 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Random Subspace Exploration: Generalized Test-Time Augmentation with Self-supervised Distillation
Jul 02, 2025



We introduce Generalized Test-Time Augmentation (GTTA), a highly effective method for improving the performance of a trained model, which unlike other existing Test-Time Augmentation approaches from the literature is general enough to be used off-the-shelf for many vision and non-vision tasks, such as classification, regression, image segmentation and object detection. By applying a new general data transformation, that randomly perturbs multiple times the PCA subspace projection of a test input, GTTA forms robust ensembles at test time in which, due to sound statistical properties, the structural and systematic noises in the initial input data is filtered out and final estimator errors are reduced. Different from other existing methods, we also propose a final self-supervised learning stage in which the ensemble output, acting as an unsupervised teacher, is used to train the initial single student model, thus reducing significantly the test time computational cost, at no loss in accuracy. Our tests and comparisons to strong TTA approaches and SoTA models on various vision and non-vision well-known datasets and tasks, such as image classification and segmentation, speech recognition and house price prediction, validate the generality of the proposed GTTA. Furthermore, we also prove its effectiveness on the more specific real-world task of salmon segmentation and detection in low-visibility underwater videos, for which we introduce DeepSalmon, the largest dataset of its kind in the literature.
Leveraging Lightweight Generators for Memory Efficient Continual Learning
Jun 24, 2025Catastrophic forgetting can be trivially alleviated by keeping all data from previous tasks in memory. Therefore, minimizing the memory footprint while maximizing the amount of relevant information is crucial to the challenge of continual learning. This paper aims to decrease required memory for memory-based continuous learning algorithms. We explore the options of extracting a minimal amount of information, while maximally alleviating forgetting. We propose the usage of lightweight generators based on Singular Value Decomposition to enhance existing continual learning methods, such as A-GEM and Experience Replay. These generators need a minimal amount of memory while being maximally effective. They require no training time, just a single linear-time fitting step, and can capture a distribution effectively from a small number of data samples. Depending on the dataset and network architecture, our results show a significant increase in average accuracy compared to the original methods. Our method shows great potential in minimizing the memory footprint of memory-based continual learning algorithms.
Learning Graph Representation of Agent Diffusers
May 15, 2025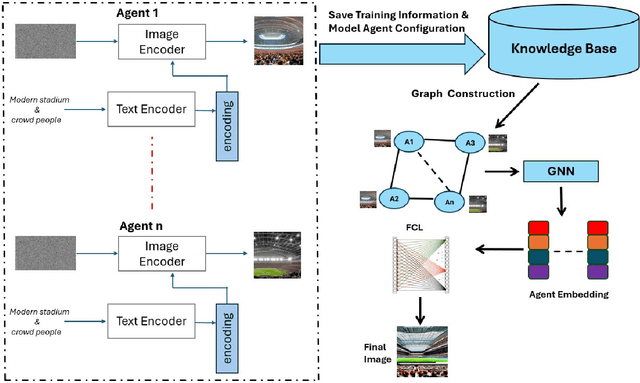

Diffusion-based generative models have significantly advanced text-to-image synthesis, demonstrating impressive text comprehension and zero-shot generalization. These models refine images from random noise based on textual prompts, with initial reliance on text input shifting towards enhanced visual fidelity over time. This transition suggests that static model parameters might not optimally address the distinct phases of generation. We introduce LGR-AD (Learning Graph Representation of Agent Diffusers), a novel multi-agent system designed to improve adaptability in dynamic computer vision tasks. LGR-AD models the generation process as a distributed system of interacting agents, each representing an expert sub-model. These agents dynamically adapt to varying conditions and collaborate through a graph neural network that encodes their relationships and performance metrics. Our approach employs a coordination mechanism based on top-$k$ maximum spanning trees, optimizing the generation process. Each agent's decision-making is guided by a meta-model that minimizes a novel loss function, balancing accuracy and diversity. Theoretical analysis and extensive empirical evaluations show that LGR-AD outperforms traditional diffusion models across various benchmarks, highlighting its potential for scalable and flexible solutions in complex image generation tasks. Code is available at: https://github.com/YousIA/LGR_AD
Closer to Ground Truth: Realistic Shape and Appearance Labeled Data Generation for Unsupervised Underwater Image Segmentation
Mar 20, 2025
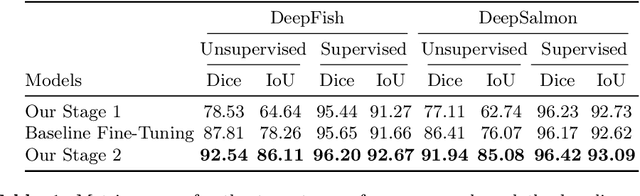

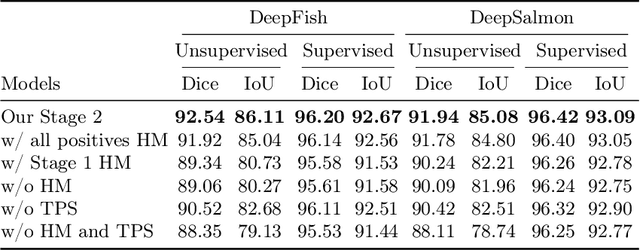
Solving fish segmentation in underwater videos, a real-world problem of great practical value in marine and aquaculture industry, is a challenging task due to the difficulty of the filming environment, poor visibility and limited existing annotated underwater fish data. In order to overcome these obstacles, we introduce a novel two stage unsupervised segmentation approach that requires no human annotations and combines artificially created and real images. Our method generates challenging synthetic training data, by placing virtual fish in real-world underwater habitats, after performing fish transformations such as Thin Plate Spline shape warping and color Histogram Matching, which realistically integrate synthetic fish into the backgrounds, making the generated images increasingly closer to the real world data with every stage of our approach. While we validate our unsupervised method on the popular DeepFish dataset, obtaining a performance close to a fully-supervised SoTA model, we further show its effectiveness on the specific case of salmon segmentation in underwater videos, for which we introduce DeepSalmon, the largest dataset of its kind in the literature (30 GB). Moreover, on both datasets we prove the capability of our approach to boost the performance of the fully-supervised SoTA model.
Precision in Building Extraction: Comparing Shallow and Deep Models using LiDAR Data
Sep 21, 2023



Building segmentation is essential in infrastructure development, population management, and geological observations. This article targets shallow models due to their interpretable nature to assess the presence of LiDAR data for supervised segmentation. The benchmark data used in this article are published in NORA MapAI competition for deep learning model. Shallow models are compared with deep learning models based on Intersection over Union (IoU) and Boundary Intersection over Union (BIoU). In the proposed work, boundary masks from the original mask are generated to improve the BIoU score, which relates to building shapes' borderline. The influence of LiDAR data is tested by training the model with only aerial images in task 1 and a combination of aerial and LiDAR data in task 2 and then compared. shallow models outperform deep learning models in IoU by 8% using aerial images (task 1) only and 2% in combined aerial images and LiDAR data (task 2). In contrast, deep learning models show better performance on BIoU scores. Boundary masks improve BIoU scores by 4% in both tasks. Light Gradient-Boosting Machine (LightGBM) performs better than RF and Extreme Gradient Boosting (XGBoost).
Self-supervised Hypergraphs for Learning Multiple World Interpretations
Aug 21, 2023We present a method for learning multiple scene representations given a small labeled set, by exploiting the relationships between such representations in the form of a multi-task hypergraph. We also show how we can use the hypergraph to improve a powerful pretrained VisTransformer model without any additional labeled data. In our hypergraph, each node is an interpretation layer (e.g., depth or segmentation) of the scene. Within each hyperedge, one or several input nodes predict the layer at the output node. Thus, each node could be an input node in some hyperedges and an output node in others. In this way, multiple paths can reach the same node, to form ensembles from which we obtain robust pseudolabels, which allow self-supervised learning in the hypergraph. We test different ensemble models and different types of hyperedges and show superior performance to other multi-task graph models in the field. We also introduce Dronescapes, a large video dataset captured with UAVs in different complex real-world scenes, with multiple representations, suitable for multi-task learning.
Saliency Can Be All You Need In Contrastive Self-Supervised Learning
Oct 30, 2022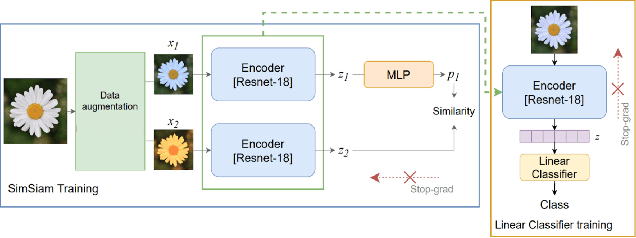


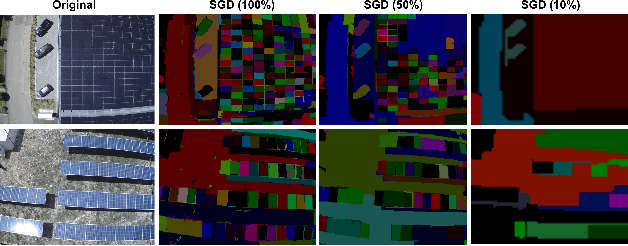
We propose an augmentation policy for Contrastive Self-Supervised Learning (SSL) in the form of an already established Salient Image Segmentation technique entitled Global Contrast based Salient Region Detection. This detection technique, which had been devised for unrelated Computer Vision tasks, was empirically observed to play the role of an augmentation facilitator within the SSL protocol. This observation is rooted in our practical attempts to learn, by SSL-fashion, aerial imagery of solar panels, which exhibit challenging boundary patterns. Upon the successful integration of this technique on our problem domain, we formulated a generalized procedure and conducted a comprehensive, systematic performance assessment with various Contrastive SSL algorithms subject to standard augmentation techniques. This evaluation, which was conducted across multiple datasets, indicated that the proposed technique indeed contributes to SSL. We hypothesize whether salient image segmentation may suffice as the only augmentation policy in Contrastive SSL when treating downstream segmentation tasks.
The Vision of Self-Evolving Computing Systems
Apr 14, 2022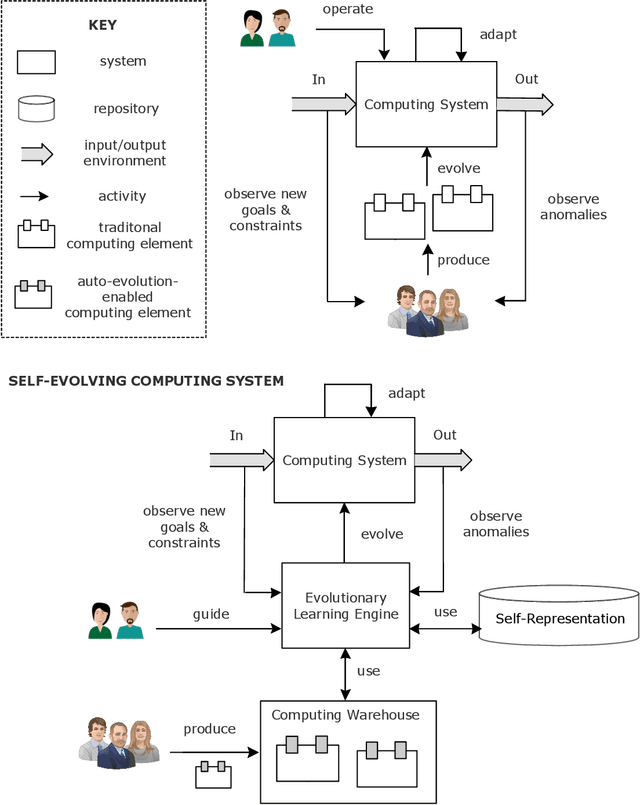
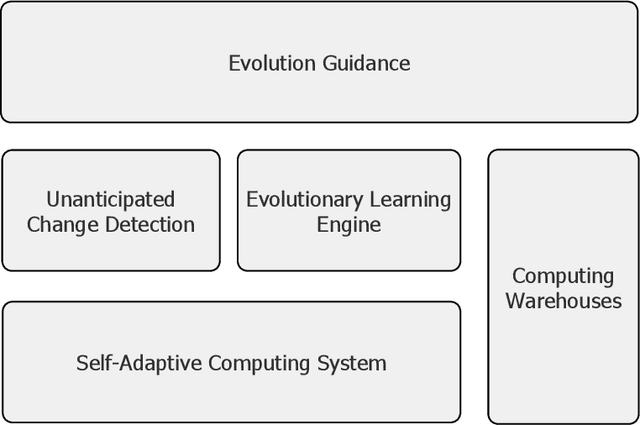
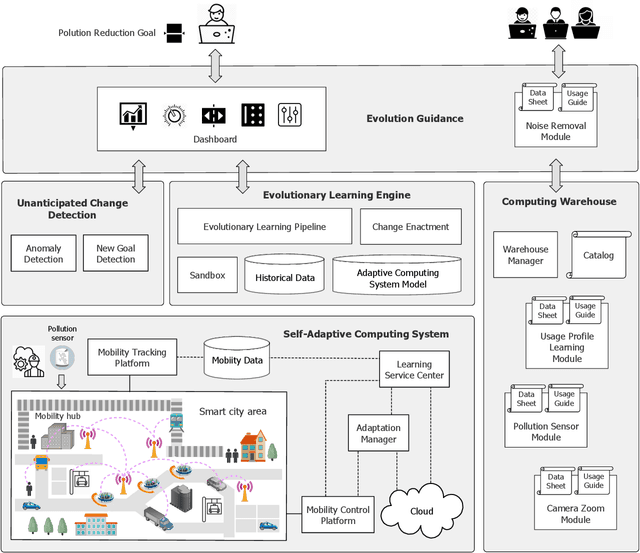
Computing systems are omnipresent; their sustainability has become crucial for our society. A key aspect of this sustainability is the ability of computing systems to cope with the continuous change they face, ranging from dynamic operating conditions, to changing goals, and technological progress. While we are able to engineer smart computing systems that autonomously deal with various types of changes, handling unanticipated changes requires system evolution, which remains in essence a human-centered process. This will eventually become unmanageable. To break through the status quo, we put forward an arguable opinion for the vision of self-evolving computing systems that are equipped with an evolutionary engine enabling them to evolve autonomously. Specifically, when a self-evolving computing system detects conditions outside its operational domain, such as an anomaly or a new goal, it activates an evolutionary engine that runs online experiments to determine how the system needs to evolve to deal with the changes, thereby evolving its architecture. During this process the engine can integrate new computing elements that are provided by computing warehouses. These computing elements provide specifications and procedures enabling their automatic integration. We motivate the need for self-evolving computing systems in light of the state of the art, outline a conceptual architecture of self-evolving computing systems, and illustrate the architecture for a future smart city mobility system that needs to evolve continuously with changing conditions. To conclude, we highlight key research challenges to realize the vision of self-evolving computing systems.
Lifelong Computing
Aug 19, 2021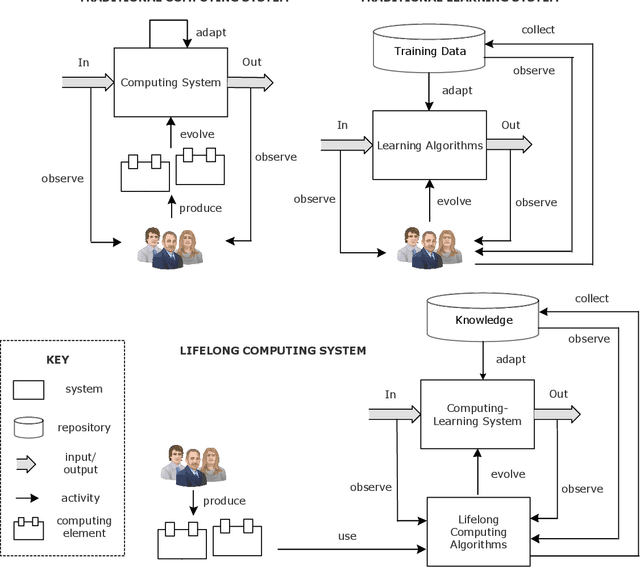
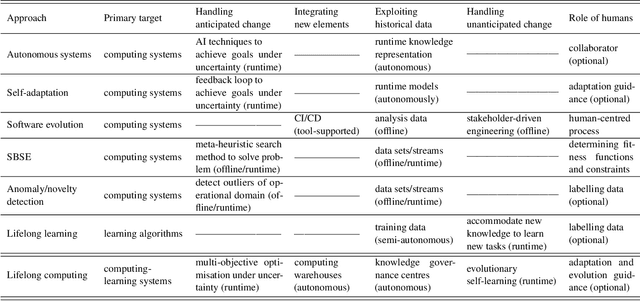
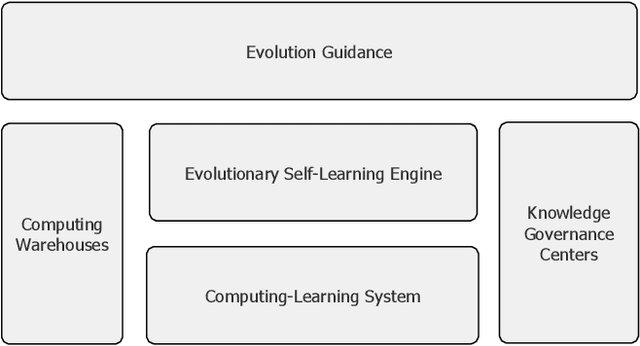
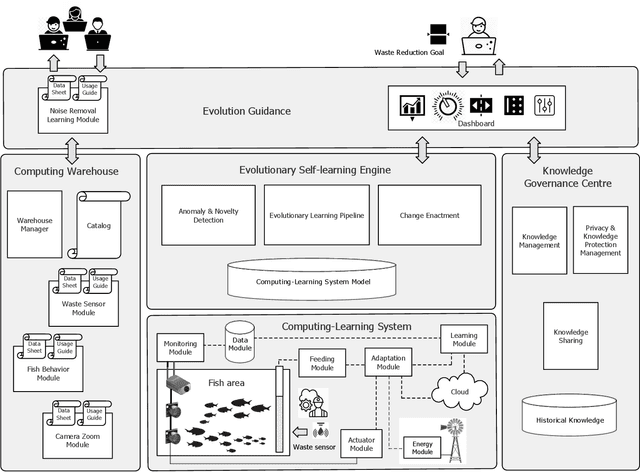
Computing systems form the backbone of many aspects of our life, hence they are becoming as vital as water, electricity, and road infrastructures for our society. Yet, engineering long running computing systems that achieve their goals in ever-changing environments pose significant challenges. Currently, we can build computing systems that adjust or learn over time to match changes that were anticipated. However, dealing with unanticipated changes, such as anomalies, novelties, new goals or constraints, requires system evolution, which remains in essence a human-driven activity. Given the growing complexity of computing systems and the vast amount of highly complex data to process, this approach will eventually become unmanageable. To break through the status quo, we put forward a new paradigm for the design and operation of computing systems that we coin "lifelong computing." The paradigm starts from computing-learning systems that integrate computing/service modules and learning modules. Computing warehouses offer such computing elements together with data sheets and usage guides. When detecting anomalies, novelties, new goals or constraints, a lifelong computing system activates an evolutionary self-learning engine that runs online experiments to determine how the computing-learning system needs to evolve to deal with the changes, thereby changing its architecture and integrating new computing elements from computing warehouses as needed. Depending on the domain at hand, some activities of lifelong computing systems can be supported by humans. We motivate the need for lifelong computing with a future fish farming scenario, outline a blueprint architecture for lifelong computing systems, and highlight key research challenges to realise the vision of lifelong computing.