 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Model Capability in Vietnamese Fact-Checking Data Generation
Nov 08, 2024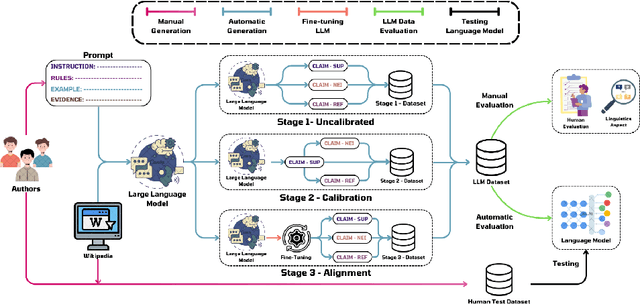


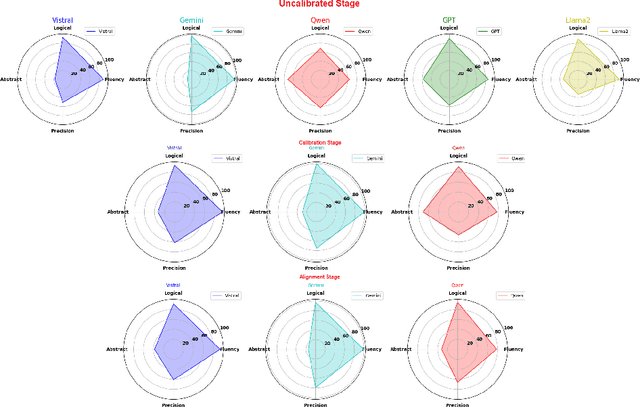
Large Language Models (LLMs), with gradually improving reading comprehension and reasoning capabilities, are being applied to a range of complex language tasks, including the automatic generation of language data for various purposes. However, research on applying LLMs for automatic data generation in low-resource languages like Vietnamese is still underdeveloped and lacks comprehensive evaluation. In this paper, we explore the use of LLMs for automatic data generation for the Vietnamese fact-checking task, which faces significant data limitations. Specifically, we focus on fact-checking data where claims are synthesized from multiple evidence sentences to assess the information synthesis capabilities of LLMs. We develop an automatic data construction process using simple prompt techniques on LLMs and explore several methods to improve the quality of the generated data. To evaluate the quality of the data generated by LLMs, we conduct both manual quality assessments and performance evaluations using language models. Experimental results and manual evaluations illustrate that while the quality of the generated data has significantly improved through fine-tuning techniques, LLMs still cannot match the data quality produced by humans.
A study of Vietnamese readability assessing through semantic and statistical features
Nov 07, 2024


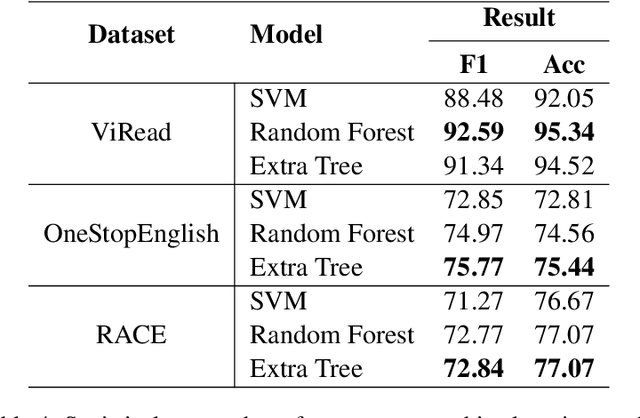
Determining the difficulty of a text involves assessing various textual features that may impact the reader's text comprehension, yet current research in Vietnamese has only focused on statistical features. This paper introduces a new approach that integrates statistical and semantic approaches to assessing text readability. Our research utilized three distinct datasets: the Vietnamese Text Readability Dataset (ViRead), OneStopEnglish, and RACE, with the latter two translated into Vietnamese. Advanced semantic analysis methods were employed for the semantic aspect using state-of-the-art language models such as PhoBERT, ViDeBERTa, and ViBERT. In addition, statistical methods were incorporated to extract syntactic and lexical features of the text. We conducted experiments using various machine learning models, including Support Vector Machine (SVM), Random Forest, and Extra Trees and evaluated their performance using accuracy and F1 score metrics. Our results indicate that a joint approach that combines semantic and statistical features significantly enhances the accuracy of readability classification compared to using each method in isolation. The current study emphasizes the importance of considering both statistical and semantic aspects for a more accurate assessment of text difficulty in Vietnamese. This contribution to the field provides insights into the adaptability of advanced language models in the context of Vietnamese text readability. It lays the groundwork for future research in this area.
ViWikiFC: Fact-Checking for Vietnamese Wikipedia-Based Textual Knowledge Source
May 13, 2024



Fact-checking is essential due to the explosion of misinformation in the media ecosystem. Although false information exists in every language and country, most research to solve the problem mainly concentrated on huge communities like English and Chinese. Low-resource languages like Vietnamese are necessary to explore corpora and models for fact verification. To bridge this gap, we construct ViWikiFC, the first manual annotated open-domain corpus for Vietnamese Wikipedia Fact Checking more than 20K claims generated by converting evidence sentences extracted from Wikipedia articles. We analyze our corpus through many linguistic aspects, from the new dependency rate, the new n-gram rate, and the new word rate. We conducted various experiments for Vietnamese fact-checking, including evidence retrieval and verdict prediction. BM25 and InfoXLM (Large) achieved the best results in two tasks, with BM25 achieving an accuracy of 88.30% for SUPPORTS, 86.93% for REFUTES, and only 56.67% for the NEI label in the evidence retrieval task, InfoXLM (Large) achieved an F1 score of 86.51%. Furthermore, we also conducted a pipeline approach, which only achieved a strict accuracy of 67.00% when using InfoXLM (Large) and BM25. These results demonstrate that our dataset is challenging for the Vietnamese language model in fact-checking tasks.