 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Contextualized Language Models Joint with Neural Networks for Natural Language Inference in Vietnamese
Nov 21, 2024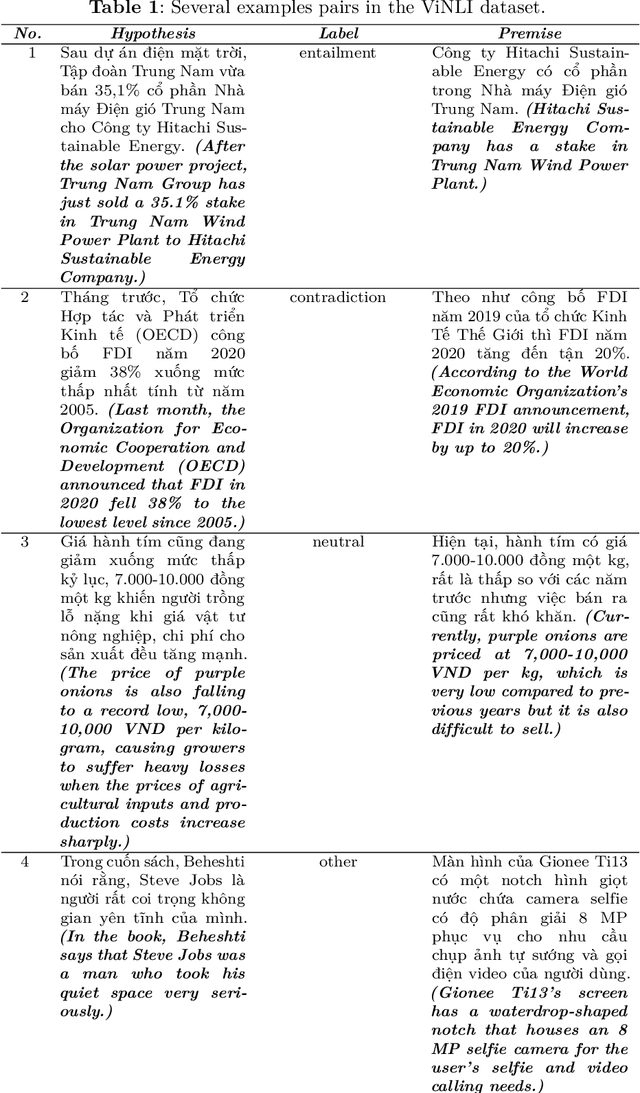
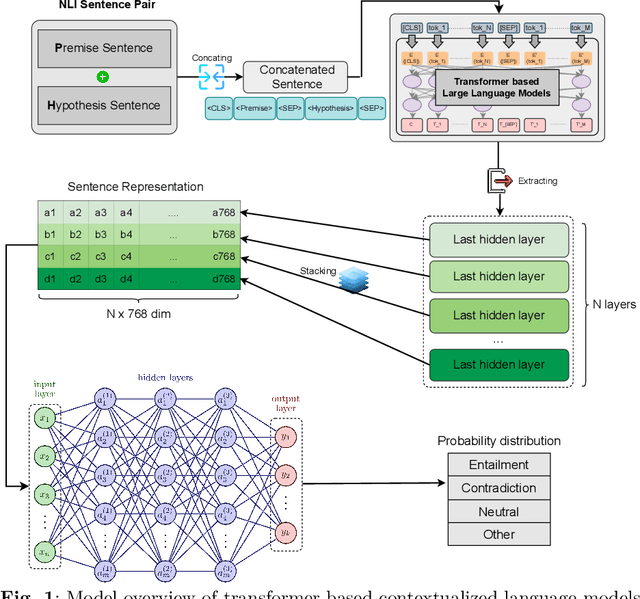
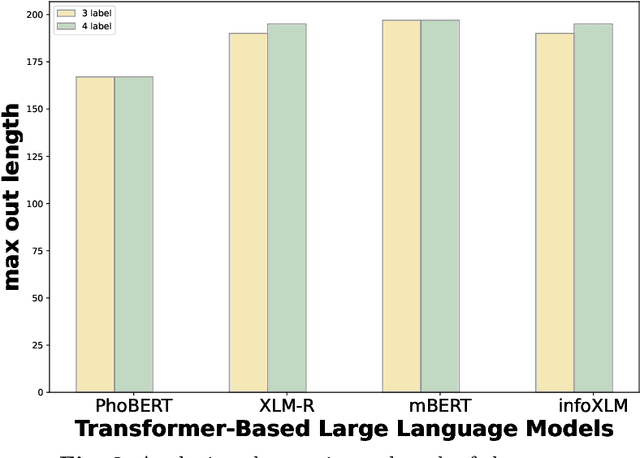
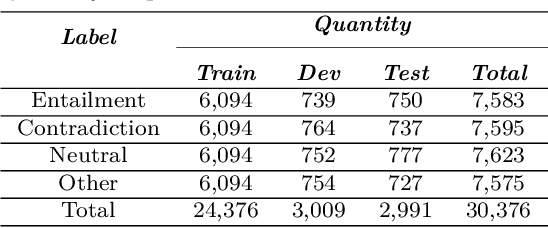
Natural Language Inference (NLI) is a task within Natural Language Processing (NLP) that holds value for various AI applications. However, there have been limited studies on Natural Language Inference in Vietnamese that explore the concept of joint models. Therefore, we conducted experiments using various combinations of contextualized language models (CLM) and neural networks. We use CLM to create contextualized work presentations and use Neural Networks for classification. Furthermore, we have evaluated the strengths and weaknesses of each joint model and identified the model failure points in the Vietnamese context. The highest F1 score in this experiment, up to 82.78% in the benchmark dataset (ViNLI). By conducting experiments with various models, the most considerable size of the CLM is XLM-R (355M). That combination has consistently demonstrated superior performance compared to fine-tuning strong pre-trained language models like PhoBERT (+6.58%), mBERT (+19.08%), and XLM-R (+0.94%) in terms of F1-score. This article aims to introduce a novel approach or model that attains improved performance for Vietnamese NLI. Overall, we find that the joint approach of CLM and neural networks is simple yet capable of achieving high-quality performance, which makes it suitable for applications that require efficient resource utilization.
Evaluating Large Language Model Capability in Vietnamese Fact-Checking Data Generation
Nov 08, 2024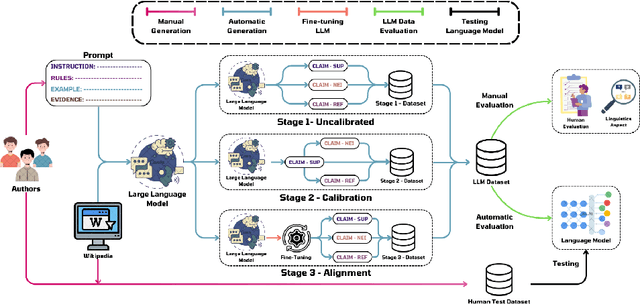


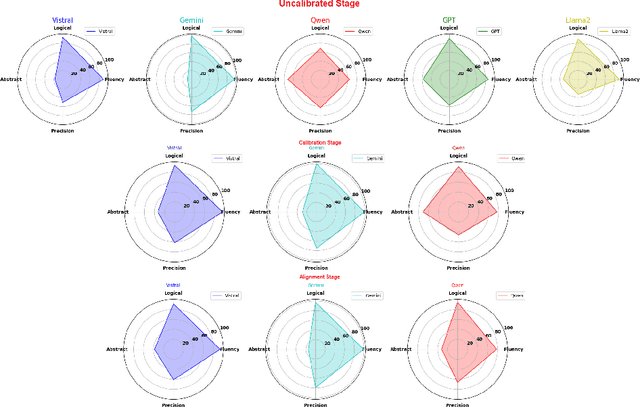
Large Language Models (LLMs), with gradually improving reading comprehension and reasoning capabilities, are being applied to a range of complex language tasks, including the automatic generation of language data for various purposes. However, research on applying LLMs for automatic data generation in low-resource languages like Vietnamese is still underdeveloped and lacks comprehensive evaluation. In this paper, we explore the use of LLMs for automatic data generation for the Vietnamese fact-checking task, which faces significant data limitations. Specifically, we focus on fact-checking data where claims are synthesized from multiple evidence sentences to assess the information synthesis capabilities of LLMs. We develop an automatic data construction process using simple prompt techniques on LLMs and explore several methods to improve the quality of the generated data. To evaluate the quality of the data generated by LLMs, we conduct both manual quality assessments and performance evaluations using language models. Experimental results and manual evaluations illustrate that while the quality of the generated data has significantly improved through fine-tuning techniques, LLMs still cannot match the data quality produced by humans.