 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraIP: A Benchmarking Framework For Neural Graph Inverse Problems
Jan 26, 2026A wide range of graph learning tasks, such as structure discovery, temporal graph analysis, and combinatorial optimization, focus on inferring graph structures from data, rather than making predictions on given graphs. However, the respective methods to solve such problems are often developed in an isolated, task-specific manner and thus lack a unifying theoretical foundation. Here, we provide a stepping stone towards the formation of such a foundation and further development by introducing the Neural Graph Inverse Problem (GraIP) conceptual framework, which formalizes and reframes a broad class of graph learning tasks as inverse problems. Unlike discriminative approaches that directly predict target variables from given graph inputs, the GraIP paradigm addresses inverse problems, i.e., it relies on observational data and aims to recover the underlying graph structure by reversing the forward process, such as message passing or network dynamics, that produced the observed outputs. We demonstrate the versatility of GraIP across various graph learning tasks, including rewiring, causal discovery, and neural relational inference. We also propose benchmark datasets and metrics for each GraIP domain considered, and characterize and empirically evaluate existing baseline methods used to solve them. Overall, our unifying perspective bridges seemingly disparate applications and provides a principled approach to structural learning in constrained and combinatorial settings while encouraging cross-pollination of existing methods across graph inverse problems.
Learning the Neighborhood: Contrast-Free Multimodal Self-Supervised Molecular Graph Pretraining
Sep 26, 2025



High-quality molecular representations are essential for property prediction and molecular design, yet large labeled datasets remain scarce. While self-supervised pretraining on molecular graphs has shown promise, many existing approaches either depend on hand-crafted augmentations or complex generative objectives, and often rely solely on 2D topology, leaving valuable 3D structural information underutilized. To address this gap, we introduce C-FREE (Contrast-Free Representation learning on Ego-nets), a simple framework that integrates 2D graphs with ensembles of 3D conformers. C-FREE learns molecular representations by predicting subgraph embeddings from their complementary neighborhoods in the latent space, using fixed-radius ego-nets as modeling units across different conformers. This design allows us to integrate both geometric and topological information within a hybrid Graph Neural Network (GNN)-Transformer backbone, without negatives, positional encodings, or expensive pre-processing. Pretraining on the GEOM dataset, which provides rich 3D conformational diversity, C-FREE achieves state-of-the-art results on MoleculeNet, surpassing contrastive, generative, and other multimodal self-supervised methods. Fine-tuning across datasets with diverse sizes and molecule types further demonstrates that pretraining transfers effectively to new chemical domains, highlighting the importance of 3D-informed molecular representations.
ChronoGraph: A Real-World Graph-Based Multivariate Time Series Dataset
Sep 04, 2025We present ChronoGraph, a graph-structured multivariate time series forecasting dataset built from real-world production microservices. Each node is a service that emits a multivariate stream of system-level performance metrics, capturing CPU, memory, and network usage patterns, while directed edges encode dependencies between services. The primary task is forecasting future values of these signals at the service level. In addition, ChronoGraph provides expert-annotated incident windows as anomaly labels, enabling evaluation of anomaly detection methods and assessment of forecast robustness during operational disruptions. Compared to existing benchmarks from industrial control systems or traffic and air-quality domains, ChronoGraph uniquely combines (i) multivariate time series, (ii) an explicit, machine-readable dependency graph, and (iii) anomaly labels aligned with real incidents. We report baseline results spanning forecasting models, pretrained time-series foundation models, and standard anomaly detectors. ChronoGraph offers a realistic benchmark for studying structure-aware forecasting and incident-aware evaluation in microservice systems.
Learning (Approximately) Equivariant Networks via Constrained Optimization
May 19, 2025Equivariant neural networks are designed to respect symmetries through their architecture, boosting generalization and sample efficiency when those symmetries are present in the data distribution. Real-world data, however, often departs from perfect symmetry because of noise, structural variation, measurement bias, or other symmetry-breaking effects. Strictly equivariant models may struggle to fit the data, while unconstrained models lack a principled way to leverage partial symmetries. Even when the data is fully symmetric, enforcing equivariance can hurt training by limiting the model to a restricted region of the parameter space. Guided by homotopy principles, where an optimization problem is solved by gradually transforming a simpler problem into a complex one, we introduce Adaptive Constrained Equivariance (ACE), a constrained optimization approach that starts with a flexible, non-equivariant model and gradually reduces its deviation from equivariance. This gradual tightening smooths training early on and settles the model at a data-driven equilibrium, balancing between equivariance and non-equivariance. Across multiple architectures and tasks, our method consistently improves performance metrics, sample efficiency, and robustness to input perturbations compared with strictly equivariant models and heuristic equivariance relaxations.
MolMix: A Simple Yet Effective Baseline for Multimodal Molecular Representation Learning
Oct 10, 2024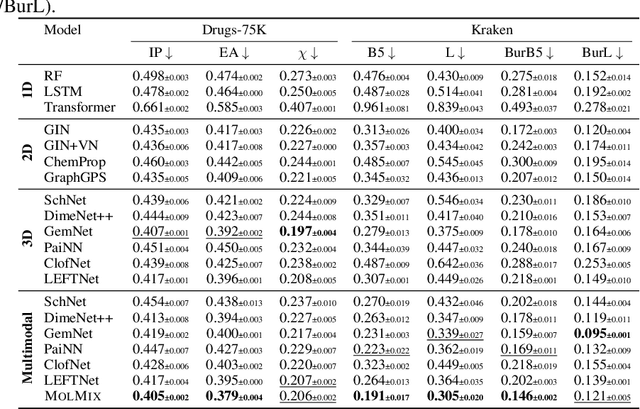
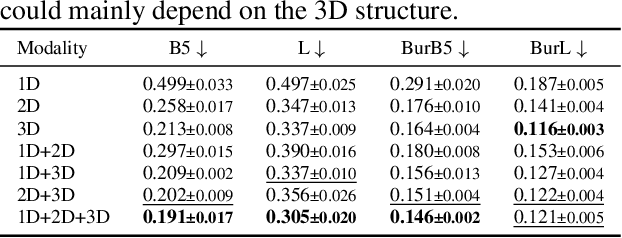
In this work, we propose a simple transformer-based baseline for multimodal molecular representation learning, integrating three distinct modalities: SMILES strings, 2D graph representations, and 3D conformers of molecules. A key aspect of our approach is the aggregation of 3D conformers, allowing the model to account for the fact that molecules can adopt multiple conformations-an important factor for accurate molecular representation. The tokens for each modality are extracted using modality-specific encoders: a transformer for SMILES strings, a message-passing neural network for 2D graphs, and an equivariant neural network for 3D conformers. The flexibility and modularity of this framework enable easy adaptation and replacement of these encoders, making the model highly versatile for different molecular tasks. The extracted tokens are then combined into a unified multimodal sequence, which is processed by a downstream transformer for prediction tasks. To efficiently scale our model for large multimodal datasets, we utilize Flash Attention 2 and bfloat16 precision. Despite its simplicity, our approach achieves state-of-the-art results across multiple datasets, demonstrating its effectiveness as a strong baseline for multimodal molecular representation learning.
Probabilistic Graph Rewiring via Virtual Nodes
May 27, 2024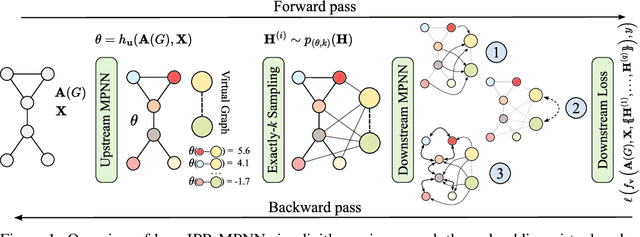
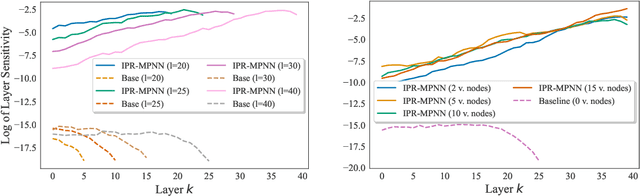

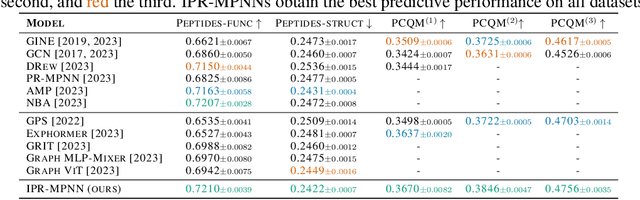
Message-passing graph neural networks (MPNNs) have emerged as a powerful paradigm for graph-based machine learning. Despite their effectiveness, MPNNs face challenges such as under-reaching and over-squashing, where limited receptive fields and structural bottlenecks hinder information flow in the graph. While graph transformers hold promise in addressing these issues, their scalability is limited due to quadratic complexity regarding the number of nodes, rendering them impractical for larger graphs. Here, we propose \emph{implicitly rewired message-passing neural networks} (IPR-MPNNs), a novel approach that integrates \emph{implicit} probabilistic graph rewiring into MPNNs. By introducing a small number of virtual nodes, i.e., adding additional nodes to a given graph and connecting them to existing nodes, in a differentiable, end-to-end manner, IPR-MPNNs enable long-distance message propagation, circumventing quadratic complexity. Theoretically, we demonstrate that IPR-MPNNs surpass the expressiveness of traditional MPNNs. Empirically, we validate our approach by showcasing its ability to mitigate under-reaching and over-squashing effects, achieving state-of-the-art performance across multiple graph datasets. Notably, IPR-MPNNs outperform graph transformers while maintaining significantly faster computational efficiency.
Time Series Anomaly Detection using Diffusion-based Models
Nov 02, 2023



Diffusion models have been recently used for anomaly detection (AD) in images. In this paper we investigate whether they can also be leveraged for AD on multivariate time series (MTS). We test two diffusion-based models and compare them to several strong neural baselines. We also extend the PA%K protocol, by computing a ROCK-AUC metric, which is agnostic to both the detection threshold and the ratio K of correctly detected points. Our models outperform the baselines on synthetic datasets and are competitive on real-world datasets, illustrating the potential of diffusion-based methods for AD in multivariate time series.
Probabilistically Rewired Message-Passing Neural Networks
Oct 15, 2023Message-passing graph neural networks (MPNNs) emerged as powerful tools for processing graph-structured input. However, they operate on a fixed input graph structure, ignoring potential noise and missing information. Furthermore, their local aggregation mechanism can lead to problems such as over-squashing and limited expressive power in capturing relevant graph structures. Existing solutions to these challenges have primarily relied on heuristic methods, often disregarding the underlying data distribution. Hence, devising principled approaches for learning to infer graph structures relevant to the given prediction task remains an open challenge. In this work, leveraging recent progress in exact and differentiable $k$-subset sampling, we devise probabilistically rewired MPNNs (PR-MPNNs), which learn to add relevant edges while omitting less beneficial ones. For the first time, our theoretical analysis explores how PR-MPNNs enhance expressive power, and we identify precise conditions under which they outperform purely randomized approaches. Empirically, we demonstrate that our approach effectively mitigates issues like over-squashing and under-reaching. In addition, on established real-world datasets, our method exhibits competitive or superior predictive performance compared to traditional MPNN models and recent graph transformer architectures.
VeriDark: A Large-Scale Benchmark for Authorship Verification on the Dark Web
Jul 07, 2022
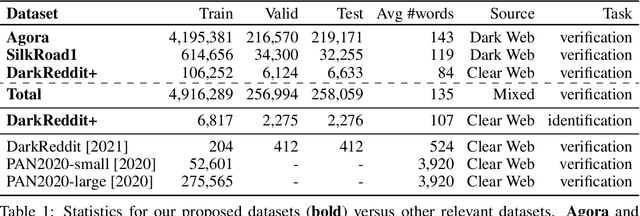
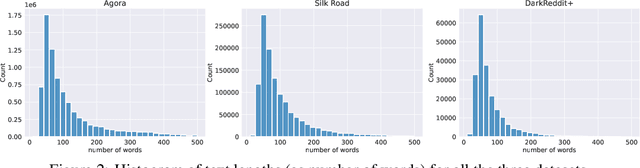
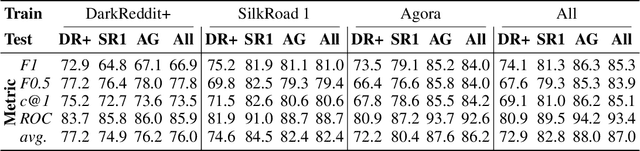
The DarkWeb represents a hotbed for illicit activity, where users communicate on different market forums in order to exchange goods and services. Law enforcement agencies benefit from forensic tools that perform authorship analysis, in order to identify and profile users based on their textual content. However, authorship analysis has been traditionally studied using corpora featuring literary texts such as fragments from novels or fan fiction, which may not be suitable in a cybercrime context. Moreover, the few works that employ authorship analysis tools for cybercrime prevention usually employ ad-hoc experimental setups and datasets. To address these issues, we release VeriDark: a benchmark comprised of three large scale authorship verification datasets and one authorship identification dataset obtained from user activity from either Dark Web related Reddit communities or popular illicit Dark Web market forums. We evaluate competitive NLP baselines on the three datasets and perform an analysis of the predictions to better understand the limitations of such approaches. We make the datasets and baselines publicly available at https://github.com/bit-ml/VeriDark
AnoShift: A Distribution Shift Benchmark for Unsupervised Anomaly Detection
Jun 30, 2022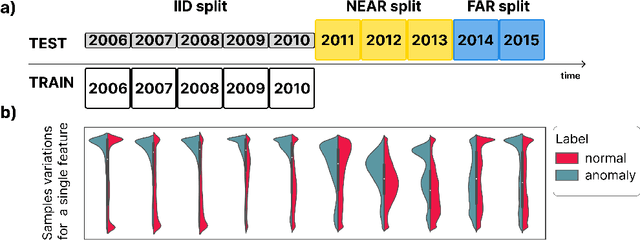

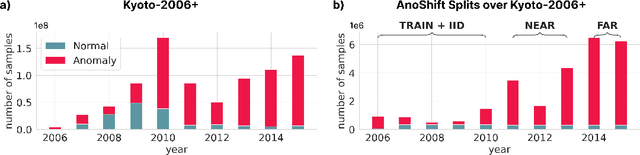
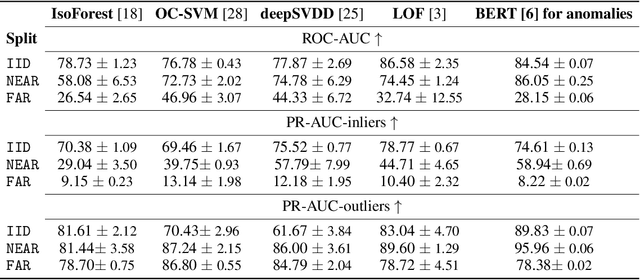
Analyzing the distribution shift of data is a growing research direction in nowadays Machine Learning, leading to emerging new benchmarks that focus on providing a suitable scenario for studying the generalization properties of ML models. The existing benchmarks are focused on supervised learning, and to the best of our knowledge, there is none for unsupervised learning. Therefore, we introduce an unsupervised anomaly detection benchmark with data that shifts over time, built over Kyoto-2006+, a traffic dataset for network intrusion detection. This kind of data meets the premise of shifting the input distribution: it covers a large time span ($10$ years), with naturally occurring changes over time (\eg users modifying their behavior patterns, and software updates). We first highlight the non-stationary nature of the data, using a basic per-feature analysis, t-SNE, and an Optimal Transport approach for measuring the overall distribution distances between years. Next, we propose AnoShift, a protocol splitting the data in IID, NEAR, and FAR testing splits. We validate the performance degradation over time with diverse models (MLM to classical Isolation Forest). Finally, we show that by acknowledging the distribution shift problem and properly addressing it, the performance can be improved compared to the classical IID training (by up to $3\%$, on average). Dataset and code are available at https://github.com/bit-ml/AnoShift/.