 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViGoEmotions: A Benchmark Dataset For Fine-grained Emotion Detection on Vietnamese Texts
Feb 09, 2026Emotion classification plays a significant role in emotion prediction and harmful content detection. Recent advancements in NLP, particularly through large language models (LLMs), have greatly improved outcomes in this field. This study introduces ViGoEmotions -- a Vietnamese emotion corpus comprising 20,664 social media comments in which each comment is classified into 27 fine-grained distinct emotions. To evaluate the quality of the dataset and its impact on emotion classification, eight pre-trained Transformer-based models were evaluated under three preprocessing strategies: preserving original emojis with rule-based normalization, converting emojis into textual descriptions, and applying ViSoLex, a model-based lexical normalization system. Results show that converting emojis into text often improves the performance of several BERT-based baselines, while preserving emojis yields the best results for ViSoBERT and CafeBERT. In contrast, removing emojis generally leads to lower performance. ViSoBERT achieved the highest Macro F1-score of 61.50% and Weighted F1-score of 63.26%. Strong performance was also observed from CafeBERT and PhoBERT. These findings highlight that while the proposed corpus can support diverse architectures effectively, preprocessing strategies and annotation quality remain key factors influencing downstream performance.
VLSP 2025 MLQA-TSR Challenge: Vietnamese Multimodal Legal Question Answering on Traffic Sign Regulation
Oct 23, 2025This paper presents the VLSP 2025 MLQA-TSR - the multimodal legal question answering on traffic sign regulation shared task at VLSP 2025. VLSP 2025 MLQA-TSR comprises two subtasks: multimodal legal retrieval and multimodal question answering. The goal is to advance research on Vietnamese multimodal legal text processing and to provide a benchmark dataset for building and evaluating intelligent systems in multimodal legal domains, with a focus on traffic sign regulation in Vietnam. The best-reported results on VLSP 2025 MLQA-TSR are an F2 score of 64.55% for multimodal legal retrieval and an accuracy of 86.30% for multimodal question answering.
AS400-DET: Detection using Deep Learning Model for IBM i (AS/400)
Jun 16, 2025



This paper proposes a method for automatic GUI component detection for the IBM i system (formerly and still more commonly known as AS/400). We introduce a human-annotated dataset consisting of 1,050 system screen images, in which 381 images are screenshots of IBM i system screens in Japanese. Each image contains multiple components, including text labels, text boxes, options, tables, instructions, keyboards, and command lines. We then develop a detection system based on state-of-the-art deep learning models and evaluate different approaches using our dataset. The experimental results demonstrate the effectiveness of our dataset in constructing a system for component detection from GUI screens. By automatically detecting GUI components from the screen, AS400-DET has the potential to perform automated testing on systems that operate via GUI screens.
ViMRHP: A Vietnamese Benchmark Dataset for Multimodal Review Helpfulness Prediction via Human-AI Collaborative Annotation
May 12, 2025Multimodal Review Helpfulness Prediction (MRHP) is an essential task in recommender systems, particularly in E-commerce platforms. Determining the helpfulness of user-generated reviews enhances user experience and improves consumer decision-making. However, existing datasets focus predominantly on English and Indonesian, resulting in a lack of linguistic diversity, especially for low-resource languages such as Vietnamese. In this paper, we introduce ViMRHP (Vietnamese Multimodal Review Helpfulness Prediction), a large-scale benchmark dataset for MRHP task in Vietnamese. This dataset covers four domains, including 2K products with 46K reviews. Meanwhile, a large-scale dataset requires considerable time and cost. To optimize the annotation process, we leverage AI to assist annotators in constructing the ViMRHP dataset. With AI assistance, annotation time is reduced (90 to 120 seconds per task down to 20 to 40 seconds per task) while maintaining data quality and lowering overall costs by approximately 65%. However, AI-generated annotations still have limitations in complex annotation tasks, which we further examine through a detailed performance analysis. In our experiment on ViMRHP, we evaluate baseline models on human-verified and AI-generated annotations to assess their quality differences. The ViMRHP dataset is publicly available at https://github.com/trng28/ViMRHP
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
ZeFaV: Boosting Large Language Models for Zero-shot Fact Verification
Nov 18, 2024In this paper, we propose ZeFaV - a zero-shot based fact-checking verification framework to enhance the performance on fact verification task of large language models by leveraging the in-context learning ability of large language models to extract the relations among the entities within a claim, re-organized the information from the evidence in a relationally logical form, and combine the above information with the original evidence to generate the context from which our fact-checking model provide verdicts for the input claims. We conducted empirical experiments to evaluate our approach on two multi-hop fact-checking datasets including HoVer and FEVEROUS, and achieved potential results results comparable to other state-of-the-art fact verification task methods.
Metadata Integration for Spam Reviews Detection on Vietnamese E-commerce Websites
May 22, 2024



The problem of detecting spam reviews (opinions) has received significant attention in recent years, especially with the rapid development of e-commerce. Spam reviews are often classified based on comment content, but in some cases, it is insufficient for models to accurately determine the review label. In this work, we introduce the ViSpamReviews v2 dataset, which includes metadata of reviews with the objective of integrating supplementary attributes for spam review classification. We propose a novel approach to simultaneously integrate both textual and categorical attributes into the classification model. In our experiments, the product category proved effective when combined with deep neural network (DNN) models, while text features performed well on both DNN models and the model achieved state-of-the-art performance in the problem of detecting spam reviews on Vietnamese e-commerce websites, namely PhoBERT. Specifically, the PhoBERT model achieves the highest accuracy when combined with product description features generated from the SPhoBert model, which is the combination of PhoBERT and SentenceBERT. Using the macro-averaged F1 score, the task of classifying spam reviews achieved 87.22% (an increase of 1.64% compared to the baseline), while the task of identifying the type of spam reviews achieved an accuracy of 73.49% (an increase of 1.93% compared to the baseline).
Exploiting Hatred by Targets for Hate Speech Detection on Vietnamese Social Media Texts
Apr 30, 2024

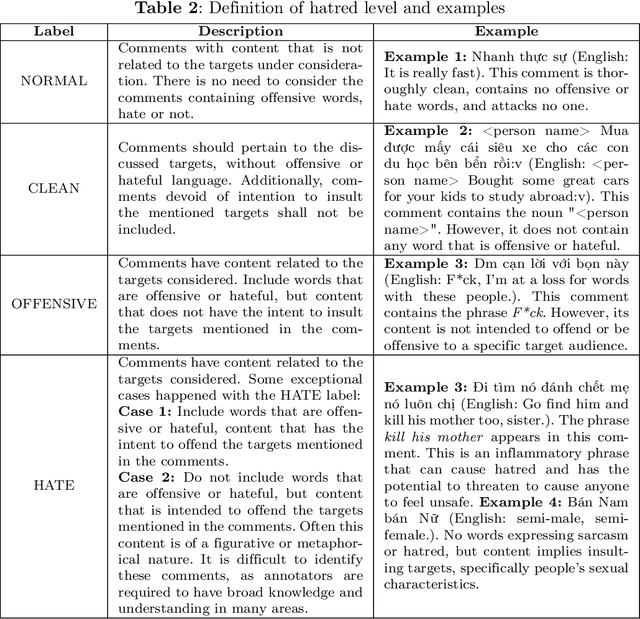
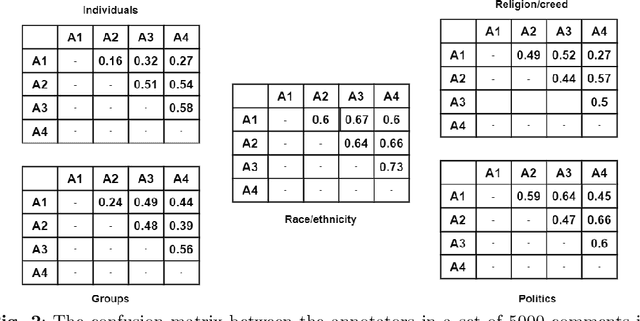
The growth of social networks makes toxic content spread rapidly. Hate speech detection is a task to help decrease the number of harmful comments. With the diversity in the hate speech created by users, it is necessary to interpret the hate speech besides detecting it. Hence, we propose a methodology to construct a system for targeted hate speech detection from online streaming texts from social media. We first introduce the ViTHSD - a targeted hate speech detection dataset for Vietnamese Social Media Texts. The dataset contains 10K comments, each comment is labeled to specific targets with three levels: clean, offensive, and hate. There are 5 targets in the dataset, and each target is labeled with the corresponding level manually by humans with strict annotation guidelines. The inter-annotator agreement obtained from the dataset is 0.45 by Cohen's Kappa index, which is indicated as a moderate level. Then, we construct a baseline for this task by combining the Bi-GRU-LSTM-CNN with the pre-trained language model to leverage the power of text representation of BERTology. Finally, we suggest a methodology to integrate the baseline model for targeted hate speech detection into the online streaming system for practical application in preventing hateful and offensive content on social media.
VLSP 2023 -- LTER: A Summary of the Challenge on Legal Textual Entailment Recognition
Mar 06, 2024


In this new era of rapid AI development, especially in language processing, the demand for AI in the legal domain is increasingly critical. In the context where research in other languages such as English, Japanese, and Chinese has been well-established, we introduce the first fundamental research for the Vietnamese language in the legal domain: legal textual entailment recognition through the Vietnamese Language and Speech Processing workshop. In analyzing participants' results, we discuss certain linguistic aspects critical in the legal domain that pose challenges that need to be addressed.
VlogQA: Task, Dataset, and Baseline Models for Vietnamese Spoken-Based Machine Reading Comprehension
Feb 05, 2024



This paper presents the development process of a Vietnamese spoken language corpus for machine reading comprehension (MRC) tasks and provides insights into the challenges and opportunities associated with using real-world data for machine reading comprehension tasks. The existing MRC corpora in Vietnamese mainly focus on formal written documents such as Wikipedia articles, online newspapers, or textbooks. In contrast, the VlogQA consists of 10,076 question-answer pairs based on 1,230 transcript documents sourced from YouTube -- an extensive source of user-uploaded content, covering the topics of food and travel. By capturing the spoken language of native Vietnamese speakers in natural settings, an obscure corner overlooked in Vietnamese research, the corpus provides a valuable resource for future research in reading comprehension tasks for the Vietnamese language. Regarding performance evaluation, our deep-learning models achieved the highest F1 score of 75.34% on the test set, indicating significant progress in machine reading comprehension for Vietnamese spoken language data. In terms of EM, the highest score we accomplished is 53.97%, which reflects the challenge in processing spoken-based content and highlights the need for further improvement.