 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariance Everywhere All At Once: A Recipe for Graph Foundation Models
Jun 17, 2025Graph machine learning architectures are typically tailored to specific tasks on specific datasets, which hinders their broader applicability. This has led to a new quest in graph machine learning: how to build graph foundation models capable of generalizing across arbitrary graphs and features? In this work, we present a recipe for designing graph foundation models for node-level tasks from first principles. The key ingredient underpinning our study is a systematic investigation of the symmetries that a graph foundation model must respect. In a nutshell, we argue that label permutation-equivariance alongside feature permutation-invariance are necessary in addition to the common node permutation-equivariance on each local neighborhood of the graph. To this end, we first characterize the space of linear transformations that are equivariant to permutations of nodes and labels, and invariant to permutations of features. We then prove that the resulting network is a universal approximator on multisets that respect the aforementioned symmetries. Our recipe uses such layers on the multiset of features induced by the local neighborhood of the graph to obtain a class of graph foundation models for node property prediction. We validate our approach through extensive experiments on 29 real-world node classification datasets, demonstrating both strong zero-shot empirical performance and consistent improvement as the number of training graphs increases.
Efficient Learning on Large Graphs using a Densifying Regularity Lemma
Apr 25, 2025Learning on large graphs presents significant challenges, with traditional Message Passing Neural Networks suffering from computational and memory costs scaling linearly with the number of edges. We introduce the Intersecting Block Graph (IBG), a low-rank factorization of large directed graphs based on combinations of intersecting bipartite components, each consisting of a pair of communities, for source and target nodes. By giving less weight to non-edges, we show how to efficiently approximate any graph, sparse or dense, by a dense IBG. Specifically, we prove a constructive version of the weak regularity lemma, showing that for any chosen accuracy, every graph, regardless of its size or sparsity, can be approximated by a dense IBG whose rank depends only on the accuracy. This dependence of the rank solely on the accuracy, and not on the sparsity level, is in contrast to previous forms of the weak regularity lemma. We present a graph neural network architecture operating on the IBG representation of the graph and demonstrating competitive performance on node classification, spatio-temporal graph analysis, and knowledge graph completion, while having memory and computational complexity linear in the number of nodes rather than edges.
Survey on Generalization Theory for Graph Neural Networks
Mar 19, 2025Message-passing graph neural networks (MPNNs) have emerged as the leading approach for machine learning on graphs, attracting significant attention in recent years. While a large set of works explored the expressivity of MPNNs, i.e., their ability to separate graphs and approximate functions over them, comparatively less attention has been directed toward investigating their generalization abilities, i.e., making meaningful predictions beyond the training data. Here, we systematically review the existing literature on the generalization abilities of MPNNs. We analyze the strengths and limitations of various studies in these domains, providing insights into their methodologies and findings. Furthermore, we identify potential avenues for future research, aiming to deepen our understanding of the generalization abilities of MPNNs.
Covered Forest: Fine-grained generalization analysis of graph neural networks
Dec 10, 2024The expressive power of message-passing graph neural networks (MPNNs) is reasonably well understood, primarily through combinatorial techniques from graph isomorphism testing. However, MPNNs' generalization abilities -- making meaningful predictions beyond the training set -- remain less explored. Current generalization analyses often overlook graph structure, limit the focus to specific aggregation functions, and assume the impractical, hard-to-optimize $0$-$1$ loss function. Here, we extend recent advances in graph similarity theory to assess the influence of graph structure, aggregation, and loss functions on MPNNs' generalization abilities. Our empirical study supports our theoretical insights, improving our understanding of MPNNs' generalization properties.
Generalization, Expressivity, and Universality of Graph Neural Networks on Attributed Graphs
Nov 08, 2024We analyze the universality and generalization of graph neural networks (GNNs) on attributed graphs, i.e., with node attributes. To this end, we propose pseudometrics over the space of all attributed graphs that describe the fine-grained expressivity of GNNs. Namely, GNNs are both Lipschitz continuous with respect to our pseudometrics and can separate attributed graphs that are distant in the metric. Moreover, we prove that the space of all attributed graphs is relatively compact with respect to our metrics. Based on these properties, we prove a universal approximation theorem for GNNs and generalization bounds for GNNs on any data distribution of attributed graphs. The proposed metrics compute the similarity between the structures of attributed graphs via a hierarchical optimal transport between computation trees. Our work extends and unites previous approaches which either derived theory only for graphs with no attributes, derived compact metrics under which GNNs are continuous but without separation power, or derived metrics under which GNNs are continuous and separate points but the space of graphs is not relatively compact, which prevents universal approximation and generalization analysis.
PieClam: A Universal Graph Autoencoder Based on Overlapping Inclusive and Exclusive Communities
Sep 18, 2024We propose PieClam (Prior Inclusive Exclusive Cluster Affiliation Model): a probabilistic graph model for representing any graph as overlapping generalized communities. Our method can be interpreted as a graph autoencoder: nodes are embedded into a code space by an algorithm that maximizes the log-likelihood of the decoded graph, given the input graph. PieClam is a community affiliation model that extends well-known methods like BigClam in two main manners. First, instead of the decoder being defined via pairwise interactions between the nodes in the code space, we also incorporate a learned prior on the distribution of nodes in the code space, turning our method into a graph generative model. Secondly, we generalize the notion of communities by allowing not only sets of nodes with strong connectivity, which we call inclusive communities, but also sets of nodes with strong disconnection, which we call exclusive communities. To model both types of communities, we propose a new type of decoder based the Lorentz inner product, which we prove to be much more expressive than standard decoders based on standard inner products or norm distances. By introducing a new graph similarity measure, that we call the log cut distance, we show that PieClam is a universal autoencoder, able to uniformly approximately reconstruct any graph. Our method is shown to obtain competitive performance in graph anomaly detection benchmarks.
Equivariant Machine Learning on Graphs with Nonlinear Spectral Filters
Jun 03, 2024



Equivariant machine learning is an approach for designing deep learning models that respect the symmetries of the problem, with the aim of reducing model complexity and improving generalization. In this paper, we focus on an extension of shift equivariance, which is the basis of convolution networks on images, to general graphs. Unlike images, graphs do not have a natural notion of domain translation. Therefore, we consider the graph functional shifts as the symmetry group: the unitary operators that commute with the graph shift operator. Notably, such symmetries operate in the signal space rather than directly in the spatial space. We remark that each linear filter layer of a standard spectral graph neural network (GNN) commutes with graph functional shifts, but the activation function breaks this symmetry. Instead, we propose nonlinear spectral filters (NLSFs) that are fully equivariant to graph functional shifts and show that they have universal approximation properties. The proposed NLSFs are based on a new form of spectral domain that is transferable between graphs. We demonstrate the superior performance of NLSFs over existing spectral GNNs in node and graph classification benchmarks.
Learning on Large Graphs using Intersecting Communities
May 31, 2024



Message Passing Neural Networks (MPNNs) are a staple of graph machine learning. MPNNs iteratively update each node's representation in an input graph by aggregating messages from the node's neighbors, which necessitates a memory complexity of the order of the number of graph edges. This complexity might quickly become prohibitive for large graphs provided they are not very sparse. In this paper, we propose a novel approach to alleviate this problem by approximating the input graph as an intersecting community graph (ICG) -- a combination of intersecting cliques. The key insight is that the number of communities required to approximate a graph does not depend on the graph size. We develop a new constructive version of the Weak Graph Regularity Lemma to efficiently construct an approximating ICG for any input graph. We then devise an efficient graph learning algorithm operating directly on ICG in linear memory and time with respect to the number of nodes (rather than edges). This offers a new and fundamentally different pipeline for learning on very large non-sparse graphs, whose applicability is demonstrated empirically on node classification tasks and spatio-temporal data processing.
Generalization Bounds for Message Passing Networks on Mixture of Graphons
Apr 04, 2024We study the generalization capabilities of Message Passing Neural Networks (MPNNs), a prevalent class of Graph Neural Networks (GNN). We derive generalization bounds specifically for MPNNs with normalized sum aggregation and mean aggregation. Our analysis is based on a data generation model incorporating a finite set of template graphons. Each graph within this framework is generated by sampling from one of the graphons with a certain degree of perturbation. In particular, we extend previous MPNN generalization results to a more realistic setting, which includes the following modifications: 1) we analyze simple random graphs with Bernoulli-distributed edges instead of weighted graphs; 2) we sample both graphs and graph signals from perturbed graphons instead of clean graphons; and 3) we analyze sparse graphs instead of dense graphs. In this more realistic and challenging scenario, we provide a generalization bound that decreases as the average number of nodes in the graphs increases. Our results imply that MPNNs with higher complexity than the size of the training set can still generalize effectively, as long as the graphs are sufficiently large.
Future Directions in Foundations of Graph Machine Learning
Feb 03, 2024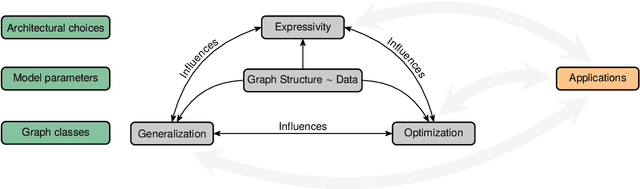
Machine learning on graphs, especially using graph neural networks (GNNs), has seen a surge in interest due to the wide availability of graph data across a broad spectrum of disciplines, from life to social and engineering sciences. Despite their practical success, our theoretical understanding of the properties of GNNs remains highly incomplete. Recent theoretical advancements primarily focus on elucidating the coarse-grained expressive power of GNNs, predominantly employing combinatorial techniques. However, these studies do not perfectly align with practice, particularly in understanding the generalization behavior of GNNs when trained with stochastic first-order optimization techniques. In this position paper, we argue that the graph machine learning community needs to shift its attention to developing a more balanced theory of graph machine learning, focusing on a more thorough understanding of the interplay of expressive power, generalization, and optimization.