 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity-based code embeddings
Jan 01, 2026This paper presents a generic method for transforming the source code of various algorithms to numerical embeddings, by dynamically analysing the behaviour of computer programs against different inputs and by tailoring multiple generic complexity functions for the analysed metrics. The used algorithms embeddings are based on r-Complexity . Using the proposed code embeddings, we present an implementation of the XGBoost algorithm that achieves an average F1-score on a multi-label dataset with 11 classes, built using real-world code snippets submitted for programming competitions on the Codeforces platform.
Self-supervised Hypergraphs for Learning Multiple World Interpretations
Aug 21, 2023We present a method for learning multiple scene representations given a small labeled set, by exploiting the relationships between such representations in the form of a multi-task hypergraph. We also show how we can use the hypergraph to improve a powerful pretrained VisTransformer model without any additional labeled data. In our hypergraph, each node is an interpretation layer (e.g., depth or segmentation) of the scene. Within each hyperedge, one or several input nodes predict the layer at the output node. Thus, each node could be an input node in some hyperedges and an output node in others. In this way, multiple paths can reach the same node, to form ensembles from which we obtain robust pseudolabels, which allow self-supervised learning in the hypergraph. We test different ensemble models and different types of hyperedges and show superior performance to other multi-task graph models in the field. We also introduce Dronescapes, a large video dataset captured with UAVs in different complex real-world scenes, with multiple representations, suitable for multi-task learning.
Semi-Supervised Learning for Multi-Task Scene Understanding by Neural Graph Consensus
Oct 02, 2020
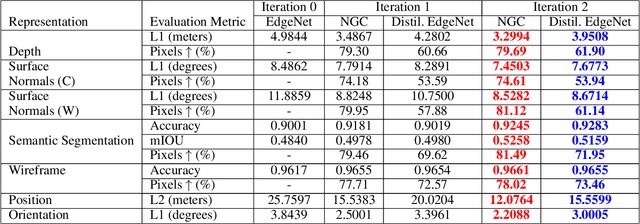


We address the challenging problem of semi-supervised learning in the context of multiple visual interpretations of the world by finding consensus in a graph of neural networks. Each graph node is a scene interpretation layer, while each edge is a deep net that transforms one layer at one node into another from a different node. During the supervised phase edge networks are trained independently. During the next unsupervised stage edge nets are trained on the pseudo-ground truth provided by consensus among multiple paths that reach the nets' start and end nodes. These paths act as ensemble teachers for any given edge and strong consensus is used for high-confidence supervisory signal. The unsupervised learning process is repeated over several generations, in which each edge becomes a "student" and also part of different ensemble "teachers" for training other students. By optimizing such consensus between different paths, the graph reaches consistency and robustness over multiple interpretations and generations, in the face of unknown labels. We give theoretical justifications of the proposed idea and validate it on a large dataset. We show how prediction of different representations such as depth, semantic segmentation, surface normals and pose from RGB input could be effectively learned through self-supervised consensus in our graph. We also compare to state-of-the-art methods for multi-task and semi-supervised learning and show superior performance.
A Multi-Stage Multi-Task Neural Network for Aerial Scene Interpretation and Geolocalization
Apr 04, 2018


Semantic segmentation and vision-based geolocalization in aerial images are challenging tasks in computer vision. Due to the advent of deep convolutional nets and the availability of relatively low cost UAVs, they are currently generating a growing attention in the field. We propose a novel multi-task multi-stage neural network that is able to handle the two problems at the same time, in a single forward pass. The first stage of our network predicts pixelwise class labels, while the second stage provides a precise location using two branches. One branch uses a regression network, while the other is used to predict a location map trained as a segmentation task. From a structural point of view, our architecture uses encoder-decoder modules at each stage, having the same encoder structure re-used. Furthermore, its size is limited to be tractable on an embedded GPU. We achieve commercial GPS-level localization accuracy from satellite images with spatial resolution of 1 square meter per pixel in a city-wide area of interest. On the task of semantic segmentation, we obtain state-of-the-art results on two challenging datasets, the Inria Aerial Image Labeling dataset and Massachusetts Buildings.