 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViMultiChoice: Toward a Method That Gives Explanation for Multiple-Choice Reading Comprehension in Vietnamese
Feb 10, 2026Multiple-choice Reading Comprehension (MCRC) models aim to select the correct answer from a set of candidate options for a given question. However, they typically lack the ability to explain the reasoning behind their choices. In this paper, we introduce a novel Vietnamese dataset designed to train and evaluate MCRC models with explanation generation capabilities. Furthermore, we propose ViMultiChoice, a new method specifically designed for modeling Vietnamese reading comprehension that jointly predicts the correct answer and generates a corresponding explanation. Experimental results demonstrate that ViMultiChoice outperforms existing MCRC baselines, achieving state-of-the-art (SotA) performance on both the ViMMRC 2.0 benchmark and the newly introduced dataset. Additionally, we show that jointly training option decision and explanation generation leads to significant improvements in multiple-choice accuracy.
ViSpeechFormer: A Phonemic Approach for Vietnamese Automatic Speech Recognition
Feb 10, 2026Vietnamese has a phonetic orthography, where each grapheme corresponds to at most one phoneme and vice versa. Exploiting this high grapheme-phoneme transparency, we propose ViSpeechFormer (\textbf{Vi}etnamese \textbf{Speech} Trans\textbf{Former}), a phoneme-based approach for Vietnamese Automatic Speech Recognition (ASR). To the best of our knowledge, this is the first Vietnamese ASR framework that explicitly models phonemic representations. Experiments on two publicly available Vietnamese ASR datasets show that ViSpeechFormer achieves strong performance, generalizes better to out-of-vocabulary words, and is less affected by training bias. This phoneme-based paradigm is also promising for other languages with phonetic orthographies. The code will be released upon acceptance of this paper.
VLSP 2025 MLQA-TSR Challenge: Vietnamese Multimodal Legal Question Answering on Traffic Sign Regulation
Oct 23, 2025This paper presents the VLSP 2025 MLQA-TSR - the multimodal legal question answering on traffic sign regulation shared task at VLSP 2025. VLSP 2025 MLQA-TSR comprises two subtasks: multimodal legal retrieval and multimodal question answering. The goal is to advance research on Vietnamese multimodal legal text processing and to provide a benchmark dataset for building and evaluating intelligent systems in multimodal legal domains, with a focus on traffic sign regulation in Vietnam. The best-reported results on VLSP 2025 MLQA-TSR are an F2 score of 64.55% for multimodal legal retrieval and an accuracy of 86.30% for multimodal question answering.
Coreference Resolution for Vietnamese Narrative Texts
Apr 28, 2025Coreference resolution is a vital task in natural language processing (NLP) that involves identifying and linking different expressions in a text that refer to the same entity. This task is particularly challenging for Vietnamese, a low-resource language with limited annotated datasets. To address these challenges, we developed a comprehensive annotated dataset using narrative texts from VnExpress, a widely-read Vietnamese online news platform. We established detailed guidelines for annotating entities, focusing on ensuring consistency and accuracy. Additionally, we evaluated the performance of large language models (LLMs), specifically GPT-3.5-Turbo and GPT-4, on this dataset. Our results demonstrate that GPT-4 significantly outperforms GPT-3.5-Turbo in terms of both accuracy and response consistency, making it a more reliable tool for coreference resolution in Vietnamese.
An Attempt to Develop a Neural Parser based on Simplified Head-Driven Phrase Structure Grammar on Vietnamese
Nov 26, 2024In this paper, we aimed to develop a neural parser for Vietnamese based on simplified Head-Driven Phrase Structure Grammar (HPSG). The existing corpora, VietTreebank and VnDT, had around 15% of constituency and dependency tree pairs that did not adhere to simplified HPSG rules. To attempt to address the issue of the corpora not adhering to simplified HPSG rules, we randomly permuted samples from the training and development sets to make them compliant with simplified HPSG. We then modified the first simplified HPSG Neural Parser for the Penn Treebank by replacing it with the PhoBERT or XLM-RoBERTa models, which can encode Vietnamese texts. We conducted experiments on our modified VietTreebank and VnDT corpora. Our extensive experiments showed that the simplified HPSG Neural Parser achieved a new state-of-the-art F-score of 82% for constituency parsing when using the same predicted part-of-speech (POS) tags as the self-attentive constituency parser. Additionally, it outperformed previous studies in dependency parsing with a higher Unlabeled Attachment Score (UAS). However, our parser obtained lower Labeled Attachment Score (LAS) scores likely due to our focus on arc permutation without changing the original labels, as we did not consult with a linguistic expert. Lastly, the research findings of this paper suggest that simplified HPSG should be given more attention to linguistic expert when developing treebanks for Vietnamese natural language processing.
Transformer-Based Contextualized Language Models Joint with Neural Networks for Natural Language Inference in Vietnamese
Nov 21, 2024
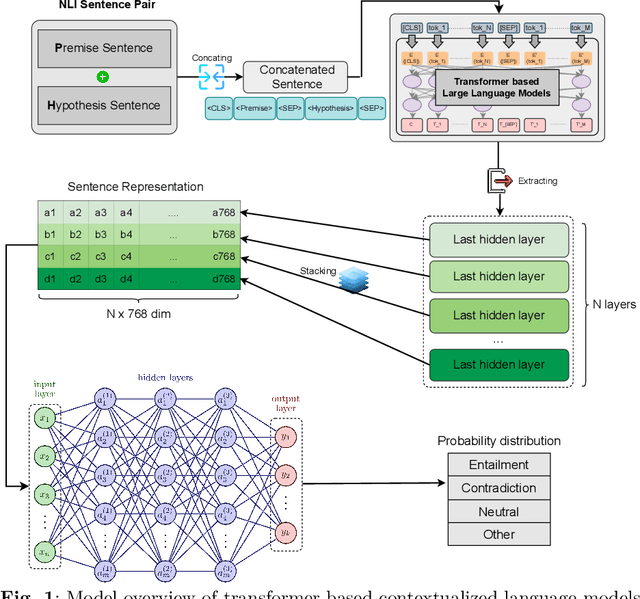
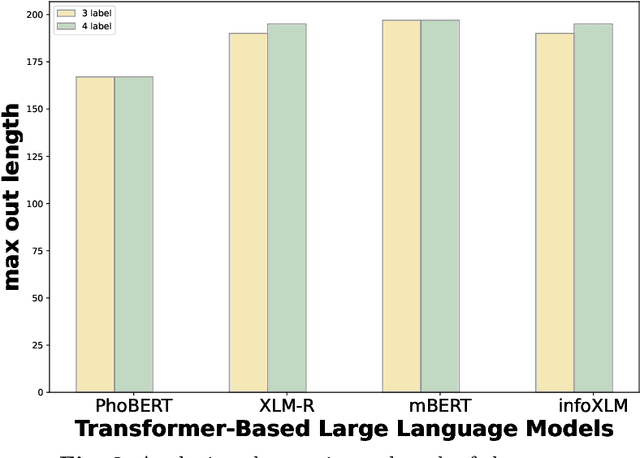
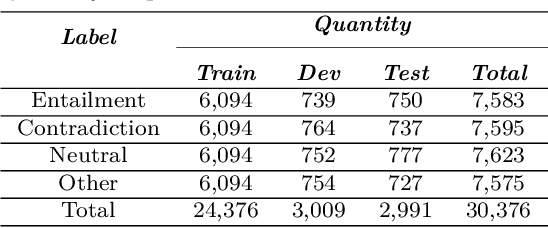
Natural Language Inference (NLI) is a task within Natural Language Processing (NLP) that holds value for various AI applications. However, there have been limited studies on Natural Language Inference in Vietnamese that explore the concept of joint models. Therefore, we conducted experiments using various combinations of contextualized language models (CLM) and neural networks. We use CLM to create contextualized work presentations and use Neural Networks for classification. Furthermore, we have evaluated the strengths and weaknesses of each joint model and identified the model failure points in the Vietnamese context. The highest F1 score in this experiment, up to 82.78% in the benchmark dataset (ViNLI). By conducting experiments with various models, the most considerable size of the CLM is XLM-R (355M). That combination has consistently demonstrated superior performance compared to fine-tuning strong pre-trained language models like PhoBERT (+6.58%), mBERT (+19.08%), and XLM-R (+0.94%) in terms of F1-score. This article aims to introduce a novel approach or model that attains improved performance for Vietnamese NLI. Overall, we find that the joint approach of CLM and neural networks is simple yet capable of achieving high-quality performance, which makes it suitable for applications that require efficient resource utilization.
ViConsFormer: Constituting Meaningful Phrases of Scene Texts using Transformer-based Method in Vietnamese Text-based Visual Question Answering
Oct 24, 2024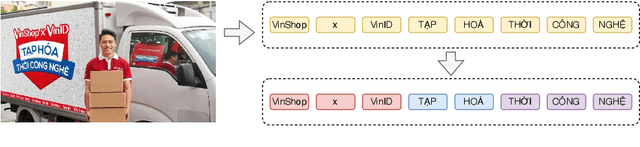
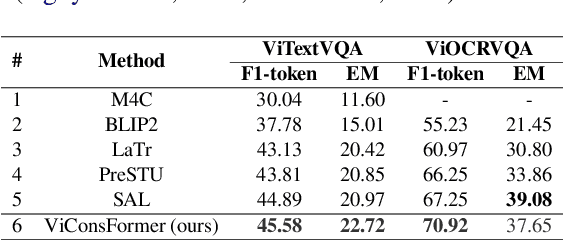
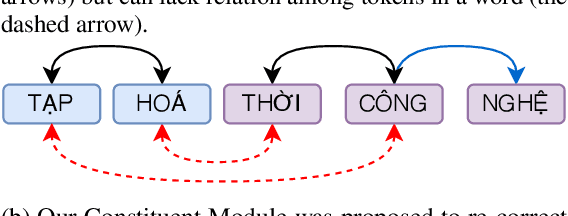
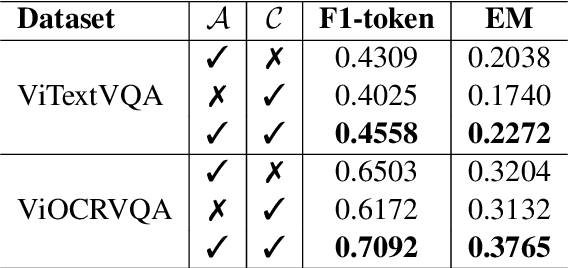
Text-based VQA is a challenging task that requires machines to use scene texts in given images to yield the most appropriate answer for the given question. The main challenge of text-based VQA is exploiting the meaning and information from scene texts. Recent studies tackled this challenge by considering the spatial information of scene texts in images via embedding 2D coordinates of their bounding boxes. In this study, we follow the definition of meaning from linguistics to introduce a novel method that effectively exploits the information from scene texts written in Vietnamese. Experimental results show that our proposed method obtains state-of-the-art results on two large-scale Vietnamese Text-based VQA datasets. The implementation can be found at this link.
ViANLI: Adversarial Natural Language Inference for Vietnamese
Jun 25, 2024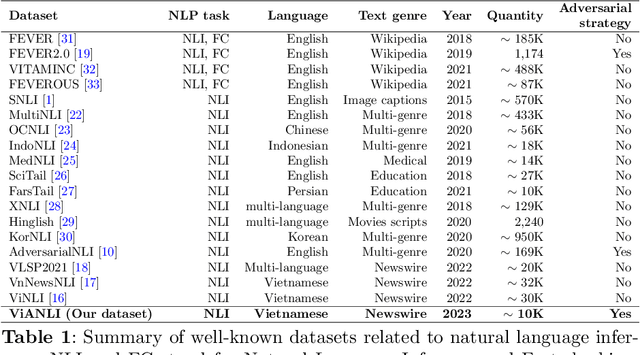
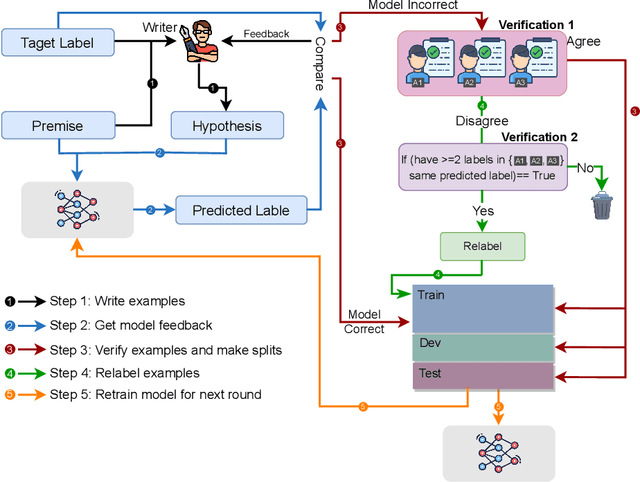
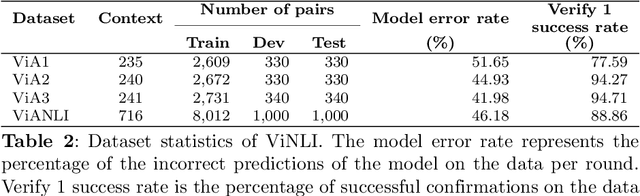
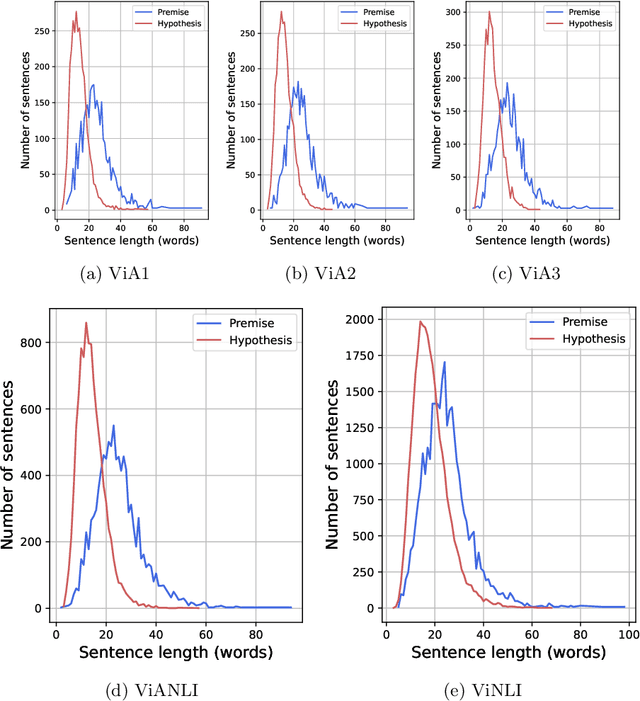
The development of Natural Language Processing (NLI) datasets and models has been inspired by innovations in annotation design. With the rapid development of machine learning models today, the performance of existing machine learning models has quickly reached state-of-the-art results on a variety of tasks related to natural language processing, including natural language inference tasks. By using a pre-trained model during the annotation process, it is possible to challenge current NLI models by having humans produce premise-hypothesis combinations that the machine model cannot correctly predict. To remain attractive and challenging in the research of natural language inference for Vietnamese, in this paper, we introduce the adversarial NLI dataset to the NLP research community with the name ViANLI. This data set contains more than 10K premise-hypothesis pairs and is built by a continuously adjusting process to obtain the most out of the patterns generated by the annotators. ViANLI dataset has brought many difficulties to many current SOTA models when the accuracy of the most powerful model on the test set only reached 48.4%. Additionally, the experimental results show that the models trained on our dataset have significantly improved the results on other Vietnamese NLI datasets.
ViOCRVQA: Novel Benchmark Dataset and Vision Reader for Visual Question Answering by Understanding Vietnamese Text in Images
Apr 29, 2024



Optical Character Recognition - Visual Question Answering (OCR-VQA) is the task of answering text information contained in images that have just been significantly developed in the English language in recent years. However, there are limited studies of this task in low-resource languages such as Vietnamese. To this end, we introduce a novel dataset, ViOCRVQA (Vietnamese Optical Character Recognition - Visual Question Answering dataset), consisting of 28,000+ images and 120,000+ question-answer pairs. In this dataset, all the images contain text and questions about the information relevant to the text in the images. We deploy ideas from state-of-the-art methods proposed for English to conduct experiments on our dataset, revealing the challenges and difficulties inherent in a Vietnamese dataset. Furthermore, we introduce a novel approach, called VisionReader, which achieved 0.4116 in EM and 0.6990 in the F1-score on the test set. Through the results, we found that the OCR system plays a very important role in VQA models on the ViOCRVQA dataset. In addition, the objects in the image also play a role in improving model performance. We open access to our dataset at link (https://github.com/qhnhynmm/ViOCRVQA.git) for further research in OCR-VQA task in Vietnamese.
ViTextVQA: A Large-Scale Visual Question Answering Dataset for Evaluating Vietnamese Text Comprehension in Images
Apr 16, 2024



Visual Question Answering (VQA) is a complicated task that requires the capability of simultaneously processing natural language and images. Initially, this task was researched, focusing on methods to help machines understand objects and scene contexts in images. However, some text appearing in the image that carries explicit information about the full content of the image is not mentioned. Along with the continuous development of the AI era, there have been many studies on the reading comprehension ability of VQA models in the world. As a developing country, conditions are still limited, and this task is still open in Vietnam. Therefore, we introduce the first large-scale dataset in Vietnamese specializing in the ability to understand text appearing in images, we call it ViTextVQA (\textbf{Vi}etnamese \textbf{Text}-based \textbf{V}isual \textbf{Q}uestion \textbf{A}nswering dataset) which contains \textbf{over 16,000} images and \textbf{over 50,000} questions with answers. Through meticulous experiments with various state-of-the-art models, we uncover the significance of the order in which tokens in OCR text are processed and selected to formulate answers. This finding helped us significantly improve the performance of the baseline models on the ViTextVQA dataset. Our dataset is available at this \href{https://github.com/minhquan6203/ViTextVQA-Dataset}{link} for research purposes.