 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time body pose non-verbal communication with a consistency-based reliability measure
Jun 08, 2026Body movement communicates intent at distances and in conditions where neither the face, nor speech can be captured. We study the recognition of communicative intent from 2D body pose alone. We argue that body motion is a reliable signal especially in scenarios that require real time low-cost on-device person-to-robot communication in long distance environments, such as rescue missions. However, existing resources do not isolate this signal. Affective corpora combine body, face, voice and text, while skeleton action-recognition benchmarks label the action performed rather than the message conveyed. We release a dataset of real frames of full-body pose covering ten communicative intents and we compare it against other real (IPC) and synthetic (MotionLCM, VEO3.1, Kimodo) ones that span a range of difficulty. We target systems that can run on a robot's limited onboard hardware. We benchmark multiple models, from skeleton graph classifiers to joint motion-forecasting networks, and report performance metrics together with frame rate on an embedded GPU (NVIDIA Orin~Nano), since speed matters as much as accuracy in our scenario. Finally, we show that a model's own autoregressive self-consistency works as an unsupervised reliability signal. We give a short proof that bounds the probability that a self-consistent prediction is correct, show that this probability grows with the number of consistent steps, and identify the conditions under which a confident prediction can still be false, benchmarked against industry-standard metrics.
Non-verbal Real-time Human-AI Interaction in Constrained Robotic Environments
Mar 02, 2026We study the ongoing debate regarding the statistical fidelity of AI-generated data compared to human-generated data in the context of non-verbal communication using full body motion. Concretely, we ask if contemporary generative models move beyond surface mimicry to participate in the silent, but expressive dialogue of body language. We tackle this question by introducing the first framework that generates a natural non-verbal interaction between Human and AI in real-time from 2D body keypoints. Our experiments utilize four lightweight architectures which run at up to 100 FPS on an NVIDIA Orin Nano, effectively closing the perception-action loop needed for natural Human-AI interaction. We trained on 437 human video clips and demonstrated that pretraining on synthetically-generated sequences reduces motion errors significantly, without sacrificing speed. Yet, a measurable reality gap persists. When the best model is evaluated on keypoints extracted from cutting-edge text-to-video systems, such as SORA and VEO, we observe that performance drops on SORA-generated clips. However, it degrades far less on VEO, suggesting that temporal coherence, not image fidelity, drives real-world performance. Our results demonstrate that statistically distinguishable differences persist between Human and AI motion.
A self-supervised cyclic neural-analytic approach for novel view synthesis and 3D reconstruction
Mar 05, 2025Generating novel views from recorded videos is crucial for enabling autonomous UAV navigation. Recent advancements in neural rendering have facilitated the rapid development of methods capable of rendering new trajectories. However, these methods often fail to generalize well to regions far from the training data without an optimized flight path, leading to suboptimal reconstructions. We propose a self-supervised cyclic neural-analytic pipeline that combines high-quality neural rendering outputs with precise geometric insights from analytical methods. Our solution improves RGB and mesh reconstructions for novel view synthesis, especially in undersampled areas and regions that are completely different from the training dataset. We use an effective transformer-based architecture for image reconstruction to refine and adapt the synthesis process, enabling effective handling of novel, unseen poses without relying on extensive labeled datasets. Our findings demonstrate substantial improvements in rendering views of novel and also 3D reconstruction, which to the best of our knowledge is a first, setting a new standard for autonomous navigation in complex outdoor environments.
* Published in BMVC 2024, 10 pages, 4 figures
Quantifying the synthetic and real domain gap in aerial scene understanding
Nov 29, 2024Quantifying the gap between synthetic and real-world imagery is essential for improving both transformer-based models - that rely on large volumes of data - and datasets, especially in underexplored domains like aerial scene understanding where the potential impact is significant. This paper introduces a novel methodology for scene complexity assessment using Multi-Model Consensus Metric (MMCM) and depth-based structural metrics, enabling a robust evaluation of perceptual and structural disparities between domains. Our experimental analysis, utilizing real-world (Dronescapes) and synthetic (Skyscenes) datasets, demonstrates that real-world scenes generally exhibit higher consensus among state-of-the-art vision transformers, while synthetic scenes show greater variability and challenge model adaptability. The results underline the inherent complexities and domain gaps, emphasizing the need for enhanced simulation fidelity and model generalization. This work provides critical insights into the interplay between domain characteristics and model performance, offering a pathway for improved domain adaptation strategies in aerial scene understanding.
Maia: A Real-time Non-Verbal Chat for Human-AI Interaction
Feb 09, 2024



Face-to-face communication modeling in computer vision is an area of research focusing on developing algorithms that can recognize and analyze non-verbal cues and behaviors during face-to-face interactions. We propose an alternative to text chats for Human-AI interaction, based on non-verbal visual communication only, using facial expressions and head movements that mirror, but also improvise over the human user, to efficiently engage with the users, and capture their attention in a low-cost and real-time fashion. Our goal is to track and analyze facial expressions, and other non-verbal cues in real-time, and use this information to build models that can predict and understand human behavior. We offer three different complementary approaches, based on retrieval, statistical, and deep learning techniques. We provide human as well as automatic evaluations and discuss the advantages and disadvantages of each direction.
Multi-Task Hypergraphs for Semi-supervised Learning using Earth Observations
Aug 21, 2023



There are many ways of interpreting the world and they are highly interdependent. We exploit such complex dependencies and introduce a powerful multi-task hypergraph, in which every node is a task and different paths through the hypergraph reaching a given task become unsupervised teachers, by forming ensembles that learn to generate reliable pseudolabels for that task. Each hyperedge is part of an ensemble teacher for a given task and it is also a student of the self-supervised hypergraph system. We apply our model to one of the most important problems of our times, that of Earth Observation, which is highly multi-task and it often suffers from missing ground-truth data. By performing extensive experiments on the NASA NEO Dataset, spanning a period of 22 years, we demonstrate the value of our multi-task semi-supervised approach, by consistent improvements over strong baselines and recent work. We also show that the hypergraph can adapt unsupervised to gradual data distribution shifts and reliably recover, through its multi-task self-supervision process, the missing data for several observational layers for up to seven years.
Self-supervised Hypergraphs for Learning Multiple World Interpretations
Aug 21, 2023We present a method for learning multiple scene representations given a small labeled set, by exploiting the relationships between such representations in the form of a multi-task hypergraph. We also show how we can use the hypergraph to improve a powerful pretrained VisTransformer model without any additional labeled data. In our hypergraph, each node is an interpretation layer (e.g., depth or segmentation) of the scene. Within each hyperedge, one or several input nodes predict the layer at the output node. Thus, each node could be an input node in some hyperedges and an output node in others. In this way, multiple paths can reach the same node, to form ensembles from which we obtain robust pseudolabels, which allow self-supervised learning in the hypergraph. We test different ensemble models and different types of hyperedges and show superior performance to other multi-task graph models in the field. We also introduce Dronescapes, a large video dataset captured with UAVs in different complex real-world scenes, with multiple representations, suitable for multi-task learning.
Self-supervised novel 2D view synthesis of large-scale scenes with efficient multi-scale voxel carving
Jun 26, 2023



The task of generating novel views of real scenes is increasingly important nowadays when AI models become able to create realistic new worlds. In many practical applications, it is important for novel view synthesis methods to stay grounded in the physical world as much as possible, while also being able to imagine it from previously unseen views. While most current methods are developed and tested in virtual environments with small scenes and no errors in pose and depth information, we push the boundaries to the real-world domain of large scales in the new context of UAVs. Our algorithmic contributions are two folds. First, we manage to stay anchored in the real 3D world, by introducing an efficient multi-scale voxel carving method, which is able to accommodate significant noises in pose, depth, and illumination variations, while being able to reconstruct the view of the world from drastically different poses at test time. Second, our final high-resolution output is efficiently self-trained on data automatically generated by the voxel carving module, which gives it the flexibility to adapt efficiently to any scene. We demonstrated the effectiveness of our method on highly complex and large-scale scenes in real environments while outperforming the current state-of-the-art. Our code is publicly available: https://github.com/onorabil/MSVC.
Semi-Supervised Learning for Multi-Task Scene Understanding by Neural Graph Consensus
Oct 02, 2020
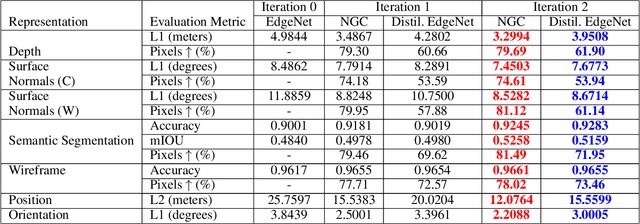


We address the challenging problem of semi-supervised learning in the context of multiple visual interpretations of the world by finding consensus in a graph of neural networks. Each graph node is a scene interpretation layer, while each edge is a deep net that transforms one layer at one node into another from a different node. During the supervised phase edge networks are trained independently. During the next unsupervised stage edge nets are trained on the pseudo-ground truth provided by consensus among multiple paths that reach the nets' start and end nodes. These paths act as ensemble teachers for any given edge and strong consensus is used for high-confidence supervisory signal. The unsupervised learning process is repeated over several generations, in which each edge becomes a "student" and also part of different ensemble "teachers" for training other students. By optimizing such consensus between different paths, the graph reaches consistency and robustness over multiple interpretations and generations, in the face of unknown labels. We give theoretical justifications of the proposed idea and validate it on a large dataset. We show how prediction of different representations such as depth, semantic segmentation, surface normals and pose from RGB input could be effectively learned through self-supervised consensus in our graph. We also compare to state-of-the-art methods for multi-task and semi-supervised learning and show superior performance.
Semantics through Time: Semi-supervised Segmentation of Aerial Videos with Iterative Label Propagation
Oct 02, 2020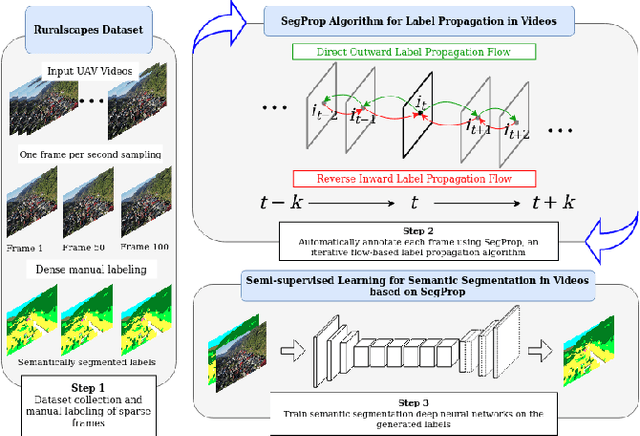
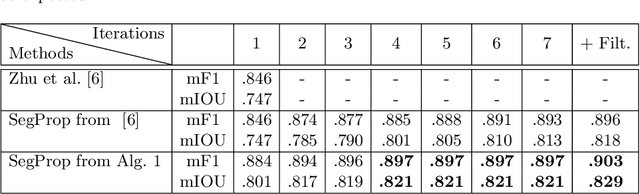
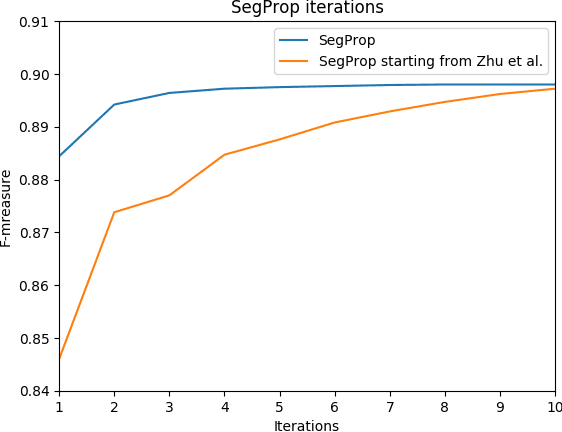

Semantic segmentation is a crucial task for robot navigation and safety. However, current supervised methods require a large amount of pixelwise annotations to yield accurate results. Labeling is a tedious and time consuming process that has hampered progress in low altitude UAV applications. This paper makes an important step towards automatic annotation by introducing SegProp, a novel iterative flow-based method, with a direct connection to spectral clustering in space and time, to propagate the semantic labels to frames that lack human annotations. The labels are further used in semi-supervised learning scenarios. Motivated by the lack of a large video aerial dataset, we also introduce Ruralscapes, a new dataset with high resolution (4K) images and manually-annotated dense labels every 50 frames - the largest of its kind, to the best of our knowledge. Our novel SegProp automatically annotates the remaining unlabeled 98% of frames with an accuracy exceeding 90% (F-measure), significantly outperforming other state-of-the-art label propagation methods. Moreover, when integrating other methods as modules inside SegProp's iterative label propagation loop, we achieve a significant boost over the baseline labels. Finally, we test SegProp in a full semi-supervised setting: we train several state-of-the-art deep neural networks on the SegProp-automatically-labeled training frames and test them on completely novel videos. We convincingly demonstrate, every time, a significant improvement over the supervised scenario.