreference Resolution for Vietnamese Narrative Texts
Apr 28, 2025Coreference resolution is a vital task in natural language processing (NLP) that involves identifying and linking different expressions in a text that refer to the same entity. This task is particularly challenging for Vietnamese, a low-resource language with limited annotated datasets. To address these challenges, we developed a comprehensive annotated dataset using narrative texts from VnExpress, a widely-read Vietnamese online news platform. We established detailed guidelines for annotating entities, focusing on ensuring consistency and accuracy. Additionally, we evaluated the performance of large language models (LLMs), specifically GPT-3.5-Turbo and GPT-4, on this dataset. Our results demonstrate that GPT-4 significantly outperforms GPT-3.5-Turbo in terms of both accuracy and response consistency, making it a more reliable tool for coreference resolution in Vietnamese.
An Attempt to Develop a Neural Parser based on Simplified Head-Driven Phrase Structure Grammar on Vietnamese
Nov 26, 2024In this paper, we aimed to develop a neural parser for Vietnamese based on simplified Head-Driven Phrase Structure Grammar (HPSG). The existing corpora, VietTreebank and VnDT, had around 15% of constituency and dependency tree pairs that did not adhere to simplified HPSG rules. To attempt to address the issue of the corpora not adhering to simplified HPSG rules, we randomly permuted samples from the training and development sets to make them compliant with simplified HPSG. We then modified the first simplified HPSG Neural Parser for the Penn Treebank by replacing it with the PhoBERT or XLM-RoBERTa models, which can encode Vietnamese texts. We conducted experiments on our modified VietTreebank and VnDT corpora. Our extensive experiments showed that the simplified HPSG Neural Parser achieved a new state-of-the-art F-score of 82% for constituency parsing when using the same predicted part-of-speech (POS) tags as the self-attentive constituency parser. Additionally, it outperformed previous studies in dependency parsing with a higher Unlabeled Attachment Score (UAS). However, our parser obtained lower Labeled Attachment Score (LAS) scores likely due to our focus on arc permutation without changing the original labels, as we did not consult with a linguistic expert. Lastly, the research findings of this paper suggest that simplified HPSG should be given more attention to linguistic expert when developing treebanks for Vietnamese natural language processing.
Abusive Span Detection for Vietnamese Narrative Texts
Dec 13, 2023
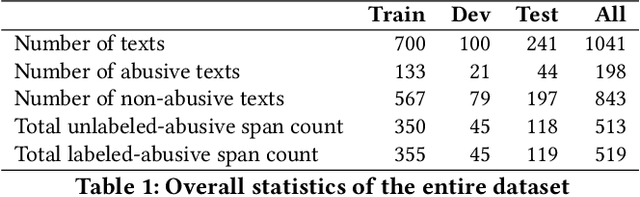
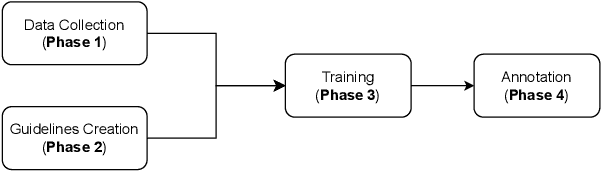

Abuse in its various forms, including physical, psychological, verbal, sexual, financial, and cultural, has a negative impact on mental health. However, there are limited studies on applying natural language processing (NLP) in this field in Vietnam. Therefore, we aim to contribute by building a human-annotated Vietnamese dataset for detecting abusive content in Vietnamese narrative texts. We sourced these texts from VnExpress, Vietnam's popular online newspaper, where readers often share stories containing abusive content. Identifying and categorizing abusive spans in these texts posed significant challenges during dataset creation, but it also motivated our research. We experimented with lightweight baseline models by freezing PhoBERT and XLM-RoBERTa and using their hidden states in a BiLSTM to assess the complexity of the dataset. According to our experimental results, PhoBERT outperforms other models in both labeled and unlabeled abusive span detection tasks. These results indicate that it has the potential for future improvements.
ViSoBERT: A Pre-Trained Language Model for Vietnamese Social Media Text Processing
Oct 28, 2023
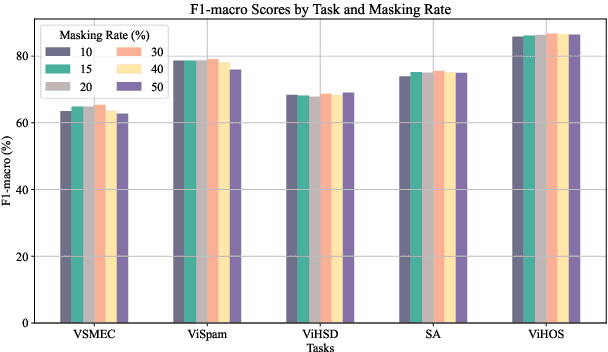

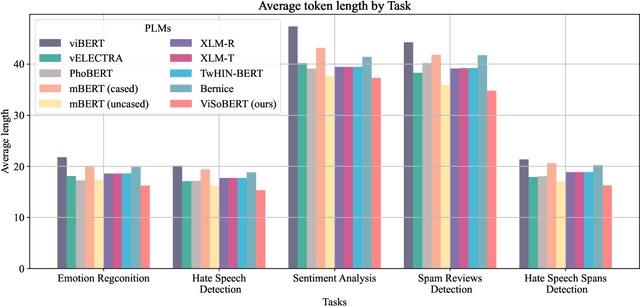
English and Chinese, known as resource-rich languages, have witnessed the strong development of transformer-based language models for natural language processing tasks. Although Vietnam has approximately 100M people speaking Vietnamese, several pre-trained models, e.g., PhoBERT, ViBERT, and vELECTRA, performed well on general Vietnamese NLP tasks, including POS tagging and named entity recognition. These pre-trained language models are still limited to Vietnamese social media tasks. In this paper, we present the first monolingual pre-trained language model for Vietnamese social media texts, ViSoBERT, which is pre-trained on a large-scale corpus of high-quality and diverse Vietnamese social media texts using XLM-R architecture. Moreover, we explored our pre-trained model on five important natural language downstream tasks on Vietnamese social media texts: emotion recognition, hate speech detection, sentiment analysis, spam reviews detection, and hate speech spans detection. Our experiments demonstrate that ViSoBERT, with far fewer parameters, surpasses the previous state-of-the-art models on multiple Vietnamese social media tasks. Our ViSoBERT model is available only for research purposes.
Evaluating the Symbol Binding Ability of Large Language Models for Multiple-Choice Questions in Vietnamese General Education
Oct 23, 2023



In this paper, we evaluate the ability of large language models (LLMs) to perform multiple choice symbol binding (MCSB) for multiple choice question answering (MCQA) tasks in zero-shot, one-shot, and few-shot settings. We focus on Vietnamese, with fewer challenging MCQA datasets than in English. The two existing datasets, ViMMRC 1.0 and ViMMRC 2.0, focus on literature. Recent research in Vietnamese natural language processing (NLP) has focused on the Vietnamese National High School Graduation Examination (VNHSGE) from 2019 to 2023 to evaluate ChatGPT. However, these studies have mainly focused on how ChatGPT solves the VNHSGE step by step. We aim to create a novel and high-quality dataset by providing structured guidelines for typing LaTeX formulas for mathematics, physics, chemistry, and biology. This dataset can be used to evaluate the MCSB ability of LLMs and smaller language models (LMs) because it is typed in a strict LaTeX style. We focus on predicting the character (A, B, C, or D) that is the most likely answer to a question, given the context of the question. Our evaluation of six well-known LLMs, namely BLOOMZ-7.1B-MT, LLaMA-2-7B, LLaMA-2-70B, GPT-3, GPT-3.5, and GPT-4.0, on the ViMMRC 1.0 and ViMMRC 2.0 benchmarks and our proposed dataset shows promising results on the MCSB ability of LLMs for Vietnamese. The dataset is available for research purposes only.
Efficient Finetuning Large Language Models For Vietnamese Chatbot
Sep 09, 2023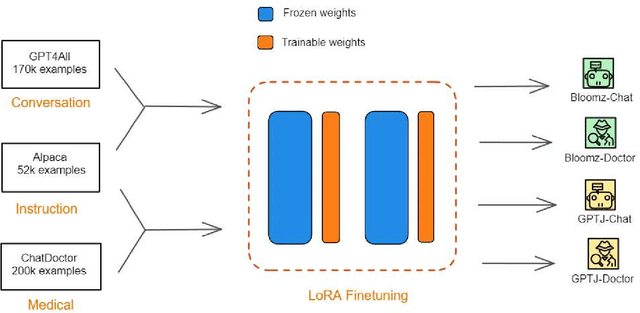

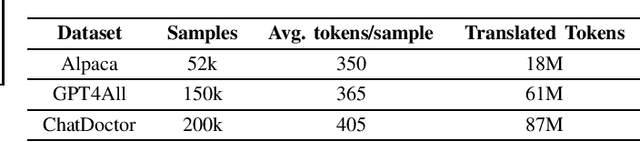
Large language models (LLMs), such as GPT-4, PaLM, and LLaMa, have been shown to achieve remarkable performance across a variety of natural language tasks. Recent advancements in instruction tuning bring LLMs with ability in following user's instructions and producing human-like responses. However, the high costs associated with training and implementing LLMs pose challenges to academic research. Furthermore, the availability of pretrained LLMs and instruction-tune datasets for Vietnamese language is limited. To tackle these concerns, we leverage large-scale instruction-following datasets from open-source projects, namely Alpaca, GPT4All, and Chat-Doctor, which cover general domain and specific medical domain. To the best of our knowledge, these are the first instructional dataset for Vietnamese. Subsequently, we utilize parameter-efficient tuning through Low-Rank Adaptation (LoRA) on two open LLMs: Bloomz (Multilingual) and GPTJ-6B (Vietnamese), resulting four models: Bloomz-Chat, Bloomz-Doctor, GPTJ-Chat, GPTJ-Doctor.Finally, we assess the effectiveness of our methodology on a per-sample basis, taking into consideration the helpfulness, relevance, accuracy, level of detail in their responses. This evaluation process entails the utilization of GPT-4 as an automated scoring mechanism. Despite utilizing a low-cost setup, our method demonstrates about 20-30\% improvement over the original models in our evaluation tasks.
Integrating Semantic Information into Sketchy Reading Module of Retro-Reader for Vietnamese Machine Reading Comprehension
Jan 01, 2023



Machine Reading Comprehension has become one of the most advanced and popular research topics in the fields of Natural Language Processing in recent years. The classification of answerability questions is a relatively significant sub-task in machine reading comprehension; however, there haven't been many studies. Retro-Reader is one of the studies that has solved this problem effectively. However, the encoders of most traditional machine reading comprehension models in general and Retro-Reader, in particular, have not been able to exploit the contextual semantic information of the context completely. Inspired by SemBERT, we use semantic role labels from the SRL task to add semantics to pre-trained language models such as mBERT, XLM-R, PhoBERT. This experiment was conducted to compare the influence of semantics on the classification of answerability for the Vietnamese machine reading comprehension. Additionally, we hope this experiment will enhance the encoder for the Retro-Reader model's Sketchy Reading Module. The improved Retro-Reader model's encoder with semantics was first applied to the Vietnamese Machine Reading Comprehension task and obtained positive results.
Leveraging Semantic Representations Combined with Contextual Word Representations for Recognizing Textual Entailment in Vietnamese
Jan 01, 2023



RTE is a significant problem and is a reasonably active research community. The proposed research works on the approach to this problem are pretty diverse with many different directions. For Vietnamese, the RTE problem is moderately new, but this problem plays a vital role in natural language understanding systems. Currently, methods to solve this problem based on contextual word representation learning models have given outstanding results. However, Vietnamese is a semantically rich language. Therefore, in this paper, we want to present an experiment combining semantic word representation through the SRL task with context representation of BERT relative models for the RTE problem. The experimental results give conclusions about the influence and role of semantic representation on Vietnamese in understanding natural language. The experimental results show that the semantic-aware contextual representation model has about 1% higher performance than the model that does not incorporate semantic representation. In addition, the effects on the data domain in Vietnamese are also higher than those in English. This result also shows the positive influence of SRL on RTE problem in Vietnamese.