 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomize Multi-modal RAI Guardrails with Precedent-based predictions
Jul 28, 2025



A multi-modal guardrail must effectively filter image content based on user-defined policies, identifying material that may be hateful, reinforce harmful stereotypes, contain explicit material, or spread misinformation. Deploying such guardrails in real-world applications, however, poses significant challenges. Users often require varied and highly customizable policies and typically cannot provide abundant examples for each custom policy. Consequently, an ideal guardrail should be scalable to the multiple policies and adaptable to evolving user standards with minimal retraining. Existing fine-tuning methods typically condition predictions on pre-defined policies, restricting their generalizability to new policies or necessitating extensive retraining to adapt. Conversely, training-free methods struggle with limited context lengths, making it difficult to incorporate all the policies comprehensively. To overcome these limitations, we propose to condition model's judgment on "precedents", which are the reasoning processes of prior data points similar to the given input. By leveraging precedents instead of fixed policies, our approach greatly enhances the flexibility and adaptability of the guardrail. In this paper, we introduce a critique-revise mechanism for collecting high-quality precedents and two strategies that utilize precedents for robust prediction. Experimental results demonstrate that our approach outperforms previous methods across both few-shot and full-dataset scenarios and exhibits superior generalization to novel policies.
AS400-DET: Detection using Deep Learning Model for IBM i (AS/400)
Jun 16, 2025



This paper proposes a method for automatic GUI component detection for the IBM i system (formerly and still more commonly known as AS/400). We introduce a human-annotated dataset consisting of 1,050 system screen images, in which 381 images are screenshots of IBM i system screens in Japanese. Each image contains multiple components, including text labels, text boxes, options, tables, instructions, keyboards, and command lines. We then develop a detection system based on state-of-the-art deep learning models and evaluate different approaches using our dataset. The experimental results demonstrate the effectiveness of our dataset in constructing a system for component detection from GUI screens. By automatically detecting GUI components from the screen, AS400-DET has the potential to perform automated testing on systems that operate via GUI screens.
Tree-Sliced Wasserstein Distance with Nonlinear Projection
May 02, 2025



Tree-Sliced methods have recently emerged as an alternative to the traditional Sliced Wasserstein (SW) distance, replacing one-dimensional lines with tree-based metric spaces and incorporating a splitting mechanism for projecting measures. This approach enhances the ability to capture the topological structures of integration domains in Sliced Optimal Transport while maintaining low computational costs. Building on this foundation, we propose a novel nonlinear projectional framework for the Tree-Sliced Wasserstein (TSW) distance, substituting the linear projections in earlier versions with general projections, while ensuring the injectivity of the associated Radon Transform and preserving the well-definedness of the resulting metric. By designing appropriate projections, we construct efficient metrics for measures on both Euclidean spaces and spheres. Finally, we validate our proposed metric through extensive numerical experiments for Euclidean and spherical datasets. Applications include gradient flows, self-supervised learning, and generative models, where our methods demonstrate significant improvements over recent SW and TSW variants.
Equivariant Polynomial Functional Networks
Oct 05, 2024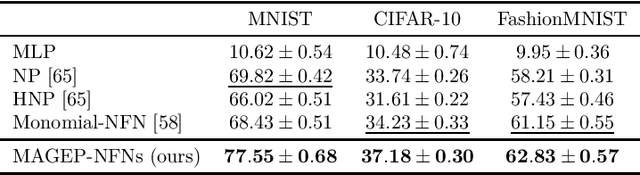



Neural Functional Networks (NFNs) have gained increasing interest due to their wide range of applications, including extracting information from implicit representations of data, editing network weights, and evaluating policies. A key design principle of NFNs is their adherence to the permutation and scaling symmetries inherent in the connectionist structure of the input neural networks. Recent NFNs have been proposed with permutation and scaling equivariance based on either graph-based message-passing mechanisms or parameter-sharing mechanisms. However, graph-based equivariant NFNs suffer from high memory consumption and long running times. On the other hand, parameter-sharing-based NFNs built upon equivariant linear layers exhibit lower memory consumption and faster running time, yet their expressivity is limited due to the large size of the symmetric group of the input neural networks. The challenge of designing a permutation and scaling equivariant NFN that maintains low memory consumption and running time while preserving expressivity remains unresolved. In this paper, we propose a novel solution with the development of MAGEP-NFN (Monomial mAtrix Group Equivariant Polynomial NFN). Our approach follows the parameter-sharing mechanism but differs from previous works by constructing a nonlinear equivariant layer represented as a polynomial in the input weights. This polynomial formulation enables us to incorporate additional relationships between weights from different input hidden layers, enhancing the model's expressivity while keeping memory consumption and running time low, thereby addressing the aforementioned challenge. We provide empirical evidence demonstrating that MAGEP-NFN achieves competitive performance and efficiency compared to existing baselines.
Equivariant Neural Functional Networks for Transformers
Oct 05, 2024


This paper systematically explores neural functional networks (NFN) for transformer architectures. NFN are specialized neural networks that treat the weights, gradients, or sparsity patterns of a deep neural network (DNN) as input data and have proven valuable for tasks such as learnable optimizers, implicit data representations, and weight editing. While NFN have been extensively developed for MLP and CNN, no prior work has addressed their design for transformers, despite the importance of transformers in modern deep learning. This paper aims to address this gap by providing a systematic study of NFN for transformers. We first determine the maximal symmetric group of the weights in a multi-head attention module as well as a necessary and sufficient condition under which two sets of hyperparameters of the multi-head attention module define the same function. We then define the weight space of transformer architectures and its associated group action, which leads to the design principles for NFN in transformers. Based on these, we introduce Transformer-NFN, an NFN that is equivariant under this group action. Additionally, we release a dataset of more than 125,000 Transformers model checkpoints trained on two datasets with two different tasks, providing a benchmark for evaluating Transformer-NFN and encouraging further research on transformer training and performance.
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Apr 04, 2024



We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., <1B) language model (LM) for guiding a black-box large (i.e., >10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
CAPTAIN at COLIEE 2023: Efficient Methods for Legal Information Retrieval and Entailment Tasks
Jan 07, 2024The Competition on Legal Information Extraction/Entailment (COLIEE) is held annually to encourage advancements in the automatic processing of legal texts. Processing legal documents is challenging due to the intricate structure and meaning of legal language. In this paper, we outline our strategies for tackling Task 2, Task 3, and Task 4 in the COLIEE 2023 competition. Our approach involved utilizing appropriate state-of-the-art deep learning methods, designing methods based on domain characteristics observation, and applying meticulous engineering practices and methodologies to the competition. As a result, our performance in these tasks has been outstanding, with first places in Task 2 and Task 3, and promising results in Task 4. Our source code is available at https://github.com/Nguyen2015/CAPTAIN-COLIEE2023/tree/coliee2023.
An artificial neural network-based system for detecting machine failures using tiny sound data: A case study
Sep 23, 2022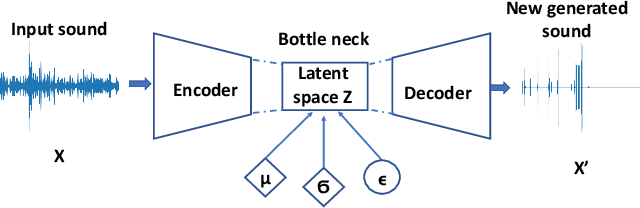
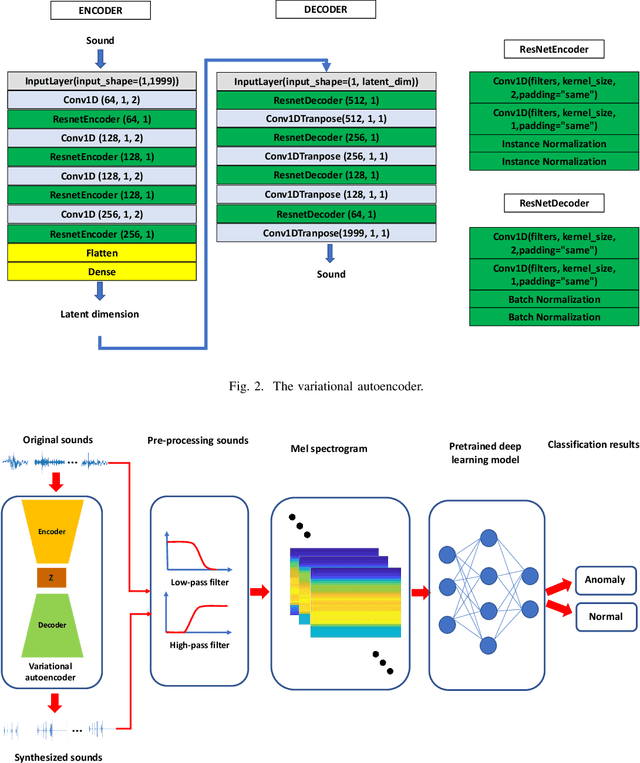
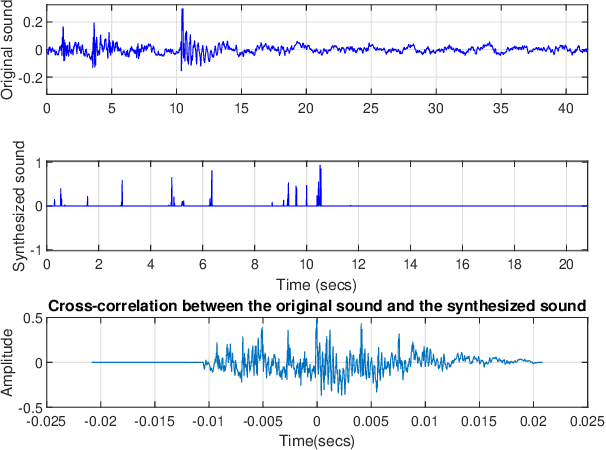
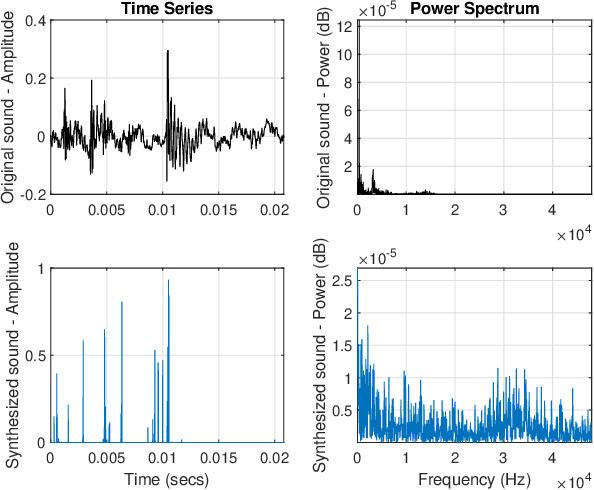
In an effort to advocate the research for a deep learning-based machine failure detection system, we present a case study of our proposed system based on a tiny sound dataset. Our case study investigates a variational autoencoder (VAE) for augmenting a small drill sound dataset from Valmet AB. A Valmet dataset contains 134 sounds that have been divided into two categories: "Anomaly" and "Normal" recorded from a drilling machine in Valmet AB, a company in Sundsvall, Sweden that supplies equipment and processes for the production of biofuels. Using deep learning models to detect failure drills on such a small sound dataset is typically unsuccessful. We employed a VAE to increase the number of sounds in the tiny dataset by synthesizing new sounds from original sounds. The augmented dataset was created by combining these synthesized sounds with the original sounds. We used a high-pass filter with a passband frequency of 1000 Hz and a low-pass filter with a passband frequency of 22\kern 0.16667em000 Hz to pre-process sounds in the augmented dataset before transforming them to Mel spectrograms. The pre-trained 2D-CNN Alexnet was then trained using these Mel spectrograms. When compared to using the original tiny sound dataset to train pre-trained Alexnet, using the augmented sound dataset enhanced the CNN model's classification results by 6.62\%(94.12\% when trained on the augmented dataset versus 87.5\% when trained on the original dataset).
Denoising Induction Motor Sounds Using an Autoencoder
Aug 08, 2022
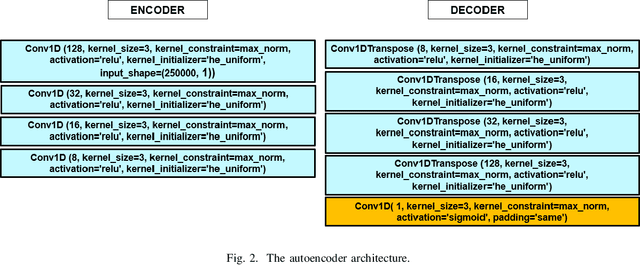
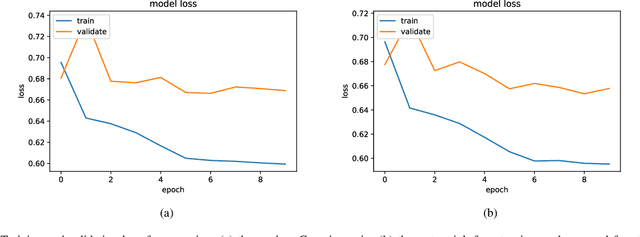
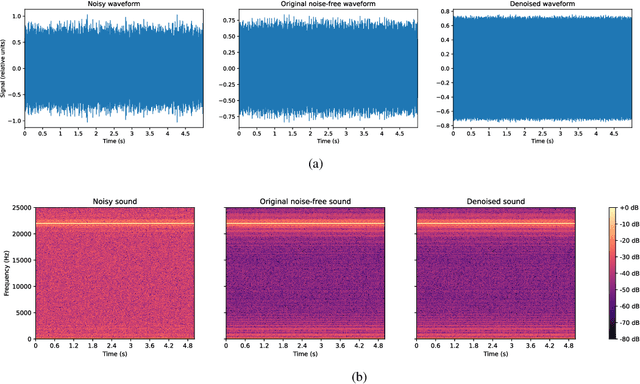
Denoising is the process of removing noise from sound signals while improving the quality and adequacy of the sound signals. Denoising sound has many applications in speech processing, sound events classification, and machine failure detection systems. This paper describes a method for creating an autoencoder to map noisy machine sounds to clean sounds for denoising purposes. There are several types of noise in sounds, for example, environmental noise and generated frequency-dependent noise from signal processing methods. Noise generated by environmental activities is environmental noise. In the factory, environmental noise can be created by vehicles, drilling, people working or talking in the survey area, wind, and flowing water. Those noises appear as spikes in the sound record. In the scope of this paper, we demonstrate the removal of generated noise with Gaussian distribution and the environmental noise with a specific example of the water sink faucet noise from the induction motor sounds. The proposed method was trained and verified on 49 normal function sounds and 197 horizontal misalignment fault sounds from the Machinery Fault Database (MAFAULDA). The mean square error (MSE) was used as the assessment criteria to evaluate the similarity between denoised sounds using the proposed autoencoder and the original sounds in the test set. The MSE is below or equal to 0.14 when denoise both types of noises on 15 testing sounds of the normal function category. The MSE is below or equal to 0.15 when denoising 60 testing sounds on the horizontal misalignment fault category. The low MSE shows that both the generated Gaussian noise and the environmental noise were almost removed from the original sounds with the proposed trained autoencoder.
A neural prosody encoder for end-ro-end dialogue act classification
May 11, 2022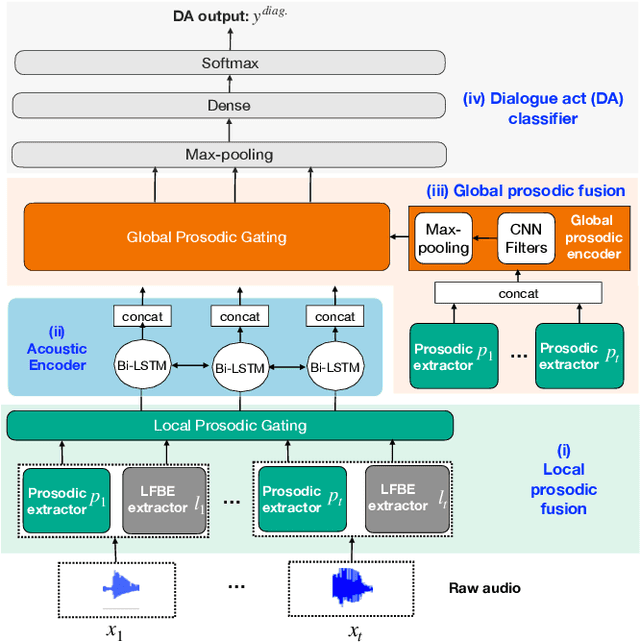
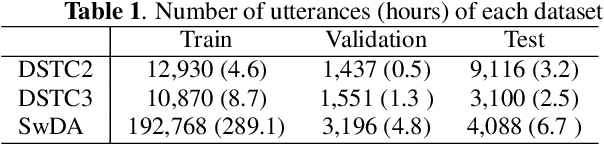
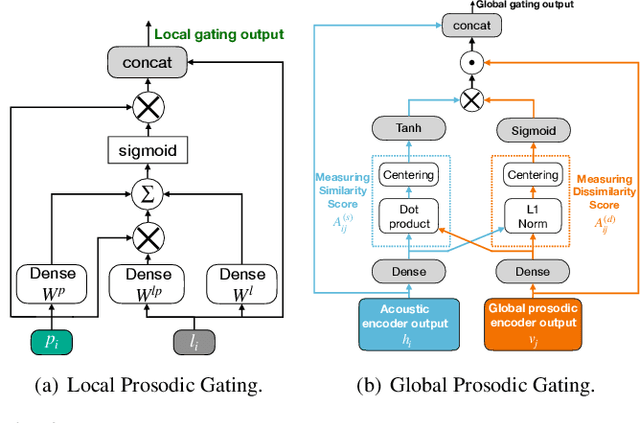

Dialogue act classification (DAC) is a critical task for spoken language understanding in dialogue systems. Prosodic features such as energy and pitch have been shown to be useful for DAC. Despite their importance, little research has explored neural approaches to integrate prosodic features into end-to-end (E2E) DAC models which infer dialogue acts directly from audio signals. In this work, we propose an E2E neural architecture that takes into account the need for characterizing prosodic phenomena co-occurring at different levels inside an utterance. A novel part of this architecture is a learnable gating mechanism that assesses the importance of prosodic features and selectively retains core information necessary for E2E DAC. Our proposed model improves DAC accuracy by 1.07% absolute across three publicly available benchmark datasets.