 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA self-supervised cyclic neural-analytic approach for novel view synthesis and 3D reconstruction
Mar 05, 2025Generating novel views from recorded videos is crucial for enabling autonomous UAV navigation. Recent advancements in neural rendering have facilitated the rapid development of methods capable of rendering new trajectories. However, these methods often fail to generalize well to regions far from the training data without an optimized flight path, leading to suboptimal reconstructions. We propose a self-supervised cyclic neural-analytic pipeline that combines high-quality neural rendering outputs with precise geometric insights from analytical methods. Our solution improves RGB and mesh reconstructions for novel view synthesis, especially in undersampled areas and regions that are completely different from the training dataset. We use an effective transformer-based architecture for image reconstruction to refine and adapt the synthesis process, enabling effective handling of novel, unseen poses without relying on extensive labeled datasets. Our findings demonstrate substantial improvements in rendering views of novel and also 3D reconstruction, which to the best of our knowledge is a first, setting a new standard for autonomous navigation in complex outdoor environments.
* Published in BMVC 2024, 10 pages, 4 figures
Maia: A Real-time Non-Verbal Chat for Human-AI Interaction
Feb 09, 2024



Face-to-face communication modeling in computer vision is an area of research focusing on developing algorithms that can recognize and analyze non-verbal cues and behaviors during face-to-face interactions. We propose an alternative to text chats for Human-AI interaction, based on non-verbal visual communication only, using facial expressions and head movements that mirror, but also improvise over the human user, to efficiently engage with the users, and capture their attention in a low-cost and real-time fashion. Our goal is to track and analyze facial expressions, and other non-verbal cues in real-time, and use this information to build models that can predict and understand human behavior. We offer three different complementary approaches, based on retrieval, statistical, and deep learning techniques. We provide human as well as automatic evaluations and discuss the advantages and disadvantages of each direction.
Self-supervised Hypergraphs for Learning Multiple World Interpretations
Aug 21, 2023We present a method for learning multiple scene representations given a small labeled set, by exploiting the relationships between such representations in the form of a multi-task hypergraph. We also show how we can use the hypergraph to improve a powerful pretrained VisTransformer model without any additional labeled data. In our hypergraph, each node is an interpretation layer (e.g., depth or segmentation) of the scene. Within each hyperedge, one or several input nodes predict the layer at the output node. Thus, each node could be an input node in some hyperedges and an output node in others. In this way, multiple paths can reach the same node, to form ensembles from which we obtain robust pseudolabels, which allow self-supervised learning in the hypergraph. We test different ensemble models and different types of hyperedges and show superior performance to other multi-task graph models in the field. We also introduce Dronescapes, a large video dataset captured with UAVs in different complex real-world scenes, with multiple representations, suitable for multi-task learning.
Self-supervised novel 2D view synthesis of large-scale scenes with efficient multi-scale voxel carving
Jun 26, 2023



The task of generating novel views of real scenes is increasingly important nowadays when AI models become able to create realistic new worlds. In many practical applications, it is important for novel view synthesis methods to stay grounded in the physical world as much as possible, while also being able to imagine it from previously unseen views. While most current methods are developed and tested in virtual environments with small scenes and no errors in pose and depth information, we push the boundaries to the real-world domain of large scales in the new context of UAVs. Our algorithmic contributions are two folds. First, we manage to stay anchored in the real 3D world, by introducing an efficient multi-scale voxel carving method, which is able to accommodate significant noises in pose, depth, and illumination variations, while being able to reconstruct the view of the world from drastically different poses at test time. Second, our final high-resolution output is efficiently self-trained on data automatically generated by the voxel carving module, which gives it the flexibility to adapt efficiently to any scene. We demonstrated the effectiveness of our method on highly complex and large-scale scenes in real environments while outperforming the current state-of-the-art. Our code is publicly available: https://github.com/onorabil/MSVC.
Semi-Supervised Learning for Multi-Task Scene Understanding by Neural Graph Consensus
Oct 02, 2020
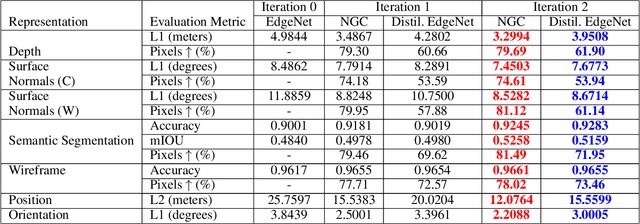


We address the challenging problem of semi-supervised learning in the context of multiple visual interpretations of the world by finding consensus in a graph of neural networks. Each graph node is a scene interpretation layer, while each edge is a deep net that transforms one layer at one node into another from a different node. During the supervised phase edge networks are trained independently. During the next unsupervised stage edge nets are trained on the pseudo-ground truth provided by consensus among multiple paths that reach the nets' start and end nodes. These paths act as ensemble teachers for any given edge and strong consensus is used for high-confidence supervisory signal. The unsupervised learning process is repeated over several generations, in which each edge becomes a "student" and also part of different ensemble "teachers" for training other students. By optimizing such consensus between different paths, the graph reaches consistency and robustness over multiple interpretations and generations, in the face of unknown labels. We give theoretical justifications of the proposed idea and validate it on a large dataset. We show how prediction of different representations such as depth, semantic segmentation, surface normals and pose from RGB input could be effectively learned through self-supervised consensus in our graph. We also compare to state-of-the-art methods for multi-task and semi-supervised learning and show superior performance.
Semantics through Time: Semi-supervised Segmentation of Aerial Videos with Iterative Label Propagation
Oct 02, 2020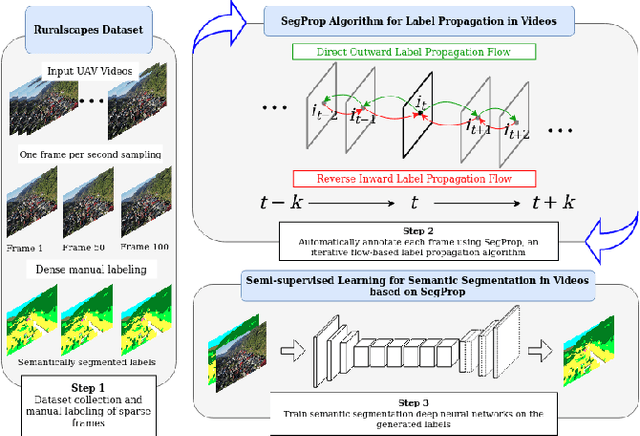
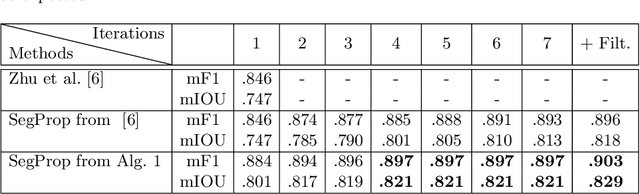
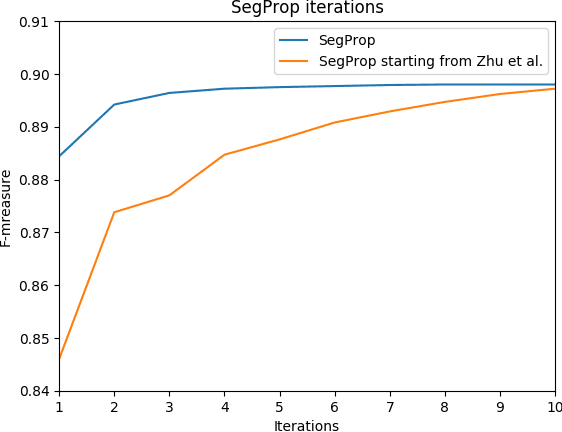

Semantic segmentation is a crucial task for robot navigation and safety. However, current supervised methods require a large amount of pixelwise annotations to yield accurate results. Labeling is a tedious and time consuming process that has hampered progress in low altitude UAV applications. This paper makes an important step towards automatic annotation by introducing SegProp, a novel iterative flow-based method, with a direct connection to spectral clustering in space and time, to propagate the semantic labels to frames that lack human annotations. The labels are further used in semi-supervised learning scenarios. Motivated by the lack of a large video aerial dataset, we also introduce Ruralscapes, a new dataset with high resolution (4K) images and manually-annotated dense labels every 50 frames - the largest of its kind, to the best of our knowledge. Our novel SegProp automatically annotates the remaining unlabeled 98% of frames with an accuracy exceeding 90% (F-measure), significantly outperforming other state-of-the-art label propagation methods. Moreover, when integrating other methods as modules inside SegProp's iterative label propagation loop, we achieve a significant boost over the baseline labels. Finally, we test SegProp in a full semi-supervised setting: we train several state-of-the-art deep neural networks on the SegProp-automatically-labeled training frames and test them on completely novel videos. We convincingly demonstrate, every time, a significant improvement over the supervised scenario.
Towards Automatic Annotation for Semantic Segmentation in Drone Videos
Oct 22, 2019

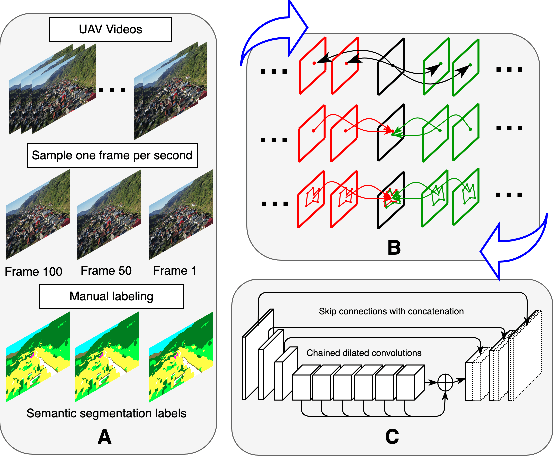

Semantic segmentation is a crucial task for robot navigation and safety. However, it requires huge amounts of pixelwise annotations to yield accurate results. While recent progress in computer vision algorithms has been heavily boosted by large ground-level datasets, the labeling time has hampered progress in low altitude UAV applications, mostly due to the difficulty imposed by large object scales and pose variations. Motivated by the lack of a large video aerial dataset, we introduce a new one, with high resolution (4K) images and manually-annotated dense labels every 50 frames. To help the video labeling process, we make an important step towards automatic annotation and propose SegProp, an iterative flow-based method with geometric constrains to propagate the semantic labels to frames that lack human annotations. This results in a dataset with more than 50k annotated frames - the largest of its kind, to the best of our knowledge. Our experiments show that SegProp surpasses current state-of-the-art label propagation methods by a significant margin. Furthermore, when training a semantic segmentation deep neural net using the automatically annotated frames, we obtain a compelling overall performance boost at test time of 16.8% mean F-measure over a baseline trained only with manually-labeled frames. Our Ruralscapes dataset, the label propagation code and a fast segmentation tool are available at our website: https://sites.google.com/site/aerialimageunderstanding/
A Multi-Stage Multi-Task Neural Network for Aerial Scene Interpretation and Geolocalization
Apr 04, 2018


Semantic segmentation and vision-based geolocalization in aerial images are challenging tasks in computer vision. Due to the advent of deep convolutional nets and the availability of relatively low cost UAVs, they are currently generating a growing attention in the field. We propose a novel multi-task multi-stage neural network that is able to handle the two problems at the same time, in a single forward pass. The first stage of our network predicts pixelwise class labels, while the second stage provides a precise location using two branches. One branch uses a regression network, while the other is used to predict a location map trained as a segmentation task. From a structural point of view, our architecture uses encoder-decoder modules at each stage, having the same encoder structure re-used. Furthermore, its size is limited to be tractable on an embedded GPU. We achieve commercial GPS-level localization accuracy from satellite images with spatial resolution of 1 square meter per pixel in a city-wide area of interest. On the task of semantic segmentation, we obtain state-of-the-art results on two challenging datasets, the Inria Aerial Image Labeling dataset and Massachusetts Buildings.
Aerial image geolocalization from recognition and matching of roads and intersections
May 26, 2016



Aerial image analysis at a semantic level is important in many applications with strong potential impact in industry and consumer use, such as automated mapping, urban planning, real estate and environment monitoring, or disaster relief. The problem is enjoying a great interest in computer vision and remote sensing, due to increased computer power and improvement in automated image understanding algorithms. In this paper we address the task of automatic geolocalization of aerial images from recognition and matching of roads and intersections. Our proposed method is a novel contribution in the literature that could enable many applications of aerial image analysis when GPS data is not available. We offer a complete pipeline for geolocalization, from the detection of roads and intersections, to the identification of the enclosing geographic region by matching detected intersections to previously learned manually labeled ones, followed by accurate geometric alignment between the detected roads and the manually labeled maps. We test on a novel dataset with aerial images of two European cities and use the publicly available OpenStreetMap project for collecting ground truth roads annotations. We show in extensive experiments that our approach produces highly accurate localizations in the challenging case when we train on images from one city and test on the other and the quality of the aerial images is relatively poor. We also show that the the alignment between detected roads and pre-stored manual annotations can be effectively used for improving the quality of the road detection results.