 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Federated Graph Recommendation with LLM-encoded knowledge
Jun 13, 2026Graph-based recommender systems are highly effective at extracting collaborative signals from user--item interactions, and federated learning (FL) allows these models to be trained while preserving user privacy. However, aggregating graph representations across distributed, non-IID clients remains a challenge; structural embeddings learned locally often misalign, and naive averaging fails to capture meaningful cross-client relationships. Most existing federated graph methods rely exclusively on structural aggregation, neglecting the rich, global semantic context available in large language models (LLMs). In this paper, we propose a novel framework that uses LLM-encoded knowledge to guide federated graph recommendation. Specifically, clients learn structural representations from local graphs while simultaneously summarizing their typical interaction patterns into compact semantic vectors via a frozen LLM. The central server then uses these LLM-encoded semantic signals to discover related preference patterns across clients, guiding the selective aggregation of their structural representations. This enables semantically informed cross-client collaboration without exposing raw data. Extensive experiments on standard benchmarks show that guiding structural alignment with LLM-encoded knowledge consistently improves recommendation accuracy over existing federated graph baselines.
Empowering Contrastive Federated Sequential Recommendation with LLMs
Feb 10, 2026Federated sequential recommendation (FedSeqRec) aims to perform next-item prediction while keeping user data decentralised, yet model quality is frequently constrained by fragmented, noisy, and homogeneous interaction logs stored on individual devices. Many existing approaches attempt to compensate through manual data augmentation or additional server-side constraints, but these strategies either introduce limited semantic diversity or increase system overhead. To overcome these challenges, we propose \textbf{LUMOS}, a parameter-isolated FedSeqRec architecture that integrates large language models (LLMs) as \emph{local semantic generators}. Instead of sharing gradients or auxiliary parameters, LUMOS privately invokes an on-device LLM to construct three complementary sequence variants from each user history: (i) \emph{future-oriented} trajectories that infer plausible behavioural continuations, (ii) \emph{semantically equivalent rephrasings} that retain user intent while diversifying interaction patterns, and (iii) \emph{preference-inconsistent counterfactuals} that serve as informative negatives. These synthesized sequences are jointly encoded within the federated backbone through a tri-view contrastive optimisation scheme, enabling richer representation learning without exposing sensitive information. Experimental results across three public benchmarks show that LUMOS achieves consistent gains over competitive centralised and federated baselines on HR@20 and NDCG@20. In addition, the use of semantically grounded positive signals and counterfactual negatives improves robustness under noisy and adversarial environments, even without dedicated server-side protection modules. Overall, this work demonstrates the potential of LLM-driven semantic generation as a new paradigm for advancing privacy-preserving federated recommendation.
Selective Sinkhorn Routing for Improved Sparse Mixture of Experts
Nov 12, 2025



Sparse Mixture-of-Experts (SMoE) has gained prominence as a scalable and computationally efficient architecture, enabling significant growth in model capacity without incurring additional inference costs. However, existing SMoE models often rely on auxiliary losses (e.g., z-loss, load balancing) and additional trainable parameters (e.g., noisy gating) to encourage expert diversity, leading to objective misalignment and increased model complexity. Moreover, existing Sinkhorn-based methods suffer from significant training overhead due to their heavy reliance on the computationally expensive Sinkhorn algorithm. In this work, we formulate token-to-expert assignment as an optimal transport problem, incorporating constraints to ensure balanced expert utilization. We demonstrate that introducing a minimal degree of optimal transport-based routing enhances SMoE performance without requiring auxiliary balancing losses. Unlike previous methods, our approach derives gating scores directly from the transport map, enabling more effective token-to-expert balancing, supported by both theoretical analysis and empirical results. Building on these insights, we propose Selective Sinkhorn Routing (SSR), a routing mechanism that replaces auxiliary loss with lightweight Sinkhorn-based routing. SSR promotes balanced token assignments while preserving flexibility in expert selection. Across both language modeling and image classification tasks, SSR achieves faster training, higher accuracy, and greater robustness to input corruption.
RangeSAM: Leveraging Visual Foundation Models for Range-View repesented LiDAR segmentation
Sep 19, 2025Point cloud segmentation is central to autonomous driving and 3D scene understanding. While voxel- and point-based methods dominate recent research due to their compatibility with deep architectures and ability to capture fine-grained geometry, they often incur high computational cost, irregular memory access, and limited real-time efficiency. In contrast, range-view methods, though relatively underexplored - can leverage mature 2D semantic segmentation techniques for fast and accurate predictions. Motivated by the rapid progress in Visual Foundation Models (VFMs) for captioning, zero-shot recognition, and multimodal tasks, we investigate whether SAM2, the current state-of-the-art VFM for segmentation tasks, can serve as a strong backbone for LiDAR point cloud segmentation in the range view. We present , to our knowledge, the first range-view framework that adapts SAM2 to 3D segmentation, coupling efficient 2D feature extraction with standard projection/back-projection to operate on point clouds. To optimize SAM2 for range-view representations, we implement several architectural modifications to the encoder: (1) a novel module that emphasizes horizontal spatial dependencies inherent in LiDAR range images, (2) a customized configuration of tailored to the geometric properties of spherical projections, and (3) an adapted mechanism in the encoder backbone specifically designed to capture the unique spatial patterns and discontinuities present in range-view pseudo-images. Our approach achieves competitive performance on SemanticKITTI while benefiting from the speed, scalability, and deployment simplicity of 2D-centric pipelines. This work highlights the viability of VFMs as general-purpose backbones for 3D perception and opens a path toward unified, foundation-model-driven LiDAR segmentation. Results lets us conclude that range-view segmentation methods using VFMs leads to promising results.
Hierarchical Neural Collapse Detection Transformer for Class Incremental Object Detection
Jun 10, 2025Recently, object detection models have witnessed notable performance improvements, particularly with transformer-based models. However, new objects frequently appear in the real world, requiring detection models to continually learn without suffering from catastrophic forgetting. Although Incremental Object Detection (IOD) has emerged to address this challenge, these existing models are still not practical due to their limited performance and prolonged inference time. In this paper, we introduce a novel framework for IOD, called Hier-DETR: Hierarchical Neural Collapse Detection Transformer, ensuring both efficiency and competitive performance by leveraging Neural Collapse for imbalance dataset and Hierarchical relation of classes' labels.
Time to Spike? Understanding the Representational Power of Spiking Neural Networks in Discrete Time
May 23, 2025



Recent years have seen significant progress in developing spiking neural networks (SNNs) as a potential solution to the energy challenges posed by conventional artificial neural networks (ANNs). However, our theoretical understanding of SNNs remains relatively limited compared to the ever-growing body of literature on ANNs. In this paper, we study a discrete-time model of SNNs based on leaky integrate-and-fire (LIF) neurons, referred to as discrete-time LIF-SNNs, a widely used framework that still lacks solid theoretical foundations. We demonstrate that discrete-time LIF-SNNs with static inputs and outputs realize piecewise constant functions defined on polyhedral regions, and more importantly, we quantify the network size required to approximate continuous functions. Moreover, we investigate the impact of latency (number of time steps) and depth (number of layers) on the complexity of the input space partitioning induced by discrete-time LIF-SNNs. Our analysis highlights the importance of latency and contrasts these networks with ANNs employing piecewise linear activation functions. Finally, we present numerical experiments to support our theoretical findings.
GloCOM: A Short Text Neural Topic Model via Global Clustering Context
Nov 30, 2024
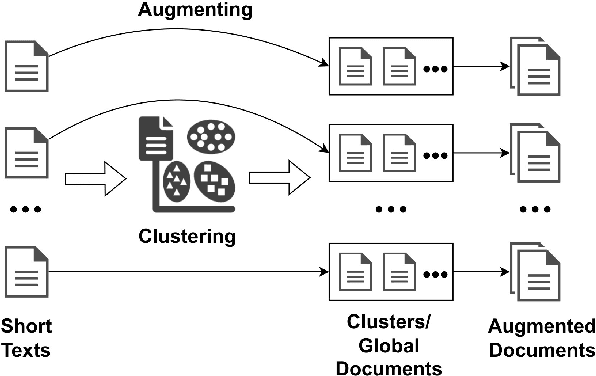
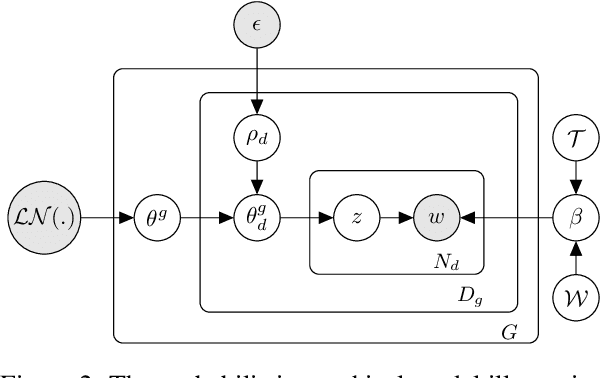
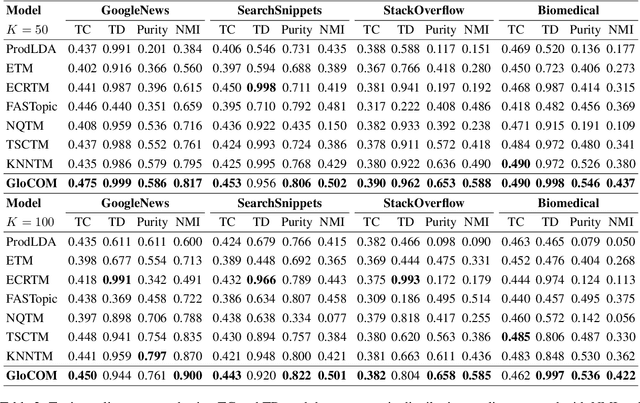
Uncovering hidden topics from short texts is challenging for traditional and neural models due to data sparsity, which limits word co-occurrence patterns, and label sparsity, stemming from incomplete reconstruction targets. Although data aggregation offers a potential solution, existing neural topic models often overlook it due to time complexity, poor aggregation quality, and difficulty in inferring topic proportions for individual documents. In this paper, we propose a novel model, GloCOM (Global Clustering COntexts for Topic Models), which addresses these challenges by constructing aggregated global clustering contexts for short documents, leveraging text embeddings from pre-trained language models. GloCOM can infer both global topic distributions for clustering contexts and local distributions for individual short texts. Additionally, the model incorporates these global contexts to augment the reconstruction loss, effectively handling the label sparsity issue. Extensive experiments on short text datasets show that our approach outperforms other state-of-the-art models in both topic quality and document representations.
NeuroMax: Enhancing Neural Topic Modeling via Maximizing Mutual Information and Group Topic Regularization
Sep 29, 2024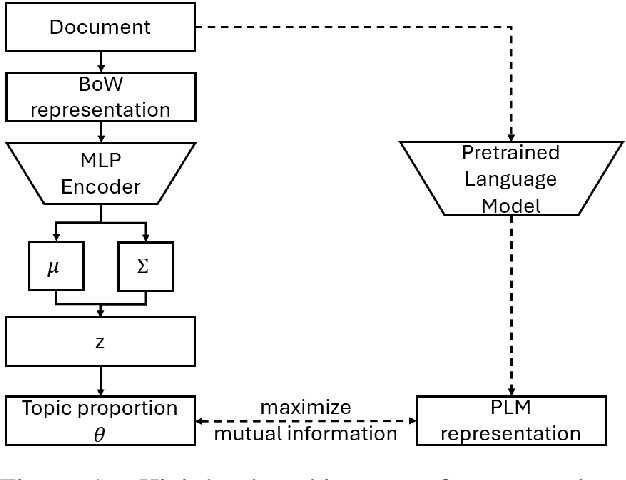
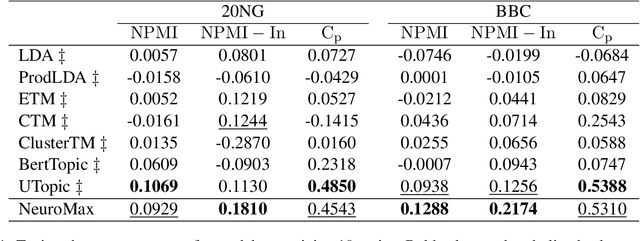
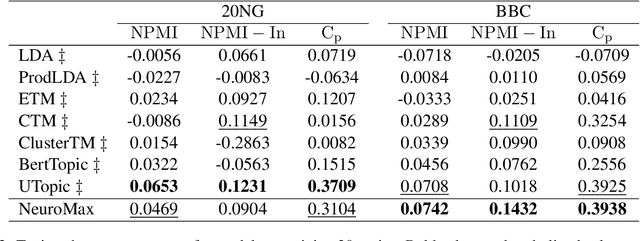
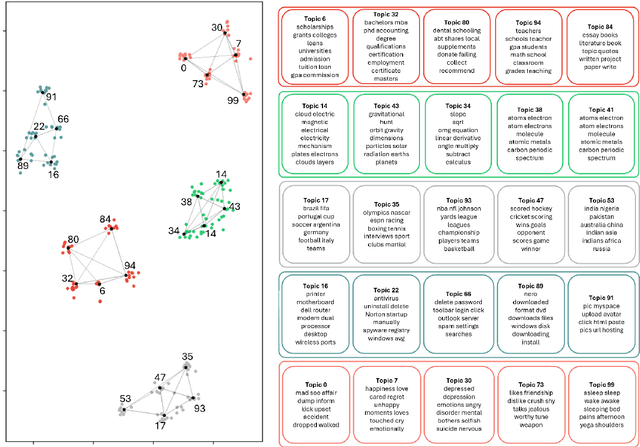
Recent advances in neural topic models have concentrated on two primary directions: the integration of the inference network (encoder) with a pre-trained language model (PLM) and the modeling of the relationship between words and topics in the generative model (decoder). However, the use of large PLMs significantly increases inference costs, making them less practical for situations requiring low inference times. Furthermore, it is crucial to simultaneously model the relationships between topics and words as well as the interrelationships among topics themselves. In this work, we propose a novel framework called NeuroMax (Neural Topic Model with Maximizing Mutual Information with Pretrained Language Model and Group Topic Regularization) to address these challenges. NeuroMax maximizes the mutual information between the topic representation obtained from the encoder in neural topic models and the representation derived from the PLM. Additionally, NeuroMax employs optimal transport to learn the relationships between topics by analyzing how information is transported among them. Experimental results indicate that NeuroMax reduces inference time, generates more coherent topics and topic groups, and produces more representative document embeddings, thereby enhancing performance on downstream tasks.
Memorization-Dilation: Modeling Neural Collapse Under Noise
Jun 11, 2022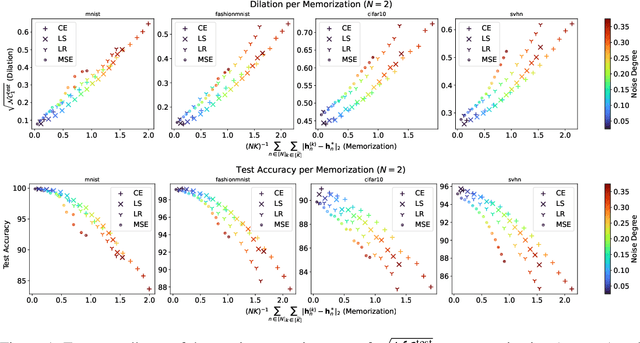

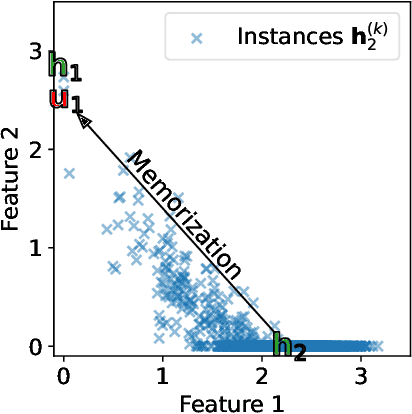
The notion of neural collapse refers to several emergent phenomena that have been empirically observed across various canonical classification problems. During the terminal phase of training a deep neural network, the feature embedding of all examples of the same class tend to collapse to a single representation, and the features of different classes tend to separate as much as possible. Neural collapse is often studied through a simplified model, called the unconstrained feature representation, in which the model is assumed to have "infinite expressivity" and can map each data point to any arbitrary representation. In this work, we propose a more realistic variant of the unconstrained feature representation that takes the limited expressivity of the network into account. Empirical evidence suggests that the memorization of noisy data points leads to a degradation (dilation) of the neural collapse. Using a model of the memorization-dilation (M-D) phenomenon, we show one mechanism by which different losses lead to different performances of the trained network on noisy data. Our proofs reveal why label smoothing, a modification of cross-entropy empirically observed to produce a regularization effect, leads to improved generalization in classification tasks.
CentSmoothie: Central-Smoothing Hypergraph Neural Networks for Predicting Drug-Drug Interactions
Dec 15, 2021

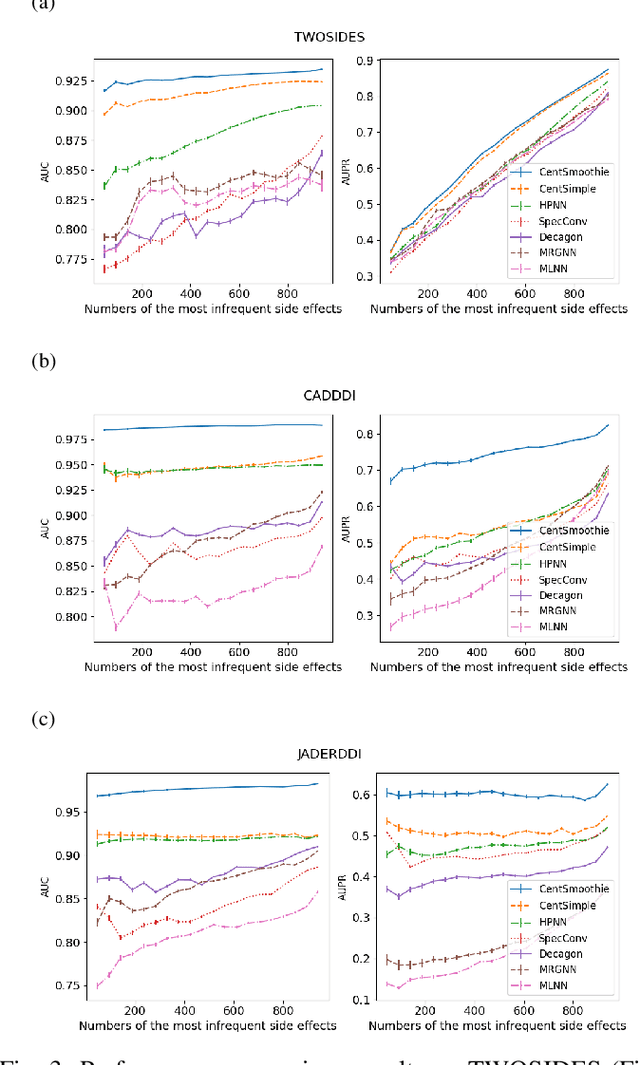
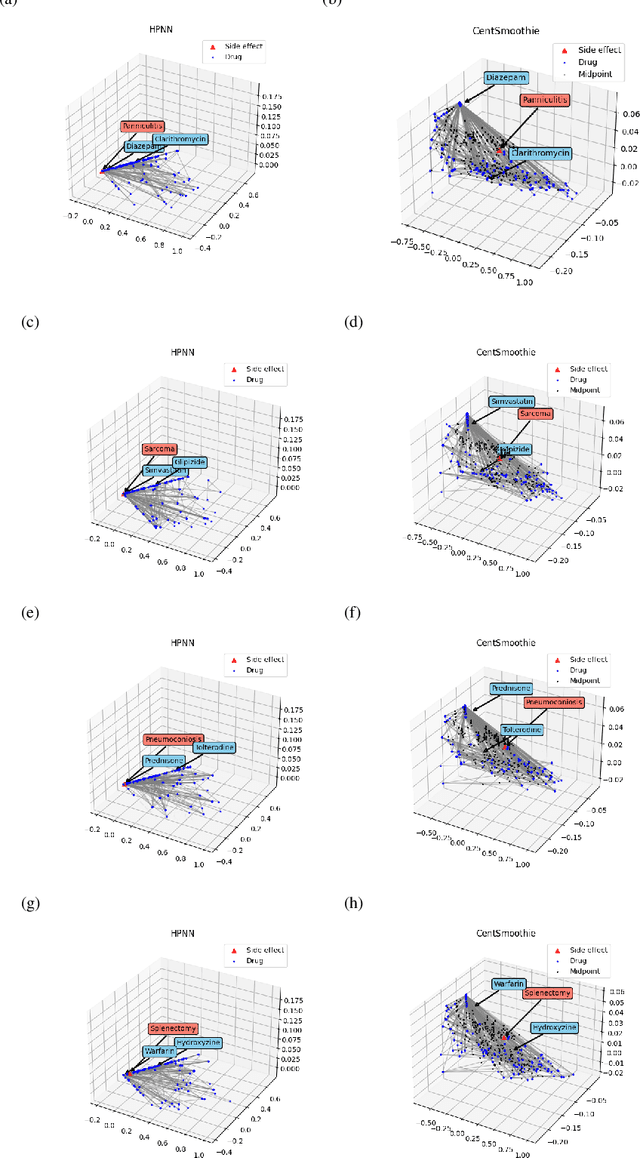
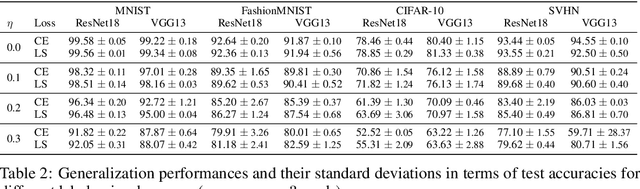
Predicting drug-drug interactions (DDI) is the problem of predicting side effects (unwanted outcomes) of a pair of drugs using drug information and known side effects of many pairs. This problem can be formulated as predicting labels (i.e. side effects) for each pair of nodes in a DDI graph, of which nodes are drugs and edges are interacting drugs with known labels. State-of-the-art methods for this problem are graph neural networks (GNNs), which leverage neighborhood information in the graph to learn node representations. For DDI, however, there are many labels with complicated relationships due to the nature of side effects. Usual GNNs often fix labels as one-hot vectors that do not reflect label relationships and potentially do not obtain the highest performance in the difficult cases of infrequent labels. In this paper, we formulate DDI as a hypergraph where each hyperedge is a triple: two nodes for drugs and one node for a label. We then present CentSmoothie, a hypergraph neural network that learns representations of nodes and labels altogether with a novel central-smoothing formulation. We empirically demonstrate the performance advantages of CentSmoothie in simulations as well as real datasets.