 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attempt to Develop a Neural Parser based on Simplified Head-Driven Phrase Structure Grammar on Vietnamese
Nov 26, 2024In this paper, we aimed to develop a neural parser for Vietnamese based on simplified Head-Driven Phrase Structure Grammar (HPSG). The existing corpora, VietTreebank and VnDT, had around 15% of constituency and dependency tree pairs that did not adhere to simplified HPSG rules. To attempt to address the issue of the corpora not adhering to simplified HPSG rules, we randomly permuted samples from the training and development sets to make them compliant with simplified HPSG. We then modified the first simplified HPSG Neural Parser for the Penn Treebank by replacing it with the PhoBERT or XLM-RoBERTa models, which can encode Vietnamese texts. We conducted experiments on our modified VietTreebank and VnDT corpora. Our extensive experiments showed that the simplified HPSG Neural Parser achieved a new state-of-the-art F-score of 82% for constituency parsing when using the same predicted part-of-speech (POS) tags as the self-attentive constituency parser. Additionally, it outperformed previous studies in dependency parsing with a higher Unlabeled Attachment Score (UAS). However, our parser obtained lower Labeled Attachment Score (LAS) scores likely due to our focus on arc permutation without changing the original labels, as we did not consult with a linguistic expert. Lastly, the research findings of this paper suggest that simplified HPSG should be given more attention to linguistic expert when developing treebanks for Vietnamese natural language processing.
ViSoBERT: A Pre-Trained Language Model for Vietnamese Social Media Text Processing
Oct 28, 2023
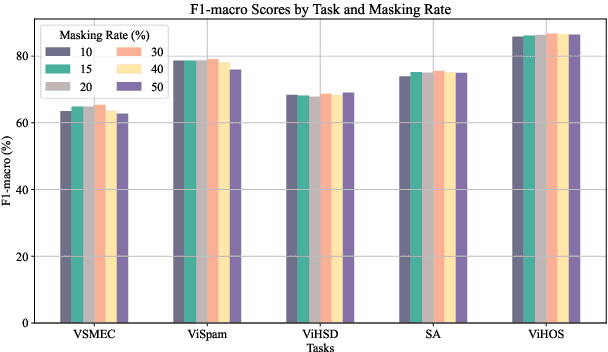

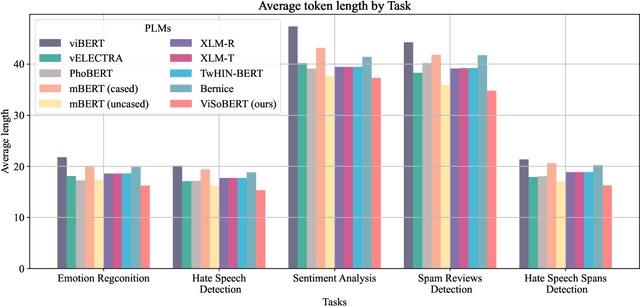
English and Chinese, known as resource-rich languages, have witnessed the strong development of transformer-based language models for natural language processing tasks. Although Vietnam has approximately 100M people speaking Vietnamese, several pre-trained models, e.g., PhoBERT, ViBERT, and vELECTRA, performed well on general Vietnamese NLP tasks, including POS tagging and named entity recognition. These pre-trained language models are still limited to Vietnamese social media tasks. In this paper, we present the first monolingual pre-trained language model for Vietnamese social media texts, ViSoBERT, which is pre-trained on a large-scale corpus of high-quality and diverse Vietnamese social media texts using XLM-R architecture. Moreover, we explored our pre-trained model on five important natural language downstream tasks on Vietnamese social media texts: emotion recognition, hate speech detection, sentiment analysis, spam reviews detection, and hate speech spans detection. Our experiments demonstrate that ViSoBERT, with far fewer parameters, surpasses the previous state-of-the-art models on multiple Vietnamese social media tasks. Our ViSoBERT model is available only for research purposes.