 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Polynomial Functional Networks
Oct 05, 2024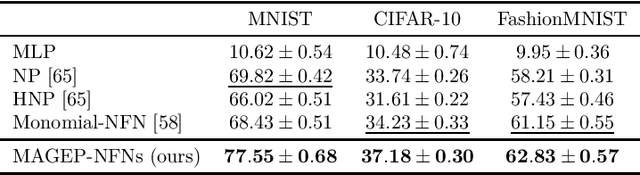



Neural Functional Networks (NFNs) have gained increasing interest due to their wide range of applications, including extracting information from implicit representations of data, editing network weights, and evaluating policies. A key design principle of NFNs is their adherence to the permutation and scaling symmetries inherent in the connectionist structure of the input neural networks. Recent NFNs have been proposed with permutation and scaling equivariance based on either graph-based message-passing mechanisms or parameter-sharing mechanisms. However, graph-based equivariant NFNs suffer from high memory consumption and long running times. On the other hand, parameter-sharing-based NFNs built upon equivariant linear layers exhibit lower memory consumption and faster running time, yet their expressivity is limited due to the large size of the symmetric group of the input neural networks. The challenge of designing a permutation and scaling equivariant NFN that maintains low memory consumption and running time while preserving expressivity remains unresolved. In this paper, we propose a novel solution with the development of MAGEP-NFN (Monomial mAtrix Group Equivariant Polynomial NFN). Our approach follows the parameter-sharing mechanism but differs from previous works by constructing a nonlinear equivariant layer represented as a polynomial in the input weights. This polynomial formulation enables us to incorporate additional relationships between weights from different input hidden layers, enhancing the model's expressivity while keeping memory consumption and running time low, thereby addressing the aforementioned challenge. We provide empirical evidence demonstrating that MAGEP-NFN achieves competitive performance and efficiency compared to existing baselines.
Equivariant Neural Functional Networks for Transformers
Oct 05, 2024


This paper systematically explores neural functional networks (NFN) for transformer architectures. NFN are specialized neural networks that treat the weights, gradients, or sparsity patterns of a deep neural network (DNN) as input data and have proven valuable for tasks such as learnable optimizers, implicit data representations, and weight editing. While NFN have been extensively developed for MLP and CNN, no prior work has addressed their design for transformers, despite the importance of transformers in modern deep learning. This paper aims to address this gap by providing a systematic study of NFN for transformers. We first determine the maximal symmetric group of the weights in a multi-head attention module as well as a necessary and sufficient condition under which two sets of hyperparameters of the multi-head attention module define the same function. We then define the weight space of transformer architectures and its associated group action, which leads to the design principles for NFN in transformers. Based on these, we introduce Transformer-NFN, an NFN that is equivariant under this group action. Additionally, we release a dataset of more than 125,000 Transformers model checkpoints trained on two datasets with two different tasks, providing a benchmark for evaluating Transformer-NFN and encouraging further research on transformer training and performance.
NeuroMax: Enhancing Neural Topic Modeling via Maximizing Mutual Information and Group Topic Regularization
Sep 29, 2024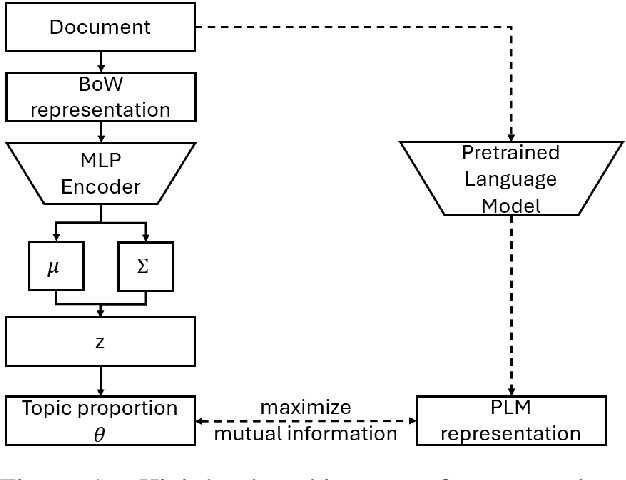
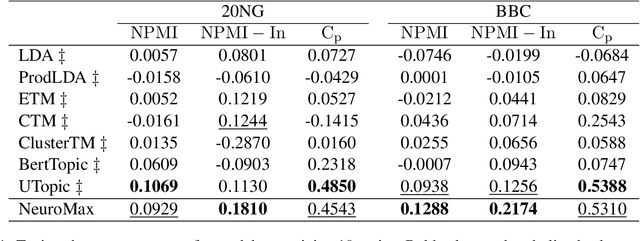
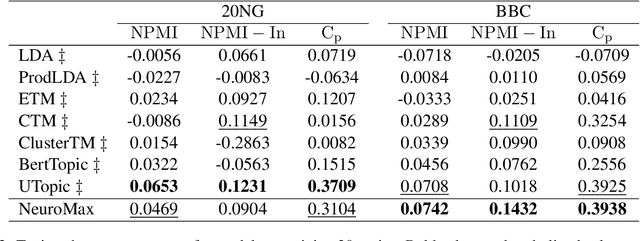
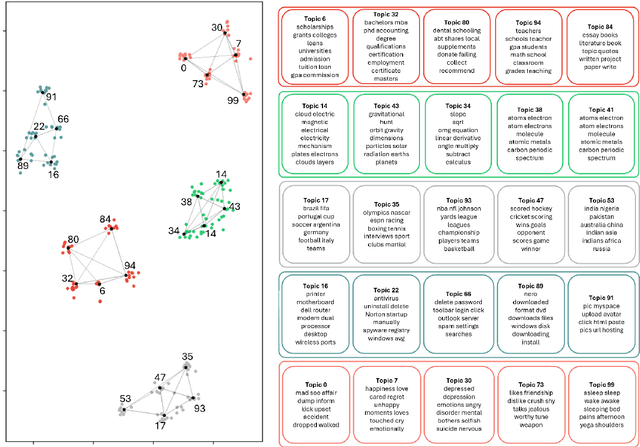
Recent advances in neural topic models have concentrated on two primary directions: the integration of the inference network (encoder) with a pre-trained language model (PLM) and the modeling of the relationship between words and topics in the generative model (decoder). However, the use of large PLMs significantly increases inference costs, making them less practical for situations requiring low inference times. Furthermore, it is crucial to simultaneously model the relationships between topics and words as well as the interrelationships among topics themselves. In this work, we propose a novel framework called NeuroMax (Neural Topic Model with Maximizing Mutual Information with Pretrained Language Model and Group Topic Regularization) to address these challenges. NeuroMax maximizes the mutual information between the topic representation obtained from the encoder in neural topic models and the representation derived from the PLM. Additionally, NeuroMax employs optimal transport to learn the relationships between topics by analyzing how information is transported among them. Experimental results indicate that NeuroMax reduces inference time, generates more coherent topics and topic groups, and produces more representative document embeddings, thereby enhancing performance on downstream tasks.