 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylist: Style-Driven Feature Ranking for Robust Novelty Detection
Oct 05, 2023Novelty detection aims at finding samples that differ in some form from the distribution of seen samples. But not all changes are created equal. Data can suffer a multitude of distribution shifts, and we might want to detect only some types of relevant changes. Similar to works in out-of-distribution generalization, we propose to use the formalization of separating into semantic or content changes, that are relevant to our task, and style changes, that are irrelevant. Within this formalization, we define the robust novelty detection as the task of finding semantic changes while being robust to style distributional shifts. Leveraging pretrained, large-scale model representations, we introduce Stylist, a novel method that focuses on dropping environment-biased features. First, we compute a per-feature score based on the feature distribution distances between environments. Next, we show that our selection manages to remove features responsible for spurious correlations and improve novelty detection performance. For evaluation, we adapt domain generalization datasets to our task and analyze the methods behaviors. We additionally built a large synthetic dataset where we have control over the spurious correlations degree. We prove that our selection mechanism improves novelty detection algorithms across multiple datasets, containing both stylistic and content shifts.
Environment-biased Feature Ranking for Novelty Detection Robustness
Sep 21, 2023



We tackle the problem of robust novelty detection, where we aim to detect novelties in terms of semantic content while being invariant to changes in other, irrelevant factors. Specifically, we operate in a setup with multiple environments, where we determine the set of features that are associated more with the environments, rather than to the content relevant for the task. Thus, we propose a method that starts with a pretrained embedding and a multi-env setup and manages to rank the features based on their environment-focus. First, we compute a per-feature score based on the feature distribution variance between envs. Next, we show that by dropping the highly scored ones, we manage to remove spurious correlations and improve the overall performance by up to 6%, both in covariance and sub-population shift cases, both for a real and a synthetic benchmark, that we introduce for this task.
Self-supervised Hypergraphs for Learning Multiple World Interpretations
Aug 21, 2023We present a method for learning multiple scene representations given a small labeled set, by exploiting the relationships between such representations in the form of a multi-task hypergraph. We also show how we can use the hypergraph to improve a powerful pretrained VisTransformer model without any additional labeled data. In our hypergraph, each node is an interpretation layer (e.g., depth or segmentation) of the scene. Within each hyperedge, one or several input nodes predict the layer at the output node. Thus, each node could be an input node in some hyperedges and an output node in others. In this way, multiple paths can reach the same node, to form ensembles from which we obtain robust pseudolabels, which allow self-supervised learning in the hypergraph. We test different ensemble models and different types of hyperedges and show superior performance to other multi-task graph models in the field. We also introduce Dronescapes, a large video dataset captured with UAVs in different complex real-world scenes, with multiple representations, suitable for multi-task learning.
Env-Aware Anomaly Detection: Ignore Style Changes, Stay True to Content!
Oct 06, 2022
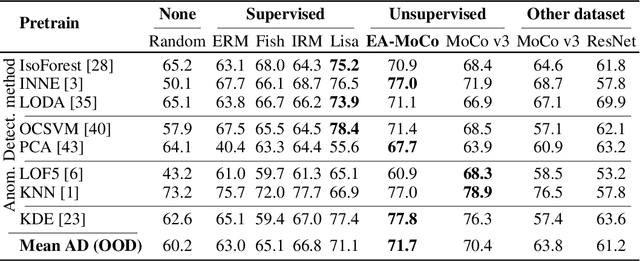
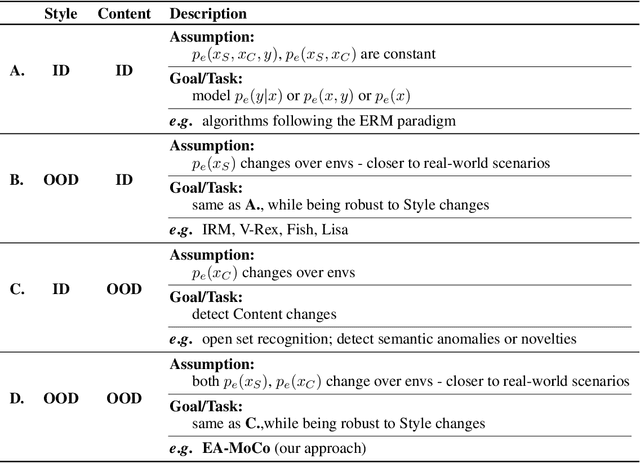
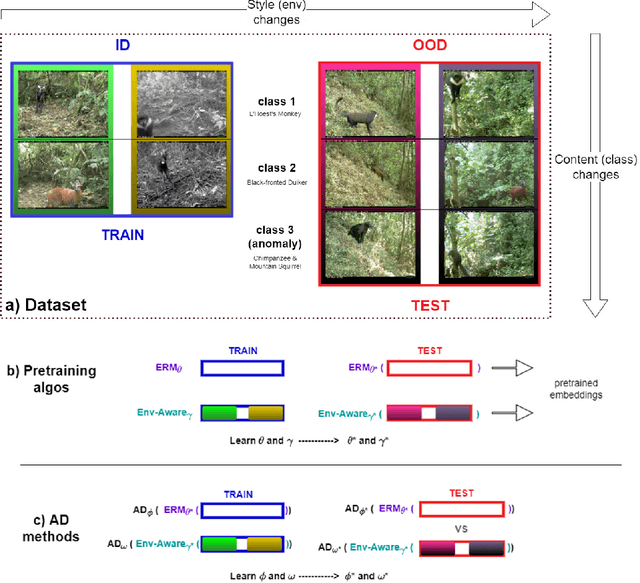
We introduce a formalization and benchmark for the unsupervised anomaly detection task in the distribution-shift scenario. Our work builds upon the iWildCam dataset, and, to the best of our knowledge, we are the first to propose such an approach for visual data. We empirically validate that environment-aware methods perform better in such cases when compared with the basic Empirical Risk Minimization (ERM). We next propose an extension for generating positive samples for contrastive methods that considers the environment labels when training, improving the ERM baseline score by 8.7%.
AnoShift: A Distribution Shift Benchmark for Unsupervised Anomaly Detection
Jun 30, 2022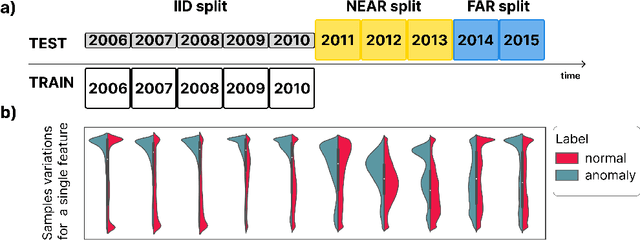

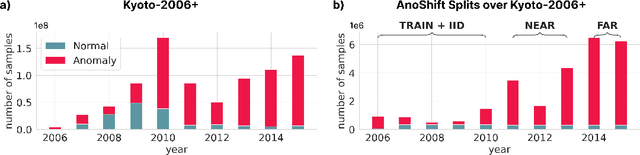
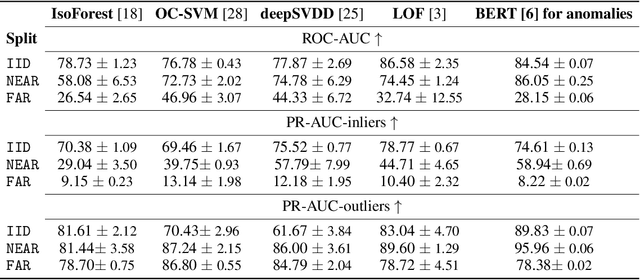
Analyzing the distribution shift of data is a growing research direction in nowadays Machine Learning, leading to emerging new benchmarks that focus on providing a suitable scenario for studying the generalization properties of ML models. The existing benchmarks are focused on supervised learning, and to the best of our knowledge, there is none for unsupervised learning. Therefore, we introduce an unsupervised anomaly detection benchmark with data that shifts over time, built over Kyoto-2006+, a traffic dataset for network intrusion detection. This kind of data meets the premise of shifting the input distribution: it covers a large time span ($10$ years), with naturally occurring changes over time (\eg users modifying their behavior patterns, and software updates). We first highlight the non-stationary nature of the data, using a basic per-feature analysis, t-SNE, and an Optimal Transport approach for measuring the overall distribution distances between years. Next, we propose AnoShift, a protocol splitting the data in IID, NEAR, and FAR testing splits. We validate the performance degradation over time with diverse models (MLM to classical Isolation Forest). Finally, we show that by acknowledging the distribution shift problem and properly addressing it, the performance can be improved compared to the classical IID training (by up to $3\%$, on average). Dataset and code are available at https://github.com/bit-ml/AnoShift/.
Unsupervised Domain Adaptation through Iterative Consensus Shift in a Multi-Task Graph
Mar 26, 2021
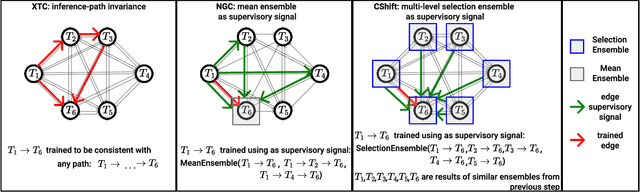
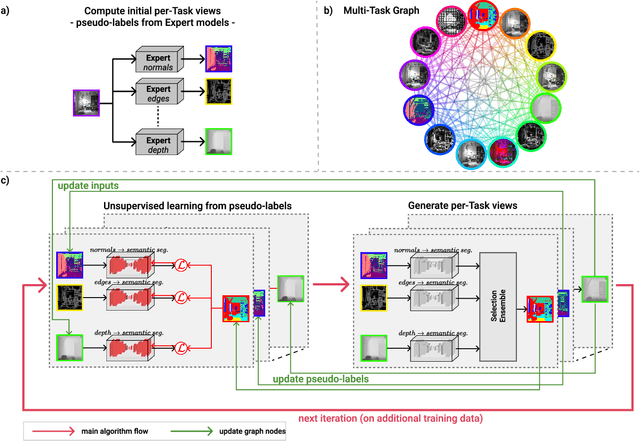
Babies learn with very little supervision by observing the surrounding world. They synchronize the feedback from all their senses and learn to maintain consistency and stability among their internal states. Such observations inspired recent works in multi-task and multi-modal learning, but existing methods rely on expensive manual supervision. In contrast, our proposed multi-task graph, with consensus shift learning, relies only on pseudo-labels provided by expert models. In our graph, every node represents a task, and every edge learns to transform one input node into another. Once initialized, the graph learns by itself on virtually any novel target domain. An adaptive selection mechanism finds consensus among multiple paths reaching a given node and establishes the pseudo-ground truth at that node. Such pseudo-labels, given by ensemble pathways in the graph, are used during the next learning iteration when single edges distill this distributed knowledge. We validate our key contributions experimentally and demonstrate strong performance on the Replica dataset, superior to the very few published methods on multi-task learning with minimal supervision.
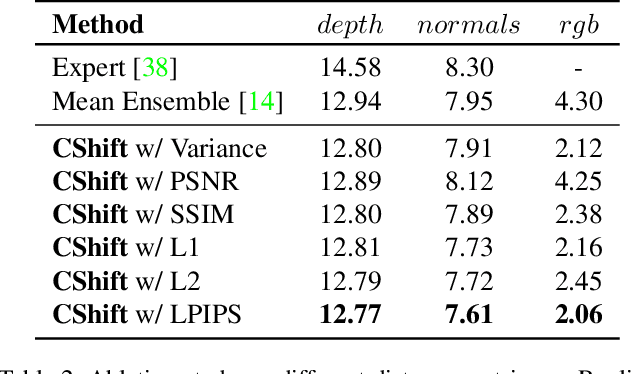
Iterative Knowledge Exchange Between Deep Learning and Space-Time Spectral Clustering for Unsupervised Segmentation in Videos
Dec 13, 2020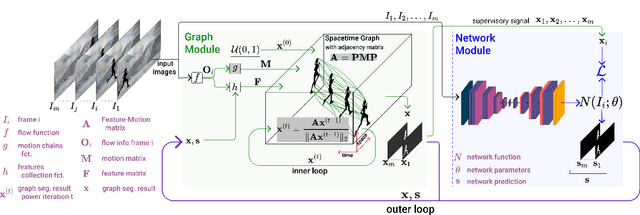
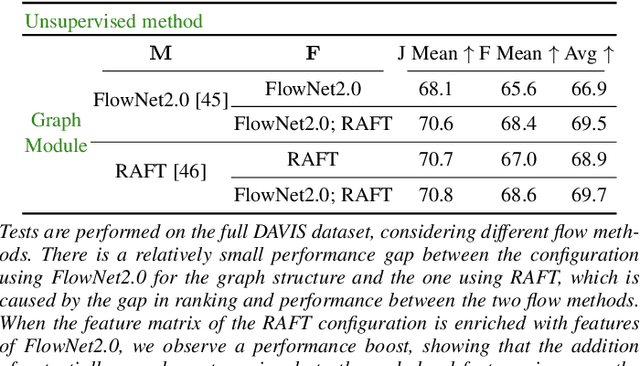
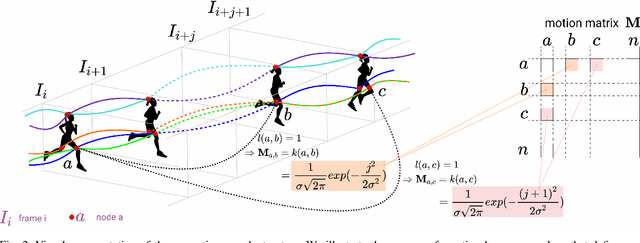
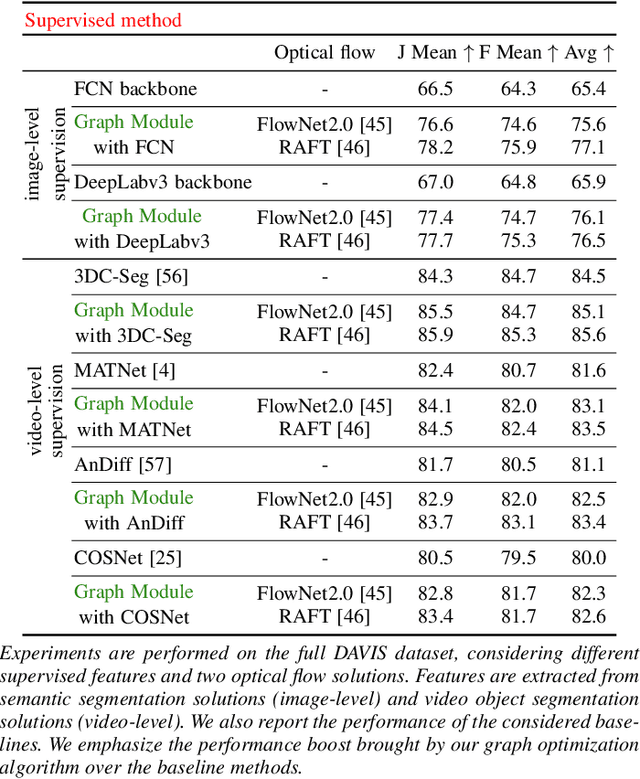
We propose a dual system for unsupervised object segmentation in video, which brings together two modules with complementary properties: a space-time graph that discovers objects in videos and a deep network that learns powerful object features. The system uses an iterative knowledge exchange policy. A novel spectral space-time clustering process on the graph produces unsupervised segmentation masks passed to the network as pseudo-labels. The net learns to segment in single frames what the graph discovers in video and passes back to the graph strong image-level features that improve its node-level features in the next iteration. Knowledge is exchanged for several cycles until convergence. The graph has one node per each video pixel, but the object discovery is fast. It uses a novel power iteration algorithm computing the main space-time cluster as the principal eigenvector of a special Feature-Motion matrix without actually computing the matrix. The thorough experimental analysis validates our theoretical claims and proves the effectiveness of the cyclical knowledge exchange. We also perform experiments on the supervised scenario, incorporating features pretrained with human supervision. We achieve state-of-the-art level on unsupervised and supervised scenarios on four challenging datasets: DAVIS, SegTrack, YouTube-Objects, and DAVSOD.
Spacetime Graph Optimization for Video Object Segmentation
Aug 03, 2019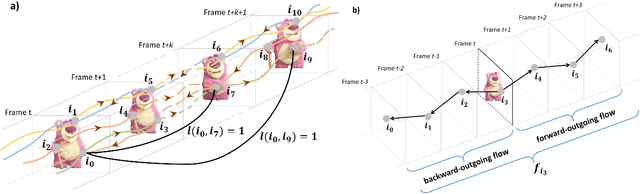

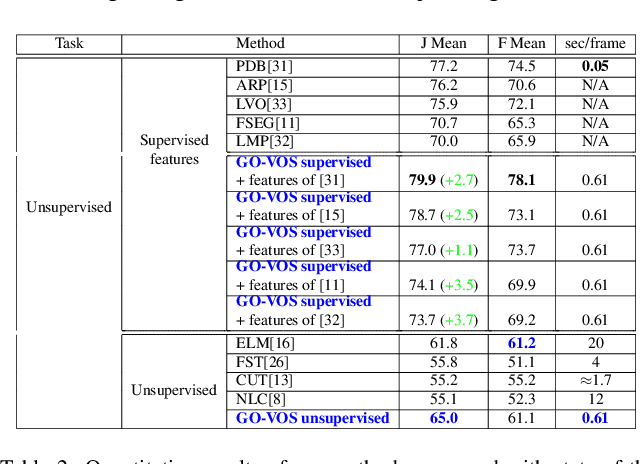
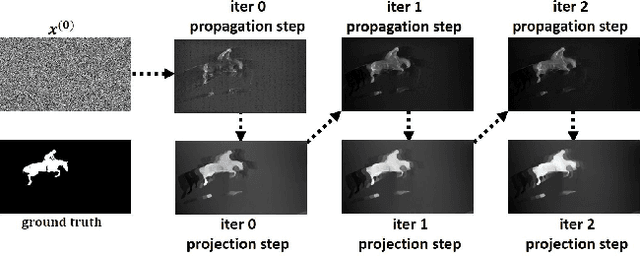
We address the challenging task of foreground object discovery and segmentation in video. We introduce an efficient solution, suitable for both unsupervised and supervised scenarios, based on a spacetime graph representation of the video sequence. We ensure a fine grained representation with one-to-one correspondences between graph nodes and video pixels. We formulate the task as a spectral clustering problem by exploiting the spatio-temporal consistency between the scene elements in terms of motion and appearance. Graph nodes that belong to the main object of interest should form a strong cluster, as they are linked through long range optical flow chains and have similar motion and appearance features along those chains. On one hand, the optimization problem aims to maximize the segmentation clustering score based on the motion structure through space and time. On the other hand, the segmentation should be consistent with respect to node features. Our approach leads to a graph formulation in which the segmentation solution becomes the principal eigenvector of a novel Feature-Motion matrix. While the actual matrix is not computed explicitly, the proposed algorithm efficiently computes, in a few iteration steps, the principal eigenvector that captures the segmentation of the main object in the video. The proposed algorithm, GO-VOS, produces a global optimum solution and, consequently, it does not depend on initialization. In practice, GO-VOS achieves state of the art results on three challenging datasets used in current literature: DAVIS, SegTrack and YouTube-Objects.
Unsupervised object segmentation in video by efficient selection of highly probable positive features
Apr 19, 2017
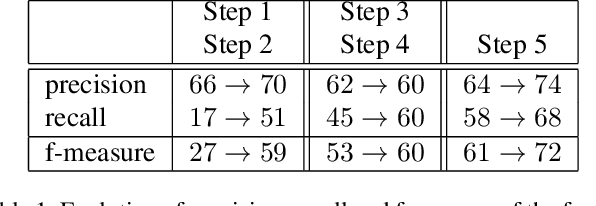

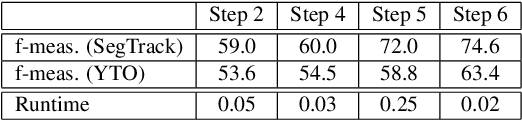
We address an essential problem in computer vision, that of unsupervised object segmentation in video, where a main object of interest in a video sequence should be automatically separated from its background. An efficient solution to this task would enable large-scale video interpretation at a high semantic level in the absence of the costly manually labeled ground truth. We propose an efficient unsupervised method for generating foreground object soft-segmentation masks based on automatic selection and learning from highly probable positive features. We show that such features can be selected efficiently by taking into consideration the spatio-temporal, appearance and motion consistency of the object during the whole observed sequence. We also emphasize the role of the contrasting properties between the foreground object and its background. Our model is created in two stages: we start from pixel level analysis, on top of which we add a regression model trained on a descriptor that considers information over groups of pixels and is both discriminative and invariant to many changes that the object undergoes throughout the video. We also present theoretical properties of our unsupervised learning method, that under some mild constraints is guaranteed to learn a correct discriminative classifier even in the unsupervised case. Our method achieves competitive and even state of the art results on the challenging Youtube-Objects and SegTrack datasets, while being at least one order of magnitude faster than the competition. We believe that the competitive performance of our method in practice, along with its theoretical properties, constitute an important step towards solving unsupervised discovery in video.