 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Unboundedness in Quadratically-Constrained Mixed-Integer Problems
May 06, 2024
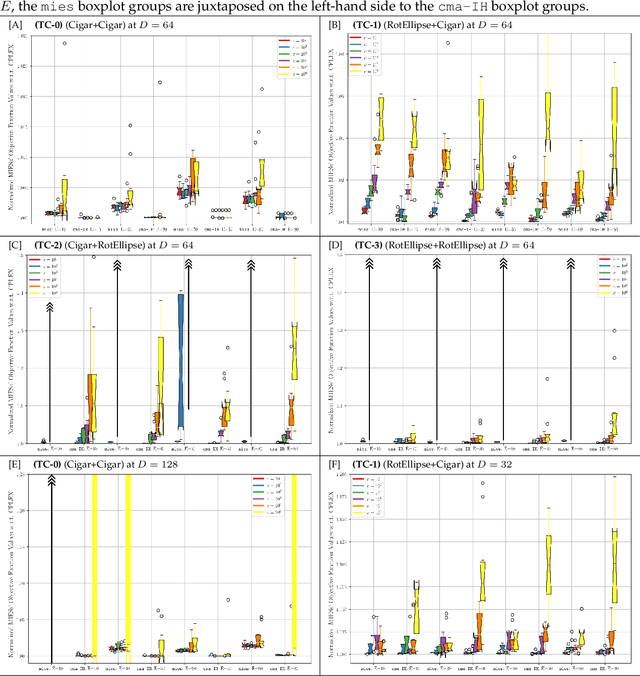
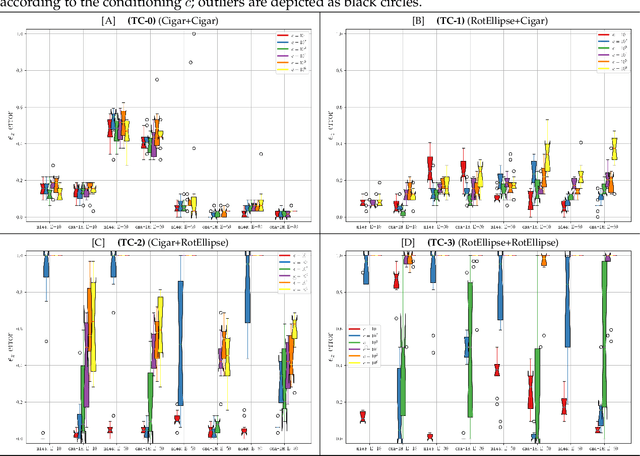
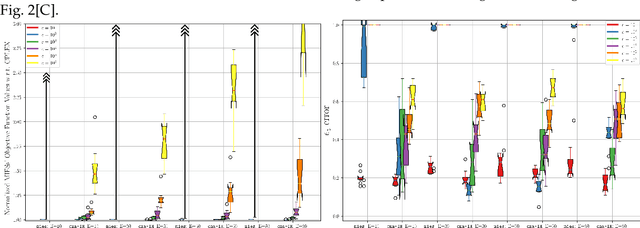
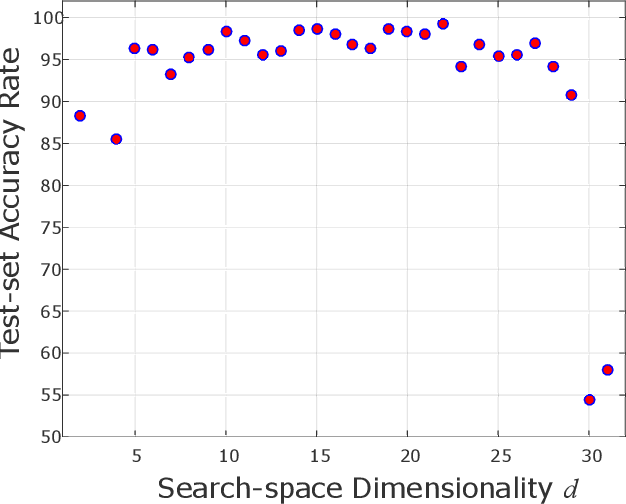
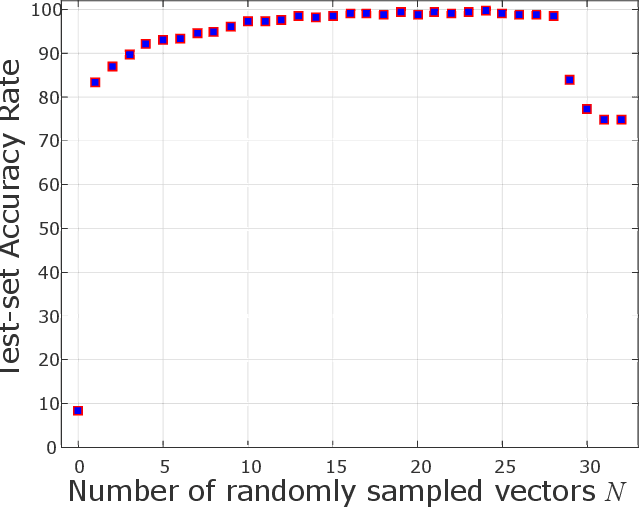
Quadratically-constrained unbounded integer programs hold the distinction of being undecidable, suggesting a possible soft-spot for Mathematical Programming (MP) techniques, which otherwise constitute a good choice to treat integer or mixed-integer (MI) problems. We consider the challenge of minimizing MI convex quadratic objective functions subject to unbounded decision variables and quadratic constraints. Given the theoretical weakness of white-box MP solvers to handle such models, we turn to black-box meta-heuristics of the Evolution Strategies (ESs) family, and question their capacity to solve this challenge. Through an empirical assessment of quadratically-constrained quadratic objective functions, across varying Hessian forms and condition numbers, we compare the performance of the CPLEX solver to state-of-the-art MI ESs, which handle constraints by penalty. Our systematic investigation begins where the CPLEX solver encounters difficulties (timeouts as the search-space dimensionality increases, (D>=30), on which we report by means of detailed analyses. Overall, the empirical observations confirm that black-box and white-box solvers can be competitive, especially when the constraint function is separable, and that two common ESs' mutation operators can effectively handle the integer unboundedness. We also conclude that conditioning and separability are not intuitive factors in determining the complexity of this class of MI problems, where regular versus rough landscape structures can pose mirrored degrees of challenge for MP versus ESs.
Avoiding Redundant Restarts in Multimodal Global Optimization
May 02, 2024Na\"ive restarts of global optimization solvers when operating on multimodal search landscapes may resemble the Coupon's Collector Problem, with a potential to waste significant function evaluations budget on revisiting the same basins of attractions. In this paper, we assess the degree to which such ``duplicate restarts'' occur on standard multimodal benchmark functions, which defines the \textit{redundancy potential} of each particular landscape. We then propose a repelling mechanism to avoid such wasted restarts with the CMA-ES and investigate its efficacy on test cases with high redundancy potential compared to the standard restart mechanism.
Lessons Learned Report: Super-Resolution for Detection Tasks in Engineering Problem-Solving
Mar 01, 2023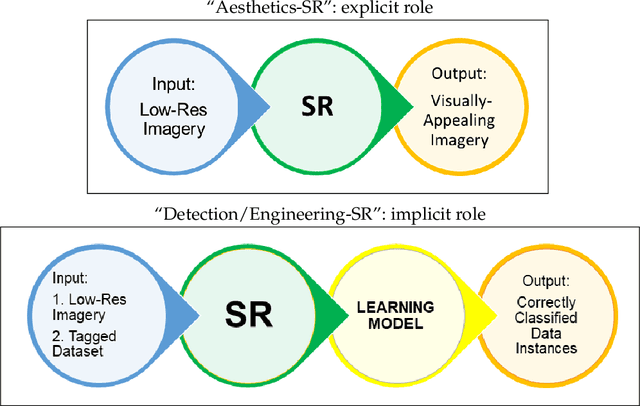
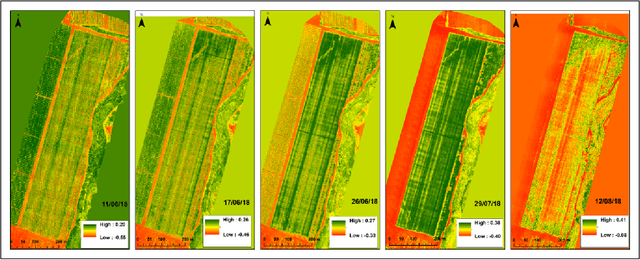
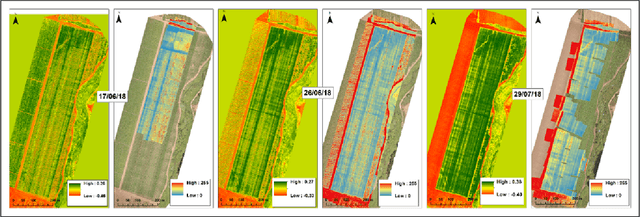

We describe the lessons learned from targeting agricultural detection problem-solving, when subject to low resolution input maps, by means of Machine Learning-based super-resolution approaches. The underlying domain is the so-called agro-detection class of problems, and the specific objective is to learn a complementary ensemble of sporadic input maps. While super-resolution algorithms are branded with the capacity to enhance various attractive features in generic photography, we argue that they must meet certain requirements, and more importantly, that their outcome does not necessarily guarantee an improvement in engineering detection problem-solving (unlike so-called aesthetics/artistic super-resolution in ImageNet-like datasets). By presenting specific data-driven case studies, we outline a set of limitations and recommendations for deploying super-resolution algorithms for agro-detection problems. Another conclusion states that super-resolution algorithms can be used for learning missing spectral channels, and that their usage may result in some desired side-effects such as channels' synchronization.
Saliency Can Be All You Need In Contrastive Self-Supervised Learning
Oct 30, 2022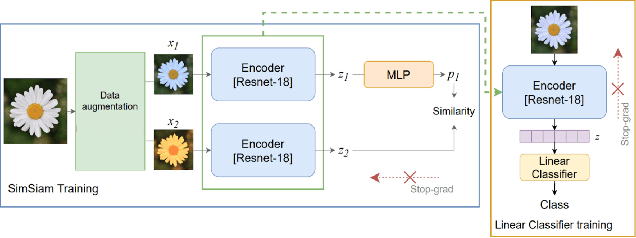


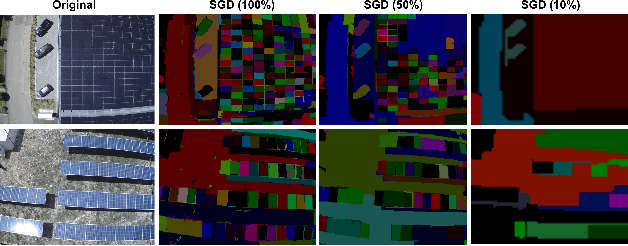
We propose an augmentation policy for Contrastive Self-Supervised Learning (SSL) in the form of an already established Salient Image Segmentation technique entitled Global Contrast based Salient Region Detection. This detection technique, which had been devised for unrelated Computer Vision tasks, was empirically observed to play the role of an augmentation facilitator within the SSL protocol. This observation is rooted in our practical attempts to learn, by SSL-fashion, aerial imagery of solar panels, which exhibit challenging boundary patterns. Upon the successful integration of this technique on our problem domain, we formulated a generalized procedure and conducted a comprehensive, systematic performance assessment with various Contrastive SSL algorithms subject to standard augmentation techniques. This evaluation, which was conducted across multiple datasets, indicated that the proposed technique indeed contributes to SSL. We hypothesize whether salient image segmentation may suffice as the only augmentation policy in Contrastive SSL when treating downstream segmentation tasks.
Toward an ImageNet Library of Functions for Global Optimization Benchmarking
Jun 27, 2022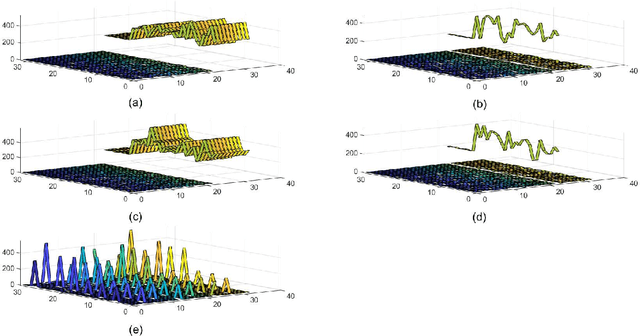
Knowledge of search-landscape features of BlackBox Optimization (BBO) problems offers valuable information in light of the Algorithm Selection and/or Configuration problems. Exploratory Landscape Analysis (ELA) models have gained success in identifying predefined human-derived features and in facilitating portfolio selectors to address those challenges. Unlike ELA approaches, the current study proposes to transform the identification problem into an image recognition problem, with a potential to detect conception-free, machine-driven landscape features. To this end, we introduce the notion of Landscape Images, which enables us to generate imagery instances per a benchmark function, and then target the classification challenge over a diverse generalized dataset of functions. We address it as a supervised multi-class image recognition problem and apply basic artificial neural network models to solve it. The efficacy of our approach is numerically validated on the noise free BBOB and IOHprofiler benchmarking suites. This evident successful learning is another step toward automated feature extraction and local structure deduction of BBO problems. By using this definition of landscape images, and by capitalizing on existing capabilities of image recognition algorithms, we foresee the construction of an ImageNet-like library of functions for training generalized detectors that rely on machine-driven features.
The Unreasonable Effectiveness of the Final Batch Normalization Layer
Sep 18, 2021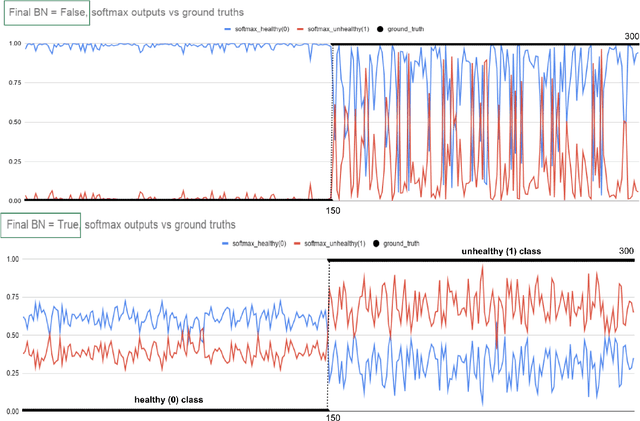


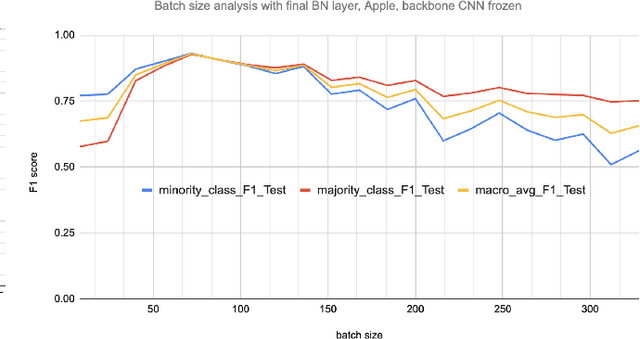
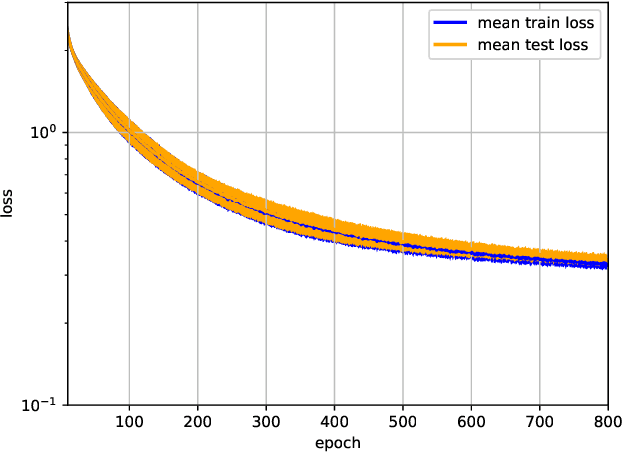
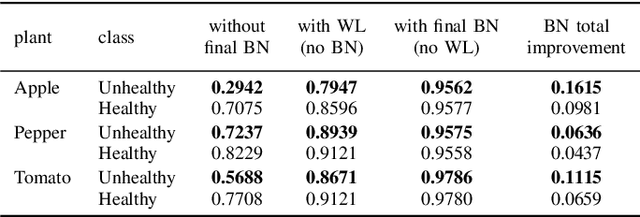
Early-stage disease indications are rarely recorded in real-world domains, such as Agriculture and Healthcare, and yet, their accurate identification is critical in that point of time. In this type of highly imbalanced classification problems, which encompass complex features, deep learning (DL) is much needed because of its strong detection capabilities. At the same time, DL is observed in practice to favor majority over minority classes and consequently suffer from inaccurate detection of the targeted early-stage indications. In this work, we extend the study done by Kocaman et al., 2020, showing that the final BN layer, when placed before the softmax output layer, has a considerable impact in highly imbalanced image classification problems as well as undermines the role of the softmax outputs as an uncertainty measure. This current study addresses additional hypotheses and reports on the following findings: (i) the performance gain after adding the final BN layer in highly imbalanced settings could still be achieved after removing this additional BN layer in inference; (ii) there is a certain threshold for the imbalance ratio upon which the progress gained by the final BN layer reaches its peak; (iii) the batch size also plays a role and affects the outcome of the final BN application; (iv) the impact of the BN application is also reproducible on other datasets and when utilizing much simpler neural architectures; (v) the reported BN effect occurs only per a single majority class and multiple minority classes i.e., no improvements are evident when there are two majority classes; and finally, (vi) utilizing this BN layer with sigmoid activation has almost no impact when dealing with a strongly imbalanced image classification tasks.
Addressing the Multiplicity of Solutions in Optical Lens Design as a Niching Evolutionary Algorithms Computational Challenge
May 21, 2021



Optimal Lens Design constitutes a fundamental, long-standing real-world optimization challenge. Potentially large number of optima, rich variety of critical points, as well as solid understanding of certain optimal designs per simple problem instances, provide altogether the motivation to address it as a niching challenge. This study applies established Niching-CMA-ES heuristic to tackle this design problem (6-dimensional Cooke triplet) in a simulation-based fashion. The outcome of employing Niching-CMA-ES `out-of-the-box' proves successful, and yet it performs best when assisted by a local searcher which accurately drives the search into optima. The obtained search-points are corroborated based upon concrete knowledge of this problem-instance, accompanied by gradient and Hessian calculations for validation. We extensively report on this computational campaign, which overall resulted in (i) the location of 19 out of 21 known minima within a single run, (ii) the discovery of 540 new optima. These are new minima similar in shape to 21 theoretical solutions, but some of them have better merit function value (unknown heretofore), (iii) the identification of numerous infeasibility pockets throughout the domain (also unknown heretofore). We conclude that niching mechanism is well-suited to address this problem domain, and hypothesize on the apparent multidimensional structures formed by the attained new solutions.
Improving Model Accuracy for Imbalanced Image Classification Tasks by Adding a Final Batch Normalization Layer: An Empirical Study
Nov 12, 2020
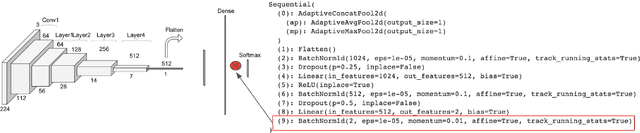
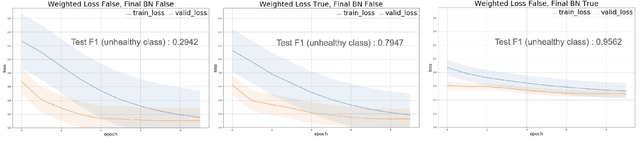
Some real-world domains, such as Agriculture and Healthcare, comprise early-stage disease indications whose recording constitutes a rare event, and yet, whose precise detection at that stage is critical. In this type of highly imbalanced classification problems, which encompass complex features, deep learning (DL) is much needed because of its strong detection capabilities. At the same time, DL is observed in practice to favor majority over minority classes and consequently suffer from inaccurate detection of the targeted early-stage indications. To simulate such scenarios, we artificially generate skewness (99% vs. 1%) for certain plant types out of the PlantVillage dataset as a basis for classification of scarce visual cues through transfer learning. By randomly and unevenly picking healthy and unhealthy samples from certain plant types to form a training set, we consider a base experiment as fine-tuning ResNet34 and VGG19 architectures and then testing the model performance on a balanced dataset of healthy and unhealthy images. We empirically observe that the initial F1 test score jumps from 0.29 to 0.95 for the minority class upon adding a final Batch Normalization (BN) layer just before the output layer in VGG19. We demonstrate that utilizing an additional BN layer before the output layer in modern CNN architectures has a considerable impact in terms of minimizing the training time and testing error for minority classes in highly imbalanced data sets. Moreover, when the final BN is employed, minimizing the loss function may not be the best way to assure a high F1 test score for minority classes in such problems. That is, the network might perform better even if it is not confident enough while making a prediction; leading to another discussion about why softmax output is not a good uncertainty measure for DL models.
Multi-Level Evolution Strategies for High-Resolution Black-Box Control
Oct 04, 2020
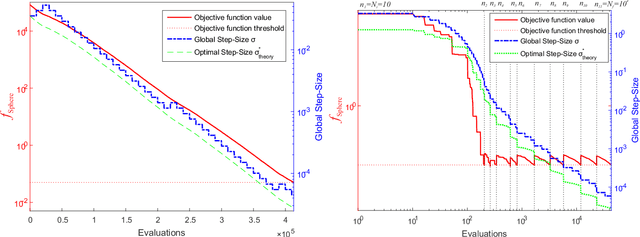
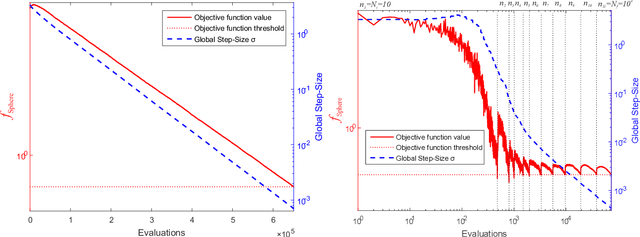

This paper introduces a multi-level (m-lev) mechanism into Evolution Strategies (ESs) in order to address a class of global optimization problems that could benefit from fine discretization of their decision variables. Such problems arise in engineering and scientific applications, which possess a multi-resolution control nature, and thus may be formulated either by means of low-resolution variants (providing coarser approximations with presumably lower accuracy for the general problem) or by high-resolution controls. A particular scientific application concerns practical Quantum Control (QC) problems, whose targeted optimal controls may be discretized to increasingly higher resolution, which in turn carries the potential to obtain better control yields. However, state-of-the-art derivative-free optimization heuristics for high-resolution formulations nominally call for an impractically large number of objective function calls. Therefore, an effective algorithmic treatment for such problems is needed. We introduce a framework with an automated scheme to facilitate guided-search over increasingly finer levels of control resolution for the optimization problem, whose on-the-fly learned parameters require careful adaptation. We instantiate the proposed m-lev self-adaptive ES framework by two specific strategies, namely the classical elitist single-child (1+1)-ES and the non-elitist multi-child derandomized $(\mu_W,\lambda)$-sep-CMA-ES. We first show that the approach is suitable by simulation-based optimization of QC systems which were heretofore viewed as too complex to address. We also present a laboratory proof-of-concept for the proposed approach on a basic experimental QC system objective.
Benchmarking Discrete Optimization Heuristics with IOHprofiler
Dec 19, 2019
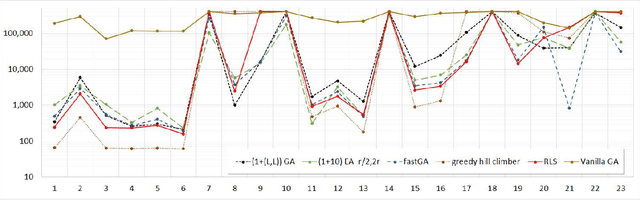
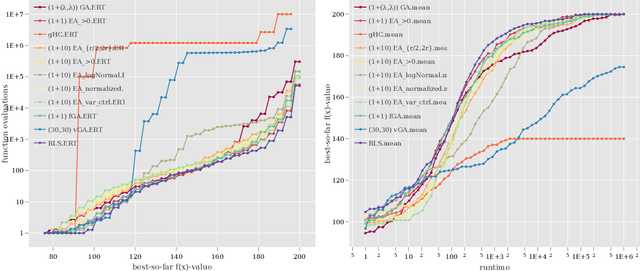

Automated benchmarking environments aim to support researchers in understanding how different algorithms perform on different types of optimization problems. Such comparisons provide insights into the strengths and weaknesses of different approaches, which can be leveraged into designing new algorithms and into the automation of algorithm selection and configuration. With the ultimate goal to create a meaningful benchmark set for iterative optimization heuristics, we have recently released IOHprofiler, a software built to create detailed performance comparisons between iterative optimization heuristics. With this present work we demonstrate that IOHprofiler provides a suitable environment for automated benchmarking. We compile and assess a selection of 23 discrete optimization problems that subscribe to different types of fitness landscapes. For each selected problem we compare performances of twelve different heuristics, which are as of now available as baseline algorithms in IOHprofiler. We also provide a new module for IOHprofiler which extents the fixed-target and fixed-budget results for the individual problems by ECDF results, which allows one to derive aggregated performance statistics for groups of problems.