 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXLMRQA: Open-Domain Question Answering on Vietnamese Wikipedia-based Textual Knowledge Source
Apr 14, 2022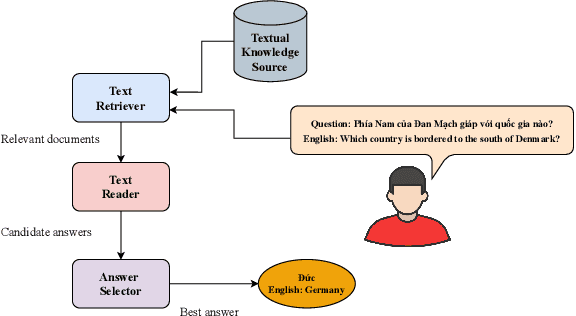
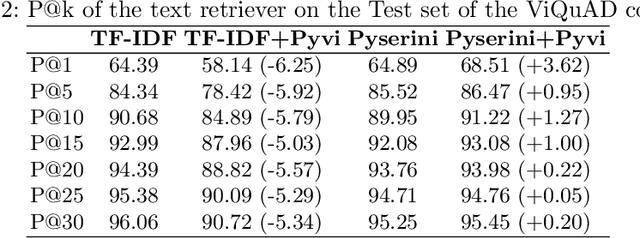
Question answering (QA) is a natural language understanding task within the fields of information retrieval and information extraction that has attracted much attention from the computational linguistics and artificial intelligence research community in recent years because of the strong development of machine reading comprehension-based models. A reader-based QA system is a high-level search engine that can find correct answers to queries or questions in open-domain or domain-specific texts using machine reading comprehension (MRC) techniques. The majority of advancements in data resources and machine-learning approaches in the MRC and QA systems, on the other hand, especially in two resource-rich languages such as English and Chinese. A low-resource language like Vietnamese has witnessed a scarcity of research on QA systems. This paper presents XLMRQA, the first Vietnamese QA system using a supervised transformer-based reader on the Wikipedia-based textual knowledge source (using the UIT-ViQuAD corpus), outperforming the two robust QA systems using deep neural network models: DrQA and BERTserini with 24.46% and 6.28%, respectively. From the results obtained on the three systems, we analyze the influence of question types on the performance of the QA systems.
Sentence Extraction-Based Machine Reading Comprehension for Vietnamese
Jun 11, 2021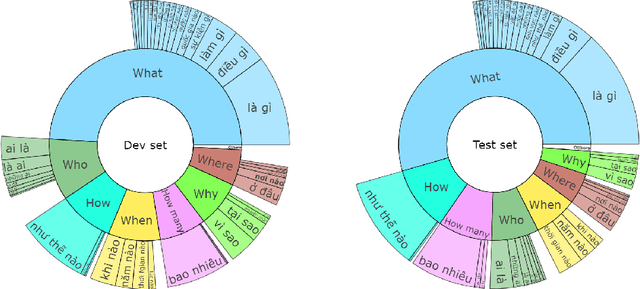
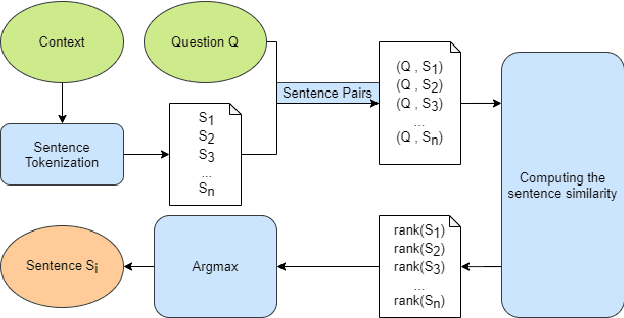
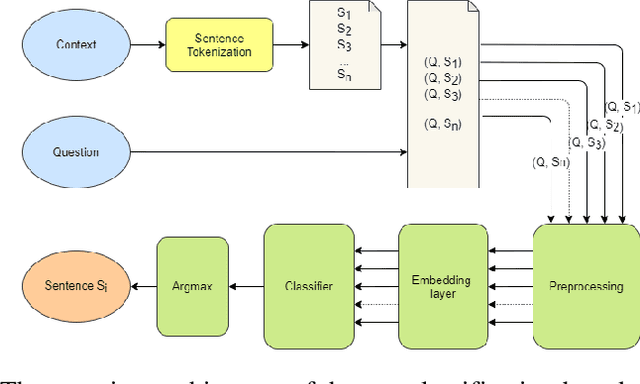
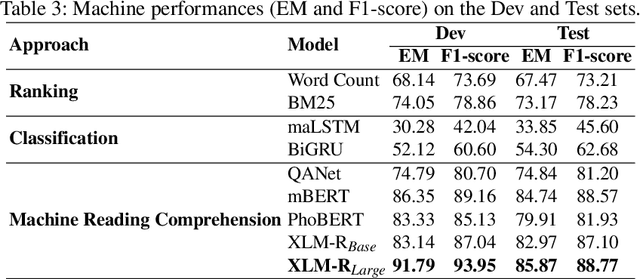
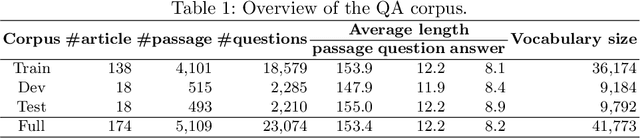
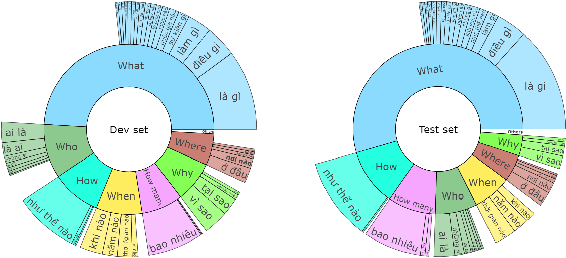
The development of natural language processing (NLP) in general and machine reading comprehension in particular has attracted the great attention of the research community. In recent years, there are a few datasets for machine reading comprehension tasks in Vietnamese with large sizes, such as UIT-ViQuAD and UIT-ViNewsQA. However, the datasets are not diverse in answers to serve the research. In this paper, we introduce UIT-ViWikiQA, the first dataset for evaluating sentence extraction-based machine reading comprehension in the Vietnamese language. The UIT-ViWikiQA dataset is converted from the UIT-ViQuAD dataset, consisting of comprises 23.074 question-answers based on 5.109 passages of 174 Wikipedia Vietnamese articles. We propose a conversion algorithm to create the dataset for sentence extraction-based machine reading comprehension and three types of approaches for sentence extraction-based machine reading comprehension in Vietnamese. Our experiments show that the best machine model is XLM-R_Large, which achieves an exact match (EM) of 85.97% and an F1-score of 88.77% on our dataset. Besides, we analyze experimental results in terms of the question type in Vietnamese and the effect of context on the performance of the MRC models, thereby showing the challenges from the UIT-ViWikiQA dataset that we propose to the language processing community.