 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViCLSR: A Supervised Contrastive Learning Framework with Natural Language Inference for Natural Language Understanding Tasks
Mar 22, 2026High-quality text representations are crucial for natural language understanding (NLU), but low-resource languages like Vietnamese face challenges due to limited annotated data. While pre-trained models like PhoBERT and CafeBERT perform well, their effectiveness is constrained by data scarcity. Contrastive learning (CL) has recently emerged as a promising approach for improving sentence representations, enabling models to effectively distinguish between semantically similar and dissimilar sentences. We propose ViCLSR (Vietnamese Contrastive Learning for Sentence Representations), a novel supervised contrastive learning framework specifically designed to optimize sentence embeddings for Vietnamese, leveraging existing natural language inference (NLI) datasets. Additionally, we propose a process to adapt existing Vietnamese datasets for supervised learning, ensuring compatibility with CL methods. Our experiments demonstrate that ViCLSR significantly outperforms the powerful monolingual pre-trained model PhoBERT on five benchmark NLU datasets such as ViNLI (+6.97% F1), ViWikiFC (+4.97% F1), ViFactCheck (+9.02% F1), UIT-ViCTSD (+5.36% F1), and ViMMRC2.0 (+4.33% Accuracy). ViCLSR shows that supervised contrastive learning can effectively address resource limitations in Vietnamese NLU tasks and improve sentence representation learning for low-resource languages. Furthermore, we conduct an in-depth analysis of the experimental results to uncover the factors contributing to the superior performance of contrastive learning models. ViCLSR is released for research purposes in advancing natural language processing tasks.
DSC2025 -- ViHallu Challenge: Detecting Hallucination in Vietnamese LLMs
Jan 08, 2026The reliability of large language models (LLMs) in production environments remains significantly constrained by their propensity to generate hallucinations--fluent, plausible-sounding outputs that contradict or fabricate information. While hallucination detection has recently emerged as a priority in English-centric benchmarks, low-to-medium resource languages such as Vietnamese remain inadequately covered by standardized evaluation frameworks. This paper introduces the DSC2025 ViHallu Challenge, the first large-scale shared task for detecting hallucinations in Vietnamese LLMs. We present the ViHallu dataset, comprising 10,000 annotated triplets of (context, prompt, response) samples systematically partitioned into three hallucination categories: no hallucination, intrinsic, and extrinsic hallucinations. The dataset incorporates three prompt types--factual, noisy, and adversarial--to stress-test model robustness. A total of 111 teams participated, with the best-performing system achieving a macro-F1 score of 84.80\%, compared to a baseline encoder-only score of 32.83\%, demonstrating that instruction-tuned LLMs with structured prompting and ensemble strategies substantially outperform generic architectures. However, the gap to perfect performance indicates that hallucination detection remains a challenging problem, particularly for intrinsic (contradiction-based) hallucinations. This work establishes a rigorous benchmark and explores a diverse range of detection methodologies, providing a foundation for future research into the trustworthiness and reliability of Vietnamese language AI systems.
Transformer-Based Contextualized Language Models Joint with Neural Networks for Natural Language Inference in Vietnamese
Nov 21, 2024
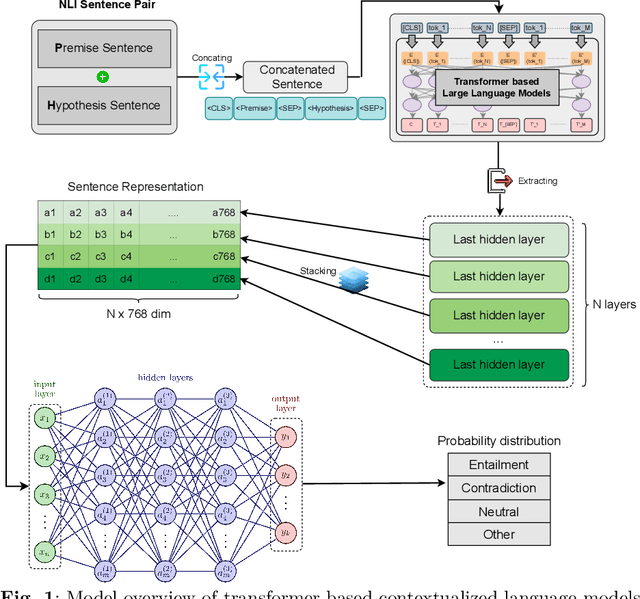
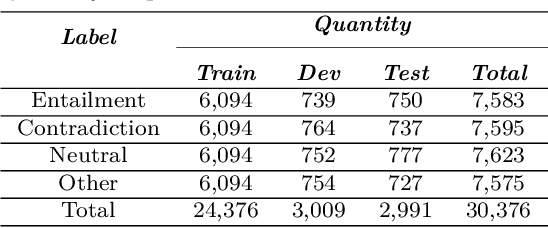
Natural Language Inference (NLI) is a task within Natural Language Processing (NLP) that holds value for various AI applications. However, there have been limited studies on Natural Language Inference in Vietnamese that explore the concept of joint models. Therefore, we conducted experiments using various combinations of contextualized language models (CLM) and neural networks. We use CLM to create contextualized work presentations and use Neural Networks for classification. Furthermore, we have evaluated the strengths and weaknesses of each joint model and identified the model failure points in the Vietnamese context. The highest F1 score in this experiment, up to 82.78% in the benchmark dataset (ViNLI). By conducting experiments with various models, the most considerable size of the CLM is XLM-R (355M). That combination has consistently demonstrated superior performance compared to fine-tuning strong pre-trained language models like PhoBERT (+6.58%), mBERT (+19.08%), and XLM-R (+0.94%) in terms of F1-score. This article aims to introduce a novel approach or model that attains improved performance for Vietnamese NLI. Overall, we find that the joint approach of CLM and neural networks is simple yet capable of achieving high-quality performance, which makes it suitable for applications that require efficient resource utilization.
Evaluating Large Language Model Capability in Vietnamese Fact-Checking Data Generation
Nov 08, 2024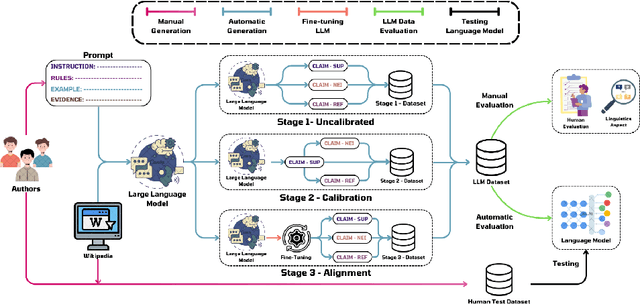


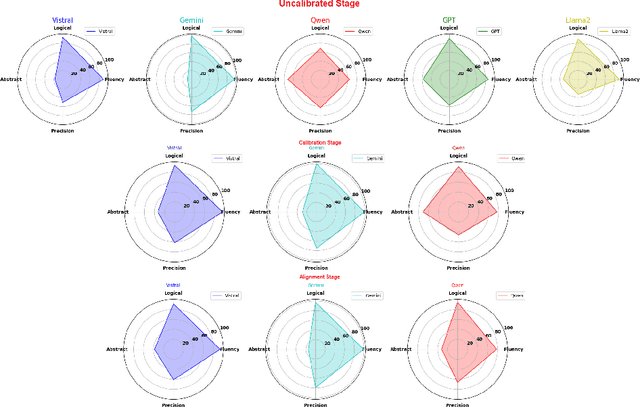
Large Language Models (LLMs), with gradually improving reading comprehension and reasoning capabilities, are being applied to a range of complex language tasks, including the automatic generation of language data for various purposes. However, research on applying LLMs for automatic data generation in low-resource languages like Vietnamese is still underdeveloped and lacks comprehensive evaluation. In this paper, we explore the use of LLMs for automatic data generation for the Vietnamese fact-checking task, which faces significant data limitations. Specifically, we focus on fact-checking data where claims are synthesized from multiple evidence sentences to assess the information synthesis capabilities of LLMs. We develop an automatic data construction process using simple prompt techniques on LLMs and explore several methods to improve the quality of the generated data. To evaluate the quality of the data generated by LLMs, we conduct both manual quality assessments and performance evaluations using language models. Experimental results and manual evaluations illustrate that while the quality of the generated data has significantly improved through fine-tuning techniques, LLMs still cannot match the data quality produced by humans.
ViANLI: Adversarial Natural Language Inference for Vietnamese
Jun 25, 2024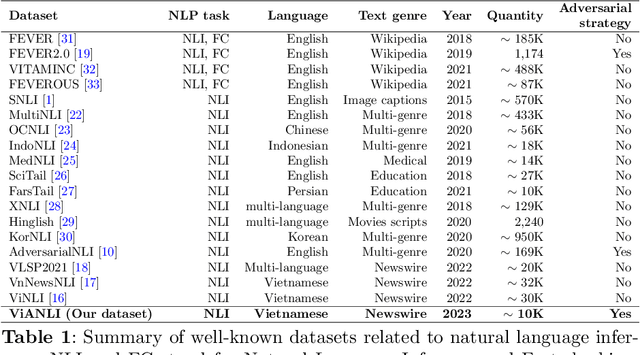
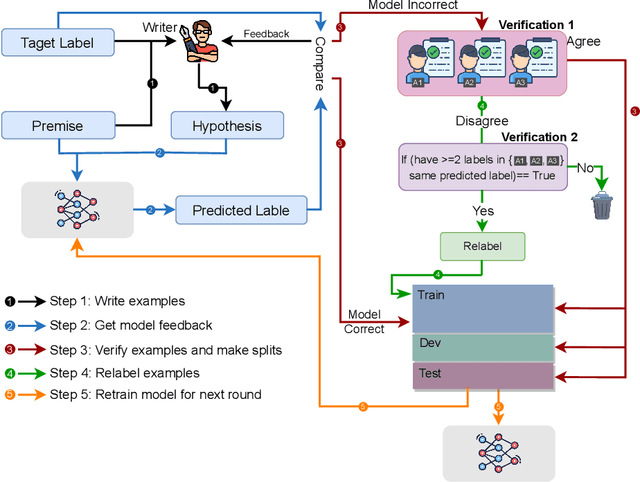
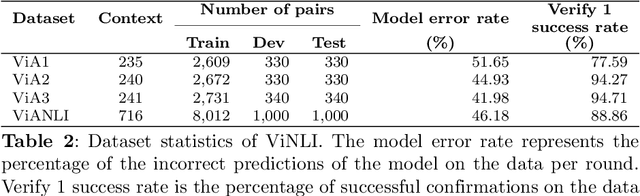
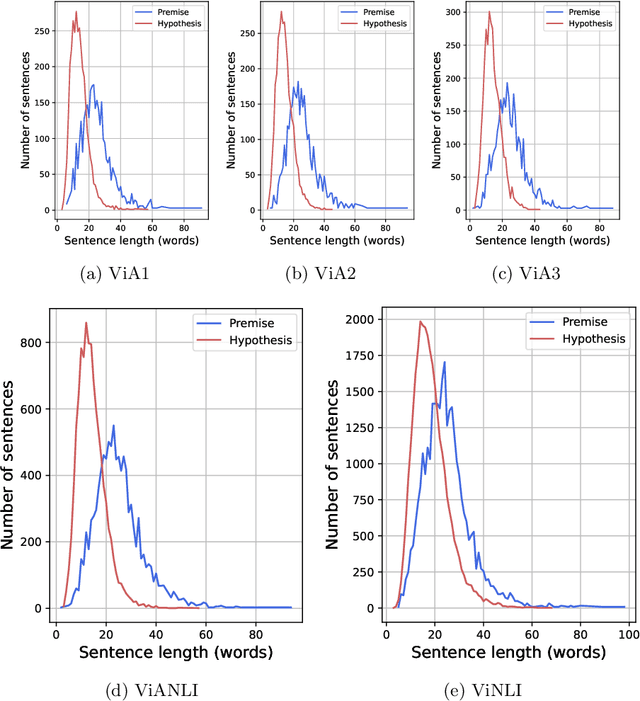
The development of Natural Language Processing (NLI) datasets and models has been inspired by innovations in annotation design. With the rapid development of machine learning models today, the performance of existing machine learning models has quickly reached state-of-the-art results on a variety of tasks related to natural language processing, including natural language inference tasks. By using a pre-trained model during the annotation process, it is possible to challenge current NLI models by having humans produce premise-hypothesis combinations that the machine model cannot correctly predict. To remain attractive and challenging in the research of natural language inference for Vietnamese, in this paper, we introduce the adversarial NLI dataset to the NLP research community with the name ViANLI. This data set contains more than 10K premise-hypothesis pairs and is built by a continuously adjusting process to obtain the most out of the patterns generated by the annotators. ViANLI dataset has brought many difficulties to many current SOTA models when the accuracy of the most powerful model on the test set only reached 48.4%. Additionally, the experimental results show that the models trained on our dataset have significantly improved the results on other Vietnamese NLI datasets.
XLMRQA: Open-Domain Question Answering on Vietnamese Wikipedia-based Textual Knowledge Source
Apr 14, 2022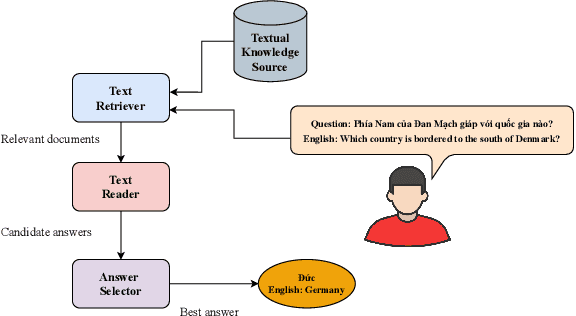
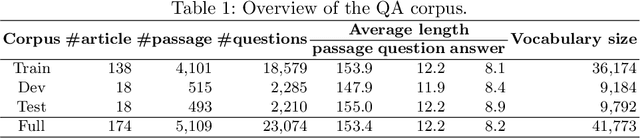
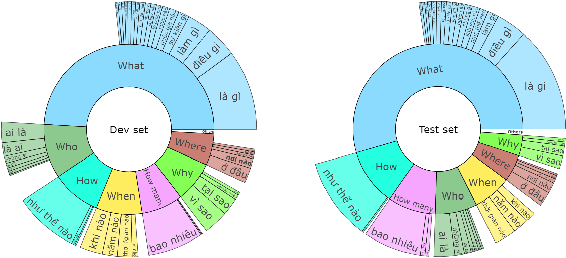
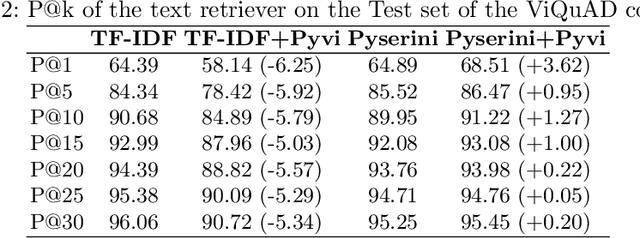
Question answering (QA) is a natural language understanding task within the fields of information retrieval and information extraction that has attracted much attention from the computational linguistics and artificial intelligence research community in recent years because of the strong development of machine reading comprehension-based models. A reader-based QA system is a high-level search engine that can find correct answers to queries or questions in open-domain or domain-specific texts using machine reading comprehension (MRC) techniques. The majority of advancements in data resources and machine-learning approaches in the MRC and QA systems, on the other hand, especially in two resource-rich languages such as English and Chinese. A low-resource language like Vietnamese has witnessed a scarcity of research on QA systems. This paper presents XLMRQA, the first Vietnamese QA system using a supervised transformer-based reader on the Wikipedia-based textual knowledge source (using the UIT-ViQuAD corpus), outperforming the two robust QA systems using deep neural network models: DrQA and BERTserini with 24.46% and 6.28%, respectively. From the results obtained on the three systems, we analyze the influence of question types on the performance of the QA systems.
VLSP 2021 - ViMRC Challenge: Vietnamese Machine Reading Comprehension
Apr 04, 2022
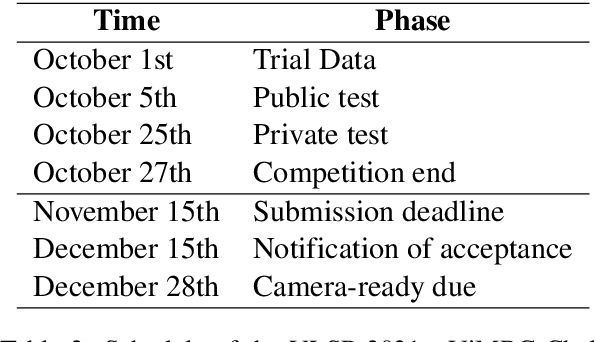
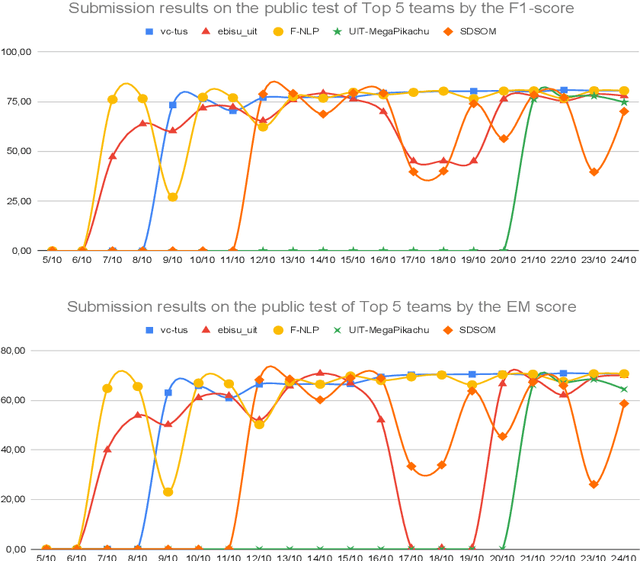

One of the emerging research trends in natural language understanding is machine reading comprehension (MRC) which is the task to find answers to human questions based on textual data. Existing Vietnamese datasets for MRC research concentrate solely on answerable questions. However, in reality, questions can be unanswerable for which the correct answer is not stated in the given textual data. To address the weakness, we provide the research community with a benchmark dataset named UIT-ViQuAD 2.0 for evaluating the MRC task and question answering systems for the Vietnamese language. We use UIT-ViQuAD 2.0 as a benchmark dataset for the challenge on Vietnamese MRC at the Eighth Workshop on Vietnamese Language and Speech Processing (VLSP 2021). This task attracted 77 participant teams from 34 universities and other organizations. In this article, we present details of the organization of the challenge, an overview of the methods employed by shared-task participants, and the results. The highest performances are 77.24% in F1-score and 67.43% in Exact Match on the private test set. The Vietnamese MRC systems proposed by the top 3 teams use XLM-RoBERTa, a powerful pre-trained language model based on the transformer architecture. The UIT-ViQuAD 2.0 dataset motivates researchers to further explore the Vietnamese machine reading comprehension task and related tasks such as question answering, question generation, and natural language inference.
Sentence Extraction-Based Machine Reading Comprehension for Vietnamese
Jun 11, 2021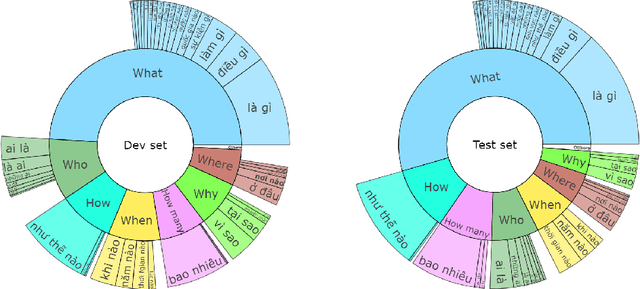
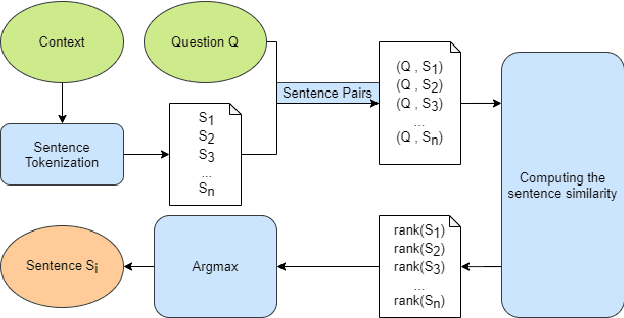
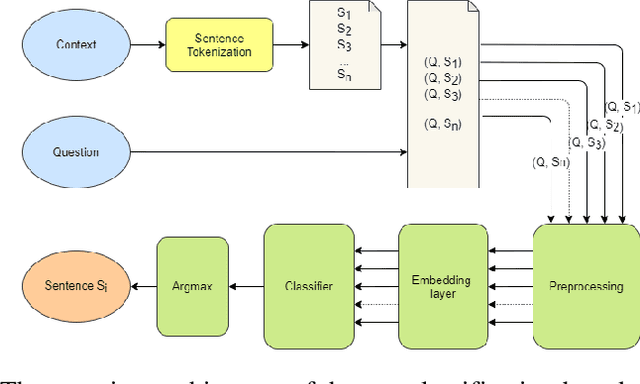
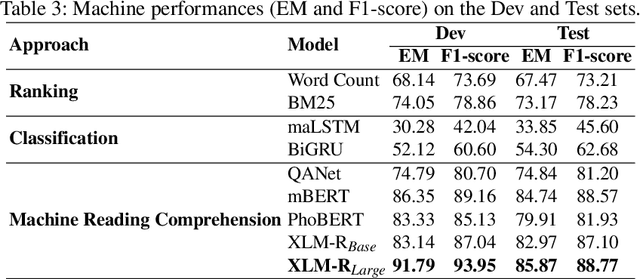
The development of natural language processing (NLP) in general and machine reading comprehension in particular has attracted the great attention of the research community. In recent years, there are a few datasets for machine reading comprehension tasks in Vietnamese with large sizes, such as UIT-ViQuAD and UIT-ViNewsQA. However, the datasets are not diverse in answers to serve the research. In this paper, we introduce UIT-ViWikiQA, the first dataset for evaluating sentence extraction-based machine reading comprehension in the Vietnamese language. The UIT-ViWikiQA dataset is converted from the UIT-ViQuAD dataset, consisting of comprises 23.074 question-answers based on 5.109 passages of 174 Wikipedia Vietnamese articles. We propose a conversion algorithm to create the dataset for sentence extraction-based machine reading comprehension and three types of approaches for sentence extraction-based machine reading comprehension in Vietnamese. Our experiments show that the best machine model is XLM-R_Large, which achieves an exact match (EM) of 85.97% and an F1-score of 88.77% on our dataset. Besides, we analyze experimental results in terms of the question type in Vietnamese and the effect of context on the performance of the MRC models, thereby showing the challenges from the UIT-ViWikiQA dataset that we propose to the language processing community.
SA2SL: From Aspect-Based Sentiment Analysis to Social Listening System for Business Intelligence
Jun 10, 2021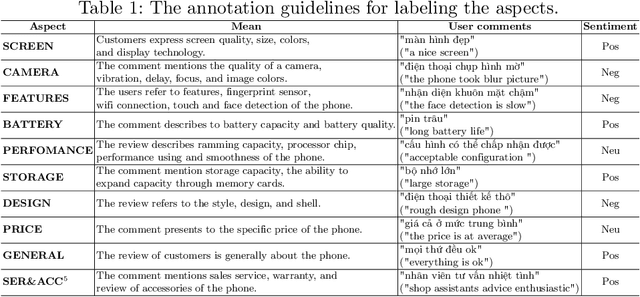
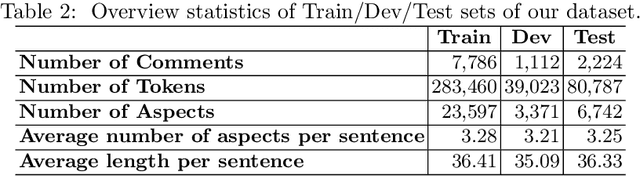
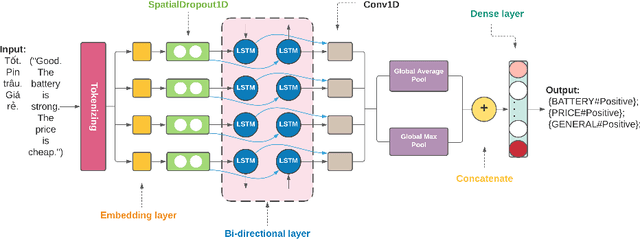
In this paper, we present a process of building a social listening system based on aspect-based sentiment analysis in Vietnamese from creating a dataset to building a real application. Firstly, we create UIT-ViSFD, a Vietnamese Smartphone Feedback Dataset as a new benchmark corpus built based on a strict annotation schemes for evaluating aspect-based sentiment analysis, consisting of 11,122 human-annotated comments for mobile e-commerce, which is freely available for research purposes. We also present a proposed approach based on the Bi-LSTM architecture with the fastText word embeddings for the Vietnamese aspect based sentiment task. Our experiments show that our approach achieves the best performances with the F1-score of 84.48% for the aspect task and 63.06% for the sentiment task, which performs several conventional machine learning and deep learning systems. Last but not least, we build SA2SL, a social listening system based on the best performance model on our dataset, which will inspire more social listening systems in future.
BANANA at WNUT-2020 Task 2: Identifying COVID-19 Information on Twitter by Combining Deep Learning and Transfer Learning Models
Sep 06, 2020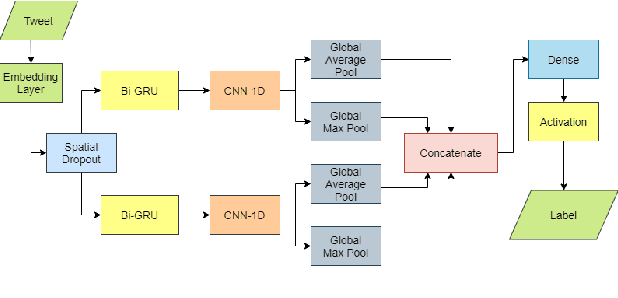

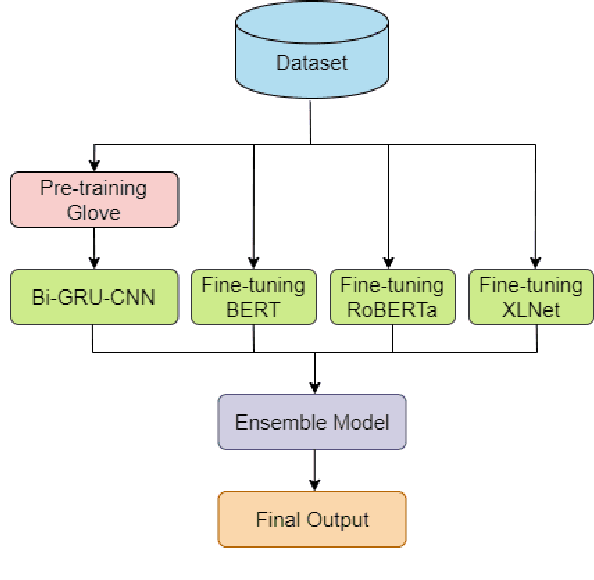

The outbreak COVID-19 virus caused a significant impact on the health of people all over the world. Therefore, it is essential to have a piece of constant and accurate information about the disease with everyone. This paper describes our prediction system for WNUT-2020 Task 2: Identification of Informative COVID-19 English Tweets. The dataset for this task contains size 10,000 tweets in English labeled by humans. The ensemble model from our three transformer and deep learning models is used for the final prediction. The experimental result indicates that we have achieved F1 for the INFORMATIVE label on our systems at 88.81% on the test set.