 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLSP 2021 - ViMRC Challenge: Vietnamese Machine Reading Comprehension
Paper and Code
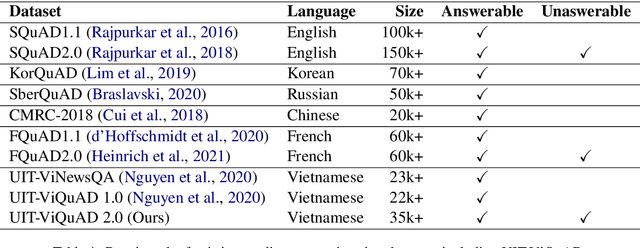
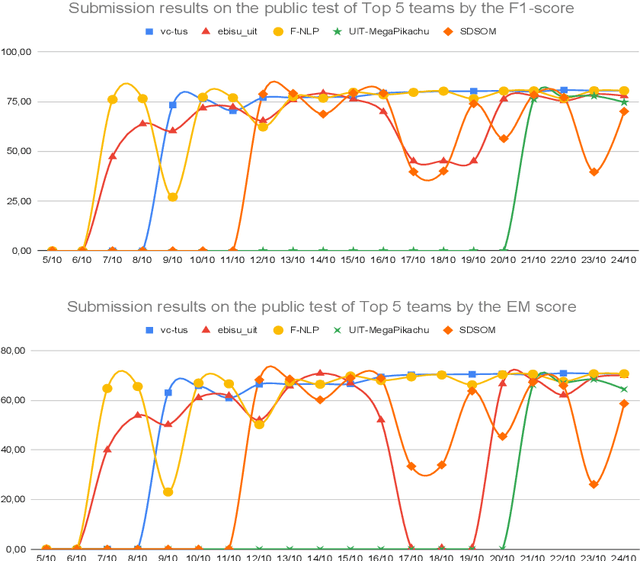

One of the emerging research trends in natural language understanding is machine reading comprehension (MRC) which is the task to find answers to human questions based on textual data. Existing Vietnamese datasets for MRC research concentrate solely on answerable questions. However, in reality, questions can be unanswerable for which the correct answer is not stated in the given textual data. To address the weakness, we provide the research community with a benchmark dataset named UIT-ViQuAD 2.0 for evaluating the MRC task and question answering systems for the Vietnamese language. We use UIT-ViQuAD 2.0 as a benchmark dataset for the challenge on Vietnamese MRC at the Eighth Workshop on Vietnamese Language and Speech Processing (VLSP 2021). This task attracted 77 participant teams from 34 universities and other organizations. In this article, we present details of the organization of the challenge, an overview of the methods employed by shared-task participants, and the results. The highest performances are 77.24% in F1-score and 67.43% in Exact Match on the private test set. The Vietnamese MRC systems proposed by the top 3 teams use XLM-RoBERTa, a powerful pre-trained language model based on the transformer architecture. The UIT-ViQuAD 2.0 dataset motivates researchers to further explore the Vietnamese machine reading comprehension task and related tasks such as question answering, question generation, and natural language inference.