 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Approximate Uniform Facility Location via Graph Neural Networks
Feb 13, 2026There has been a growing interest in using neural networks, especially message-passing neural networks (MPNNs), to solve hard combinatorial optimization problems heuristically. However, existing learning-based approaches for hard combinatorial optimization tasks often rely on supervised training data, reinforcement learning, or gradient estimators, leading to significant computational overhead, unstable training, or a lack of provable performance guarantees. In contrast, classical approximation algorithms offer such performance guarantees under worst-case inputs but are non-differentiable and unable to adaptively exploit structural regularities in natural input distributions. We address this dichotomy with the fundamental example of Uniform Facility Location (UniFL), a variant of the combinatorial facility location problem with applications in clustering, data summarization, logistics, and supply chain design. We develop a fully differentiable MPNN model that embeds approximation-algorithmic principles while avoiding the need for solver supervision or discrete relaxations. Our approach admits provable approximation and size generalization guarantees to much larger instances than seen during training. Empirically, we show that our approach outperforms standard non-learned approximation algorithms in terms of solution quality, closing the gap with computationally intensive integer linear programming approaches. Overall, this work provides a step toward bridging learning-based methods and approximation algorithms for discrete optimization.
Which Algorithms Can Graph Neural Networks Learn?
Feb 13, 2026In recent years, there has been growing interest in understanding neural architectures' ability to learn to execute discrete algorithms, a line of work often referred to as neural algorithmic reasoning. The goal is to integrate algorithmic reasoning capabilities into larger neural pipelines. Many such architectures are based on (message-passing) graph neural networks (MPNNs), owing to their permutation equivariance and ability to deal with sparsity and variable-sized inputs. However, existing work is either largely empirical and lacks formal guarantees or it focuses solely on expressivity, leaving open the question of when and how such architectures generalize beyond a finite training set. In this work, we propose a general theoretical framework that characterizes the sufficient conditions under which MPNNs can learn an algorithm from a training set of small instances and provably approximate its behavior on inputs of arbitrary size. Our framework applies to a broad class of algorithms, including single-source shortest paths, minimum spanning trees, and general dynamic programming problems, such as the $0$-$1$ knapsack problem. In addition, we establish impossibility results for a wide range of algorithmic tasks, showing that standard MPNNs cannot learn them, and we derive more expressive MPNN-like architectures that overcome these limitations. Finally, we refine our analysis for the Bellman-Ford algorithm, yielding a substantially smaller required training set and significantly extending the recent work of Nerem et al. [2025] by allowing for a differentiable regularization loss. Empirical results largely support our theoretical findings.
Position: Message-passing and spectral GNNs are two sides of the same coin
Feb 10, 2026Graph neural networks (GNNs) are commonly divided into message-passing neural networks (MPNNs) and spectral graph neural networks, reflecting two largely separate research traditions in machine learning and signal processing. This paper argues that this divide is mostly artificial, hindering progress in the field. We propose a viewpoint in which both MPNNs and spectral GNNs are understood as different parametrizations of permutation-equivariant operators acting on graph signals. From this perspective, many popular architectures are equivalent in expressive power, while genuine gaps arise only in specific regimes. We further argue that MPNNs and spectral GNNs offer complementary strengths. That is, MPNNs provide a natural language for discrete structure and expressivity analysis using tools from logic and graph isomorphism research, while the spectral perspective provides principled tools for understanding smoothing, bottlenecks, stability, and community structure. Overall, we posit that progress in graph learning will be accelerated by clearly understanding the key similarities and differences between these two types of GNNs, and by working towards unifying these perspectives within a common theoretical and conceptual framework rather than treating them as competing paradigms.
GraIP: A Benchmarking Framework For Neural Graph Inverse Problems
Jan 26, 2026A wide range of graph learning tasks, such as structure discovery, temporal graph analysis, and combinatorial optimization, focus on inferring graph structures from data, rather than making predictions on given graphs. However, the respective methods to solve such problems are often developed in an isolated, task-specific manner and thus lack a unifying theoretical foundation. Here, we provide a stepping stone towards the formation of such a foundation and further development by introducing the Neural Graph Inverse Problem (GraIP) conceptual framework, which formalizes and reframes a broad class of graph learning tasks as inverse problems. Unlike discriminative approaches that directly predict target variables from given graph inputs, the GraIP paradigm addresses inverse problems, i.e., it relies on observational data and aims to recover the underlying graph structure by reversing the forward process, such as message passing or network dynamics, that produced the observed outputs. We demonstrate the versatility of GraIP across various graph learning tasks, including rewiring, causal discovery, and neural relational inference. We also propose benchmark datasets and metrics for each GraIP domain considered, and characterize and empirically evaluate existing baseline methods used to solve them. Overall, our unifying perspective bridges seemingly disparate applications and provides a principled approach to structural learning in constrained and combinatorial settings while encouraging cross-pollination of existing methods across graph inverse problems.
Principled Latent Diffusion for Graphs via Laplacian Autoencoders
Jan 20, 2026Graph diffusion models achieve state-of-the-art performance in graph generation but suffer from quadratic complexity in the number of nodes -- and much of their capacity is wasted modeling the absence of edges in sparse graphs. Inspired by latent diffusion in other modalities, a natural idea is to compress graphs into a low-dimensional latent space and perform diffusion there. However, unlike images or text, graph generation requires nearly lossless reconstruction, as even a single error in decoding an adjacency matrix can render the entire sample invalid. This challenge has remained largely unaddressed. We propose LG-Flow, a latent graph diffusion framework that directly overcomes these obstacles. A permutation-equivariant autoencoder maps each node into a fixed-dimensional embedding from which the full adjacency is provably recoverable, enabling near-lossless reconstruction for both undirected graphs and DAGs. The dimensionality of this latent representation scales linearly with the number of nodes, eliminating the quadratic bottleneck and making it feasible to train larger and more expressive models. In this latent space, we train a Diffusion Transformer with flow matching, enabling efficient and expressive graph generation. Our approach achieves competitive results against state-of-the-art graph diffusion models, while achieving up to $1000\times$ speed-up.
Generalizable Insights for Graph Transformers in Theory and Practice
Nov 11, 2025Graph Transformers (GTs) have shown strong empirical performance, yet current architectures vary widely in their use of attention mechanisms, positional embeddings (PEs), and expressivity. Existing expressivity results are often tied to specific design choices and lack comprehensive empirical validation on large-scale data. This leaves a gap between theory and practice, preventing generalizable insights that exceed particular application domains. Here, we propose the Generalized-Distance Transformer (GDT), a GT architecture using standard attention that incorporates many advancements for GTs from recent years, and develop a fine-grained understanding of the GDT's representation power in terms of attention and PEs. Through extensive experiments, we identify design choices that consistently perform well across various applications, tasks, and model scales, demonstrating strong performance in a few-shot transfer setting without fine-tuning. Our evaluation covers over eight million graphs with roughly 270M tokens across diverse domains, including image-based object detection, molecular property prediction, code summarization, and out-of-distribution algorithmic reasoning. We distill our theoretical and practical findings into several generalizable insights about effective GT design, training, and inference.
Understanding Generalization in Node and Link Prediction
Jul 01, 2025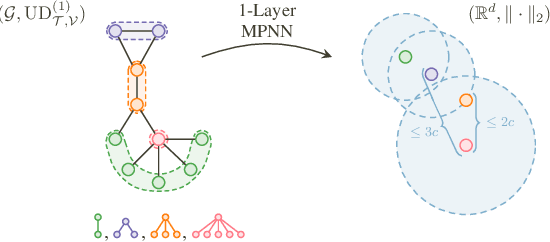



Using message-passing graph neural networks (MPNNs) for node and link prediction is crucial in various scientific and industrial domains, which has led to the development of diverse MPNN architectures. Besides working well in practical settings, their ability to generalize beyond the training set remains poorly understood. While some studies have explored MPNNs' generalization in graph-level prediction tasks, much less attention has been given to node- and link-level predictions. Existing works often rely on unrealistic i.i.d.\@ assumptions, overlooking possible correlations between nodes or links, and assuming fixed aggregation and impractical loss functions while neglecting the influence of graph structure. In this work, we introduce a unified framework to analyze the generalization properties of MPNNs in inductive and transductive node and link prediction settings, incorporating diverse architectural parameters and loss functions and quantifying the influence of graph structure. Additionally, our proposed generalization framework can be applied beyond graphs to any classification task under the inductive or transductive setting. Our empirical study supports our theoretical insights, deepening our understanding of MPNNs' generalization capabilities in these tasks.
Survey on Generalization Theory for Graph Neural Networks
Mar 19, 2025

Message-passing graph neural networks (MPNNs) have emerged as the leading approach for machine learning on graphs, attracting significant attention in recent years. While a large set of works explored the expressivity of MPNNs, i.e., their ability to separate graphs and approximate functions over them, comparatively less attention has been directed toward investigating their generalization abilities, i.e., making meaningful predictions beyond the training data. Here, we systematically review the existing literature on the generalization abilities of MPNNs. We analyze the strengths and limitations of various studies in these domains, providing insights into their methodologies and findings. Furthermore, we identify potential avenues for future research, aiming to deepen our understanding of the generalization abilities of MPNNs.
Position: Graph Learning Will Lose Relevance Due To Poor Benchmarks
Feb 20, 2025
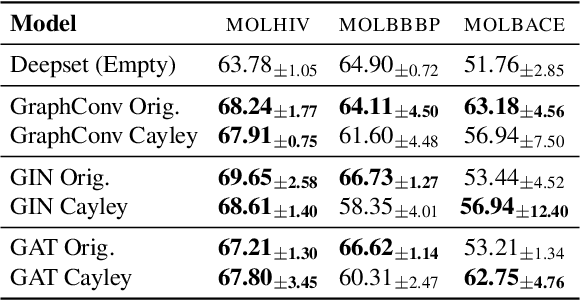
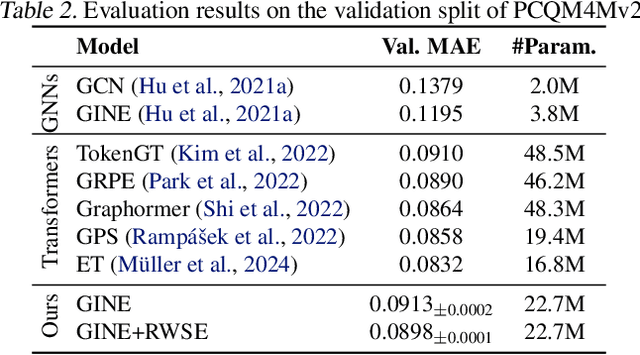
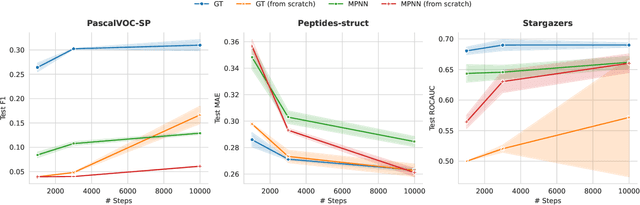
While machine learning on graphs has demonstrated promise in drug design and molecular property prediction, significant benchmarking challenges hinder its further progress and relevance. Current benchmarking practices often lack focus on transformative, real-world applications, favoring narrow domains like two-dimensional molecular graphs over broader, impactful areas such as combinatorial optimization, relational databases, or chip design. Additionally, many benchmark datasets poorly represent the underlying data, leading to inadequate abstractions and misaligned use cases. Fragmented evaluations and an excessive focus on accuracy further exacerbate these issues, incentivizing overfitting rather than fostering generalizable insights. These limitations have prevented the development of truly useful graph foundation models. This position paper calls for a paradigm shift toward more meaningful benchmarks, rigorous evaluation protocols, and stronger collaboration with domain experts to drive impactful and reliable advances in graph learning research, unlocking the potential of graph learning.
Towards graph neural networks for provably solving convex optimization problems
Feb 04, 2025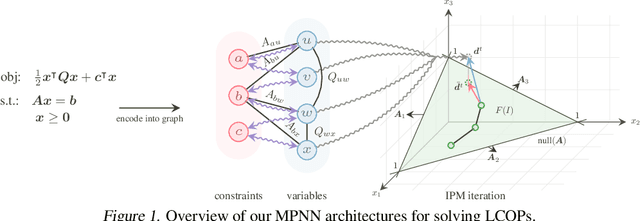
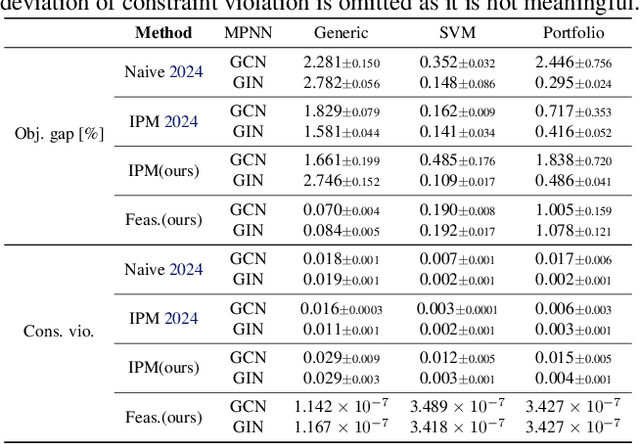
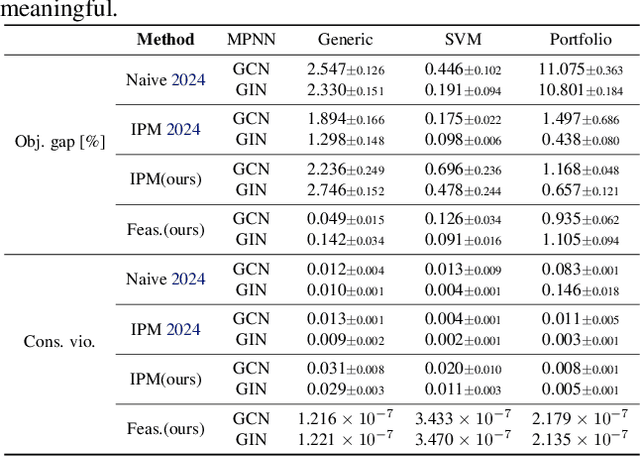
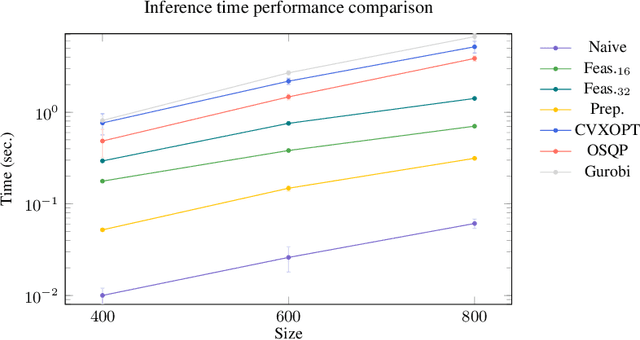
Recently, message-passing graph neural networks (MPNNs) have shown potential for solving combinatorial and continuous optimization problems due to their ability to capture variable-constraint interactions. While existing approaches leverage MPNNs to approximate solutions or warm-start traditional solvers, they often lack guarantees for feasibility, particularly in convex optimization settings. Here, we propose an iterative MPNN framework to solve convex optimization problems with provable feasibility guarantees. First, we demonstrate that MPNNs can provably simulate standard interior-point methods for solving quadratic problems with linear constraints, covering relevant problems such as SVMs. Secondly, to ensure feasibility, we introduce a variant that starts from a feasible point and iteratively restricts the search within the feasible region. Experimental results show that our approach outperforms existing neural baselines in solution quality and feasibility, generalizes well to unseen problem sizes, and, in some cases, achieves faster solution times than state-of-the-art solvers such as Gurobi.