 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised object segmentation in video by efficient selection of highly probable positive features
Paper and Code
Apr 19, 2017
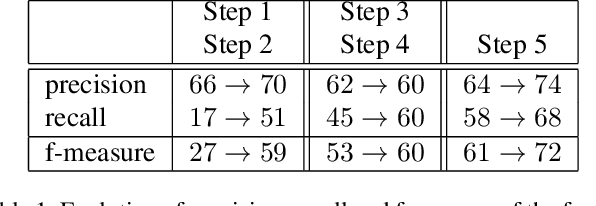

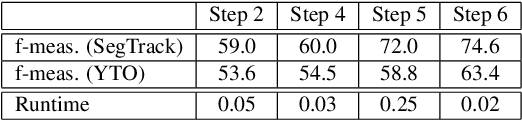
We address an essential problem in computer vision, that of unsupervised object segmentation in video, where a main object of interest in a video sequence should be automatically separated from its background. An efficient solution to this task would enable large-scale video interpretation at a high semantic level in the absence of the costly manually labeled ground truth. We propose an efficient unsupervised method for generating foreground object soft-segmentation masks based on automatic selection and learning from highly probable positive features. We show that such features can be selected efficiently by taking into consideration the spatio-temporal, appearance and motion consistency of the object during the whole observed sequence. We also emphasize the role of the contrasting properties between the foreground object and its background. Our model is created in two stages: we start from pixel level analysis, on top of which we add a regression model trained on a descriptor that considers information over groups of pixels and is both discriminative and invariant to many changes that the object undergoes throughout the video. We also present theoretical properties of our unsupervised learning method, that under some mild constraints is guaranteed to learn a correct discriminative classifier even in the unsupervised case. Our method achieves competitive and even state of the art results on the challenging Youtube-Objects and SegTrack datasets, while being at least one order of magnitude faster than the competition. We believe that the competitive performance of our method in practice, along with its theoretical properties, constitute an important step towards solving unsupervised discovery in video.