 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Înţelegi Româneşte?'' A Recipe for Romanian Vision-Language Models
Jun 01, 2026Vision-Language Models (VLMs) largely follow the text-only LLM trajectory, excelling on English benchmarks but sharply degrading on low-resource languages, where neither large-scale image-text corpora nor culturally grounded evaluations exist. We present a systematic study of building a language-specific VLM for Romanian, covering the full pipeline from data construction to architectural choices. We translate established English VLM training and evaluation corpora into Romanian, applying machine translation to textual annotations and to in-image text, preserving visual grounding while adapting the textual content. Using this data, we train and ablate a series of VLMs to isolate the contribution of (i) vision backbones of varying scale and pretraining, (ii) language backbones from multilingual to Romanian-adapted LLMs, and (iii) OCR-style image-text data. We further curate HoraVQA, a culturally native evaluation set grounded in Romanian everyday scenes. Romanian-adapted VLMs consistently outperform their same-sized counterparts and, across all evaluated benchmarks, even surpass models from the next larger size category.
idSCD: Identifying Training Datasets through Semantic Correlation Descriptors
May 28, 2026Can a dataset be recognized from the spurious correlations it induces during training? We argue that datasets leave dataset-specific traces in a model's learned semantic correlation structure: incidental regularities that are predictive within a dataset, but not causal for the underlying task, can be internalized during training. We use this insight to study dataset-level membership inference, moving beyond existing methods that rely on behavioral or distributional evidence such as confidence scores, losses, margins, generated samples, or query responses. We introduce a white-box semantic fingerprinting approach based on semantic correlation descriptors (SCDs), which capture the semantic correlation structure learned by a model and make it comparable across dataset mixtures. In a controlled leave-one-dataset-out diagnostic, SCDs recover dataset-specific changes and perfectly separate matching from non-matching dataset pairs. We then propose a practical SCD-based membership score that tests whether a target dataset is part of a model's training mixture using only the model's SCD and the target dataset's standalone SCD, without requiring leave-one-dataset-out models. Across three diverse experimental settings, with dataset groups for natural language inference, emotion classification, and medical text classification, we test both the advantages and limitations of SCD-based membership inference with different degrees of semantic separation and keyword support between dataset splits. On average, the classifier based on this score achieves the highest performance and the lowest std, outperforming black-box baselines RMIA, Attack-P, and LiRA, as well as the white-box SIF baseline. These results show that dataset membership can be traced through internal semantic correlations, with the largest relative gain exceeding 60% in ROC-AUC when dataset groups expose distinct semantic particularities.
GTASA: Ground Truth Annotations for Spatiotemporal Analysis, Evaluation and Training of Video Models
Apr 12, 2026Generating complex multi-actor scenario videos remains difficult even for state-of-the-art neural generators, while evaluating them is hard due to the lack of ground truth for physical plausibility and semantic faithfulness. We introduce GTASA, a corpus of multi-actor videos with per-frame spatial relation graphs and event-level temporal mappings, and the system that produced it based on Graphs of Events in Space and Time (GEST): GEST-Engine. We compare our method with both open and closed source neural generators and prove both qualitatively (human evaluation of physical validity and semantic alignment) and quantitatively (via training video captioning models) the clear advantages of our method. Probing four frozen video encoders across 11 spatiotemporal reasoning tasks enabled by GTASA's exact 3D ground truth reveals that self-supervised encoders encode spatial structure significantly better than VLM visual encoders.
Agentic Video Generation: From Text to Executable Event Graphs via Tool-Constrained LLM Planning
Apr 11, 2026Existing multi-agent video generation systems use LLM agents to orchestrate neural video generators, producing visually impressive but semantically unreliable outputs with no ground truth annotations. We present an agentic system that inverts this paradigm: instead of generating pixels, the LLM constructs a formal Graph of Events in Space and Time (GEST) -- a structured specification of actors, actions, objects, and temporal constraints -- which is then executed deterministically in a 3D game engine. A staged LLM refinement pipeline fails entirely at this task (0 of 50 attempts produce an executable specification), motivating a fundamentally different architecture based on a separation of concerns: the LLM handles narrative planning through natural language reasoning, while a programmatic state backend enforces all simulator constraints through validated tool calls, guaranteeing that every generated specification is executable by construction. The system uses a hierarchical two-agent architecture -- a Director that plans the story and a Scene Builder that constructs individual scenes through a round-based state machine -- with dedicated Relation Subagents that populate the logical and semantic edge types of the GEST formalism that procedural generation leaves empty, making this the first approach to exercise the full expressive capacity of the representation. We evaluate in two stages: autonomous generation against procedural baselines via a 3-model LLM jury, where agentic narratives win 79% of text and 74% of video comparisons; and seeded generation where the same text is given to our system, VEO 3.1, and WAN 2.2, with human annotations showing engine-generated videos substantially outperform neural generators on physical validity (58% vs 25% and 20%) and semantic alignment (3.75/5 vs 2.33 and 1.50).
Non-verbal Real-time Human-AI Interaction in Constrained Robotic Environments
Mar 02, 2026We study the ongoing debate regarding the statistical fidelity of AI-generated data compared to human-generated data in the context of non-verbal communication using full body motion. Concretely, we ask if contemporary generative models move beyond surface mimicry to participate in the silent, but expressive dialogue of body language. We tackle this question by introducing the first framework that generates a natural non-verbal interaction between Human and AI in real-time from 2D body keypoints. Our experiments utilize four lightweight architectures which run at up to 100 FPS on an NVIDIA Orin Nano, effectively closing the perception-action loop needed for natural Human-AI interaction. We trained on 437 human video clips and demonstrated that pretraining on synthetically-generated sequences reduces motion errors significantly, without sacrificing speed. Yet, a measurable reality gap persists. When the best model is evaluated on keypoints extracted from cutting-edge text-to-video systems, such as SORA and VEO, we observe that performance drops on SORA-generated clips. However, it degrades far less on VEO, suggesting that temporal coherence, not image fidelity, drives real-world performance. Our results demonstrate that statistically distinguishable differences persist between Human and AI motion.
Learning on the Fly: Replay-Based Continual Object Perception for Indoor Drones
Feb 13, 2026Autonomous agents such as indoor drones must learn new object classes in real-time while limiting catastrophic forgetting, motivating Class-Incremental Learning (CIL). However, most unmanned aerial vehicle (UAV) datasets focus on outdoor scenes and offer limited temporally coherent indoor videos. We introduce an indoor dataset of $14,400$ frames capturing inter-drone and ground vehicle footage, annotated via a semi-automatic workflow with a $98.6\%$ first-pass labeling agreement before final manual verification. Using this dataset, we benchmark 3 replay-based CIL strategies: Experience Replay (ER), Maximally Interfered Retrieval (MIR), and Forgetting-Aware Replay (FAR), using YOLOv11-nano as a resource-efficient detector for deployment-constrained UAV platforms. Under tight memory budgets ($5-10\%$ replay), FAR performs better than the rest, achieving an average accuracy (ACC, $mAP_{50-95}$ across increments) of $82.96\%$ with $5\%$ replay. Gradient-weighted class activation mapping (Grad-CAM) analysis shows attention shifts across classes in mixed scenes, which is associated with reduced localization quality for drones. The experiments further demonstrate that replay-based continual learning can be effectively applied to edge aerial systems. Overall, this work contributes an indoor UAV video dataset with preserved temporal coherence and an evaluation of replay-based CIL under limited replay budgets. Project page: https://spacetime-vision-robotics-laboratory.github.io/learning-on-the-fly-cl
With Great Context Comes Great Prediction Power: Classifying Objects via Geo-Semantic Scene Graphs
Dec 28, 2025Humans effortlessly identify objects by leveraging a rich understanding of the surrounding scene, including spatial relationships, material properties, and the co-occurrence of other objects. In contrast, most computational object recognition systems operate on isolated image regions, devoid of meaning in isolation, thus ignoring this vital contextual information. This paper argues for the critical role of context and introduces a novel framework for contextual object classification. We first construct a Geo-Semantic Contextual Graph (GSCG) from a single monocular image. This rich, structured representation is built by integrating a metric depth estimator with a unified panoptic and material segmentation model. The GSCG encodes objects as nodes with detailed geometric, chromatic, and material attributes, and their spatial relationships as edges. This explicit graph structure makes the model's reasoning process inherently interpretable. We then propose a specialized graph-based classifier that aggregates features from a target object, its immediate neighbors, and the global scene context to predict its class. Through extensive ablation studies, we demonstrate that our context-aware model achieves a classification accuracy of 73.4%, dramatically outperforming context-agnostic versions (as low as 38.4%). Furthermore, our GSCG-based approach significantly surpasses strong baselines, including fine-tuned ResNet models (max 53.5%) and a state-of-the-art multimodal Large Language Model (LLM), Llama 4 Scout, which, even when given the full image alongside a detailed description of objects, maxes out at 42.3%. These results on COCO 2017 train/val splits highlight the superiority of explicitly structured and interpretable context for object recognition tasks.
Learning from Random Subspace Exploration: Generalized Test-Time Augmentation with Self-supervised Distillation
Jul 02, 2025



We introduce Generalized Test-Time Augmentation (GTTA), a highly effective method for improving the performance of a trained model, which unlike other existing Test-Time Augmentation approaches from the literature is general enough to be used off-the-shelf for many vision and non-vision tasks, such as classification, regression, image segmentation and object detection. By applying a new general data transformation, that randomly perturbs multiple times the PCA subspace projection of a test input, GTTA forms robust ensembles at test time in which, due to sound statistical properties, the structural and systematic noises in the initial input data is filtered out and final estimator errors are reduced. Different from other existing methods, we also propose a final self-supervised learning stage in which the ensemble output, acting as an unsupervised teacher, is used to train the initial single student model, thus reducing significantly the test time computational cost, at no loss in accuracy. Our tests and comparisons to strong TTA approaches and SoTA models on various vision and non-vision well-known datasets and tasks, such as image classification and segmentation, speech recognition and house price prediction, validate the generality of the proposed GTTA. Furthermore, we also prove its effectiveness on the more specific real-world task of salmon segmentation and detection in low-visibility underwater videos, for which we introduce DeepSalmon, the largest dataset of its kind in the literature.
Closer to Ground Truth: Realistic Shape and Appearance Labeled Data Generation for Unsupervised Underwater Image Segmentation
Mar 20, 2025
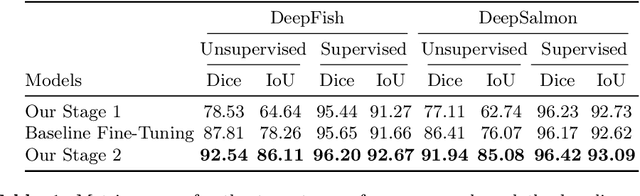

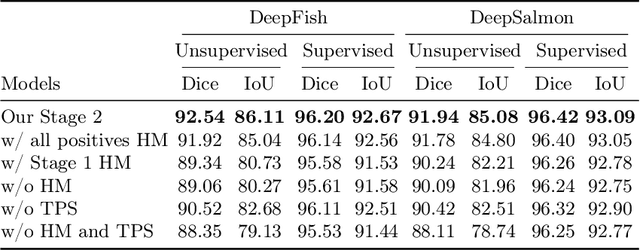
Solving fish segmentation in underwater videos, a real-world problem of great practical value in marine and aquaculture industry, is a challenging task due to the difficulty of the filming environment, poor visibility and limited existing annotated underwater fish data. In order to overcome these obstacles, we introduce a novel two stage unsupervised segmentation approach that requires no human annotations and combines artificially created and real images. Our method generates challenging synthetic training data, by placing virtual fish in real-world underwater habitats, after performing fish transformations such as Thin Plate Spline shape warping and color Histogram Matching, which realistically integrate synthetic fish into the backgrounds, making the generated images increasingly closer to the real world data with every stage of our approach. While we validate our unsupervised method on the popular DeepFish dataset, obtaining a performance close to a fully-supervised SoTA model, we further show its effectiveness on the specific case of salmon segmentation in underwater videos, for which we introduce DeepSalmon, the largest dataset of its kind in the literature (30 GB). Moreover, on both datasets we prove the capability of our approach to boost the performance of the fully-supervised SoTA model.
A self-supervised cyclic neural-analytic approach for novel view synthesis and 3D reconstruction
Mar 05, 2025Generating novel views from recorded videos is crucial for enabling autonomous UAV navigation. Recent advancements in neural rendering have facilitated the rapid development of methods capable of rendering new trajectories. However, these methods often fail to generalize well to regions far from the training data without an optimized flight path, leading to suboptimal reconstructions. We propose a self-supervised cyclic neural-analytic pipeline that combines high-quality neural rendering outputs with precise geometric insights from analytical methods. Our solution improves RGB and mesh reconstructions for novel view synthesis, especially in undersampled areas and regions that are completely different from the training dataset. We use an effective transformer-based architecture for image reconstruction to refine and adapt the synthesis process, enabling effective handling of novel, unseen poses without relying on extensive labeled datasets. Our findings demonstrate substantial improvements in rendering views of novel and also 3D reconstruction, which to the best of our knowledge is a first, setting a new standard for autonomous navigation in complex outdoor environments.
* Published in BMVC 2024, 10 pages, 4 figures