 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA study of Vietnamese readability assessing through semantic and statistical features
Nov 07, 2024


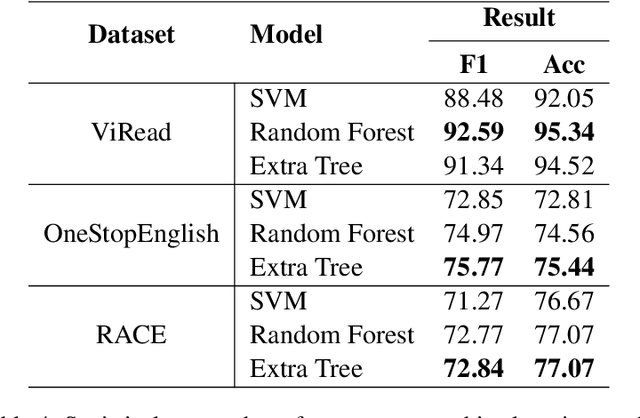
Determining the difficulty of a text involves assessing various textual features that may impact the reader's text comprehension, yet current research in Vietnamese has only focused on statistical features. This paper introduces a new approach that integrates statistical and semantic approaches to assessing text readability. Our research utilized three distinct datasets: the Vietnamese Text Readability Dataset (ViRead), OneStopEnglish, and RACE, with the latter two translated into Vietnamese. Advanced semantic analysis methods were employed for the semantic aspect using state-of-the-art language models such as PhoBERT, ViDeBERTa, and ViBERT. In addition, statistical methods were incorporated to extract syntactic and lexical features of the text. We conducted experiments using various machine learning models, including Support Vector Machine (SVM), Random Forest, and Extra Trees and evaluated their performance using accuracy and F1 score metrics. Our results indicate that a joint approach that combines semantic and statistical features significantly enhances the accuracy of readability classification compared to using each method in isolation. The current study emphasizes the importance of considering both statistical and semantic aspects for a more accurate assessment of text difficulty in Vietnamese. This contribution to the field provides insights into the adaptability of advanced language models in the context of Vietnamese text readability. It lays the groundwork for future research in this area.