 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Extractive Question Answering Models: Rethinking the Training Methodology
Sep 29, 2024This paper proposes a novel training method to improve the robustness of Extractive Question Answering (EQA) models. Previous research has shown that existing models, when trained on EQA datasets that include unanswerable questions, demonstrate a significant lack of robustness against distribution shifts and adversarial attacks. Despite this, the inclusion of unanswerable questions in EQA training datasets is essential for ensuring real-world reliability. Our proposed training method includes a novel loss function for the EQA problem and challenges an implicit assumption present in numerous EQA datasets. Models trained with our method maintain in-domain performance while achieving a notable improvement on out-of-domain datasets. This results in an overall F1 score improvement of 5.7 across all testing sets. Furthermore, our models exhibit significantly enhanced robustness against two types of adversarial attacks, with a performance decrease of only about a third compared to the default models.
VLUE: A New Benchmark and Multi-task Knowledge Transfer Learning for Vietnamese Natural Language Understanding
Mar 23, 2024The success of Natural Language Understanding (NLU) benchmarks in various languages, such as GLUE for English, CLUE for Chinese, KLUE for Korean, and IndoNLU for Indonesian, has facilitated the evaluation of new NLU models across a wide range of tasks. To establish a standardized set of benchmarks for Vietnamese NLU, we introduce the first Vietnamese Language Understanding Evaluation (VLUE) benchmark. The VLUE benchmark encompasses five datasets covering different NLU tasks, including text classification, span extraction, and natural language understanding. To provide an insightful overview of the current state of Vietnamese NLU, we then evaluate seven state-of-the-art pre-trained models, including both multilingual and Vietnamese monolingual models, on our proposed VLUE benchmark. Furthermore, we present CafeBERT, a new state-of-the-art pre-trained model that achieves superior results across all tasks in the VLUE benchmark. Our model combines the proficiency of a multilingual pre-trained model with Vietnamese linguistic knowledge. CafeBERT is developed based on the XLM-RoBERTa model, with an additional pretraining step utilizing a significant amount of Vietnamese textual data to enhance its adaptation to the Vietnamese language. For the purpose of future research, CafeBERT is made publicly available for research purposes.
AGent: A Novel Pipeline for Automatically Creating Unanswerable Questions
Sep 10, 2023The development of large high-quality datasets and high-performing models have led to significant advancements in the domain of Extractive Question Answering (EQA). This progress has sparked considerable interest in exploring unanswerable questions within the EQA domain. Training EQA models with unanswerable questions helps them avoid extracting misleading or incorrect answers for queries that lack valid responses. However, manually annotating unanswerable questions is labor-intensive. To address this, we propose AGent, a novel pipeline that automatically creates new unanswerable questions by re-matching a question with a context that lacks the necessary information for a correct answer. In this paper, we demonstrate the usefulness of this AGent pipeline by creating two sets of unanswerable questions from answerable questions in SQuAD and HotpotQA. These created question sets exhibit low error rates. Additionally, models fine-tuned on these questions show comparable performance with those fine-tuned on the SQuAD 2.0 dataset on multiple EQA benchmarks.
Single-Sentence Reader: A Novel Approach for Addressing Answer Position Bias
Aug 19, 2023Machine Reading Comprehension (MRC) models tend to take advantage of spurious correlations (also known as dataset bias or annotation artifacts in the research community). Consequently, these models may perform the MRC task without fully comprehending the given context and question, which is undesirable since it may result in low robustness against distribution shift. This paper delves into the concept of answer-position bias, where a significant percentage of training questions have answers located solely in the first sentence of the context. We propose a Single-Sentence Reader as a new approach for addressing answer position bias in MRC. We implement this approach using six different models and thoroughly analyze their performance. Remarkably, our proposed Single-Sentence Readers achieve results that nearly match those of models trained on conventional training sets, proving their effectiveness. Our study also discusses several challenges our Single-Sentence Readers encounter and proposes a potential solution.
Revealing Weaknesses of Vietnamese Language Models Through Unanswerable Questions in Machine Reading Comprehension
Mar 16, 2023



Although the curse of multilinguality significantly restricts the language abilities of multilingual models in monolingual settings, researchers now still have to rely on multilingual models to develop state-of-the-art systems in Vietnamese Machine Reading Comprehension. This difficulty in researching is because of the limited number of high-quality works in developing Vietnamese language models. In order to encourage more work in this research field, we present a comprehensive analysis of language weaknesses and strengths of current Vietnamese monolingual models using the downstream task of Machine Reading Comprehension. From the analysis results, we suggest new directions for developing Vietnamese language models. Besides this main contribution, we also successfully reveal the existence of artifacts in Vietnamese Machine Reading Comprehension benchmarks and suggest an urgent need for new high-quality benchmarks to track the progress of Vietnamese Machine Reading Comprehension. Moreover, we also introduced a minor but valuable modification to the process of annotating unanswerable questions for Machine Reading Comprehension from previous work. Our proposed modification helps improve the quality of unanswerable questions to a higher level of difficulty for Machine Reading Comprehension systems to solve.
The Impacts of Unanswerable Questions on the Robustness of Machine Reading Comprehension Models
Jan 31, 2023



Pretrained language models have achieved super-human performances on many Machine Reading Comprehension (MRC) benchmarks. Nevertheless, their relative inability to defend against adversarial attacks has spurred skepticism about their natural language understanding. In this paper, we ask whether training with unanswerable questions in SQuAD 2.0 can help improve the robustness of MRC models against adversarial attacks. To explore that question, we fine-tune three state-of-the-art language models on either SQuAD 1.1 or SQuAD 2.0 and then evaluate their robustness under adversarial attacks. Our experiments reveal that current models fine-tuned on SQuAD 2.0 do not initially appear to be any more robust than ones fine-tuned on SQuAD 1.1, yet they reveal a measure of hidden robustness that can be leveraged to realize actual performance gains. Furthermore, we find that the robustness of models fine-tuned on SQuAD 2.0 extends to additional out-of-domain datasets. Finally, we introduce a new adversarial attack to reveal artifacts of SQuAD 2.0 that current MRC models are learning.
VLSP 2021 - ViMRC Challenge: Vietnamese Machine Reading Comprehension
Apr 04, 2022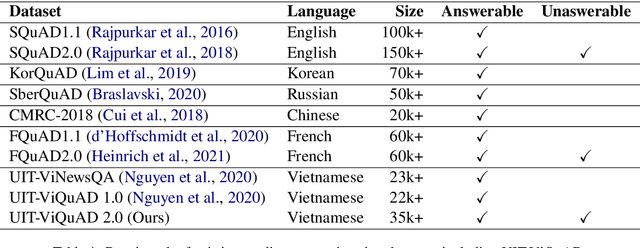
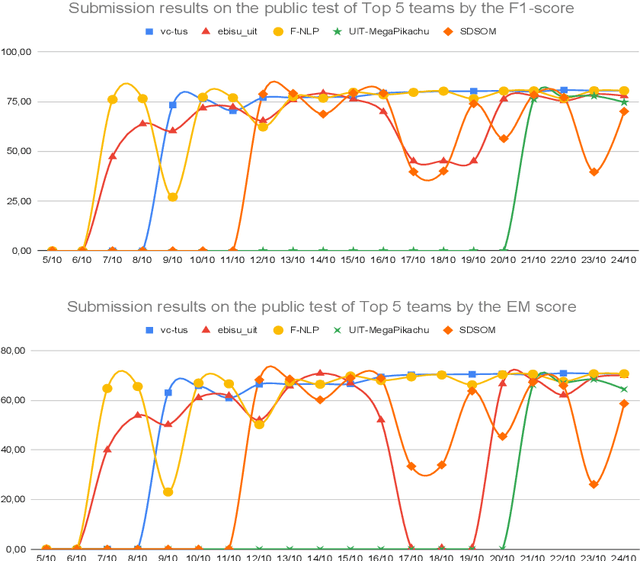

One of the emerging research trends in natural language understanding is machine reading comprehension (MRC) which is the task to find answers to human questions based on textual data. Existing Vietnamese datasets for MRC research concentrate solely on answerable questions. However, in reality, questions can be unanswerable for which the correct answer is not stated in the given textual data. To address the weakness, we provide the research community with a benchmark dataset named UIT-ViQuAD 2.0 for evaluating the MRC task and question answering systems for the Vietnamese language. We use UIT-ViQuAD 2.0 as a benchmark dataset for the challenge on Vietnamese MRC at the Eighth Workshop on Vietnamese Language and Speech Processing (VLSP 2021). This task attracted 77 participant teams from 34 universities and other organizations. In this article, we present details of the organization of the challenge, an overview of the methods employed by shared-task participants, and the results. The highest performances are 77.24% in F1-score and 67.43% in Exact Match on the private test set. The Vietnamese MRC systems proposed by the top 3 teams use XLM-RoBERTa, a powerful pre-trained language model based on the transformer architecture. The UIT-ViQuAD 2.0 dataset motivates researchers to further explore the Vietnamese machine reading comprehension task and related tasks such as question answering, question generation, and natural language inference.