 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCGP++ : A Modern C++ Implementation of Cartesian Genetic Programming
Jun 13, 2024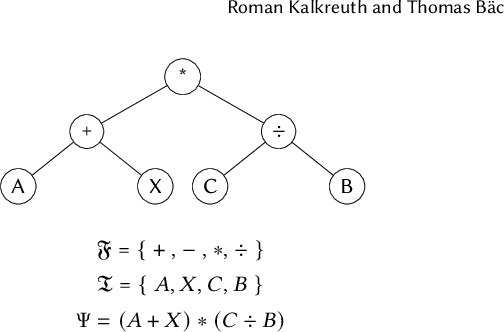
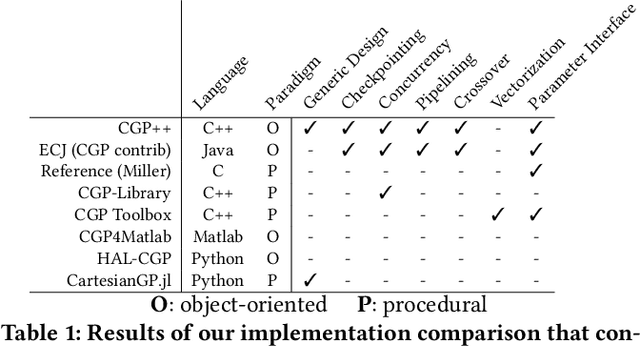
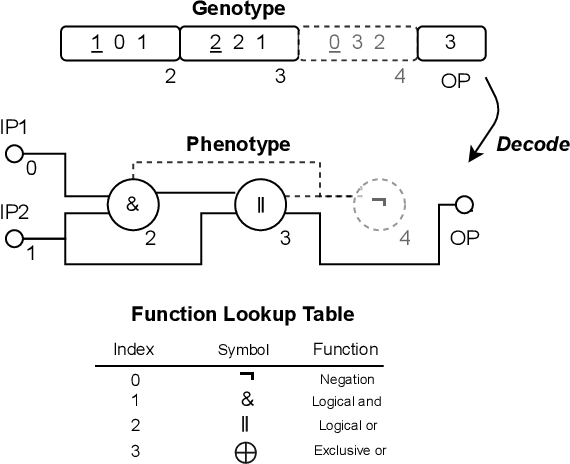

The reference implementation of Cartesian Genetic Programming (CGP) was written in the C programming language. C inherently follows a procedural programming paradigm, which entails challenges in providing a reusable and scalable implementation model for complex structures and methods. Moreover, due to the limiting factors of C, the reference implementation of CGP does not provide a generic framework and is therefore restricted to a set of predefined evaluation types. Besides the reference implementation, we also observe that other existing implementations are limited with respect to the features provided. In this work, we therefore propose the first version of a modern C++ implementation of CGP that pursues object-oriented design and generic programming paradigm to provide an efficient implementation model that can facilitate the discovery of new problem domains and the implementation of complex advanced methods that have been proposed for CGP over time. With the proposal of our new implementation, we aim to generally promote interpretability, accessibility and reproducibility in the field of CGP.
Clustering-based Domain-Incremental Learning
Sep 21, 2023



We consider the problem of learning multiple tasks in a continual learning setting in which data from different tasks is presented to the learner in a streaming fashion. A key challenge in this setting is the so-called "catastrophic forgetting problem", in which the performance of the learner in an "old task" decreases when subsequently trained on a "new task". Existing continual learning methods, such as Averaged Gradient Episodic Memory (A-GEM) and Orthogonal Gradient Descent (OGD), address catastrophic forgetting by minimizing the loss for the current task without increasing the loss for previous tasks. However, these methods assume the learner knows when the task changes, which is unrealistic in practice. In this paper, we alleviate the need to provide the algorithm with information about task changes by using an online clustering-based approach on a dynamically updated finite pool of samples or gradients. We thereby successfully counteract catastrophic forgetting in one of the hardest settings, namely: domain-incremental learning, a setting for which the problem was previously unsolved. We showcase the benefits of our approach by applying these ideas to projection-based methods, such as A-GEM and OGD, which lead to task-agnostic versions of them. Experiments on real datasets demonstrate the effectiveness of the proposed strategy and its promising performance compared to state-of-the-art methods.
The Vision of Self-Evolving Computing Systems
Apr 14, 2022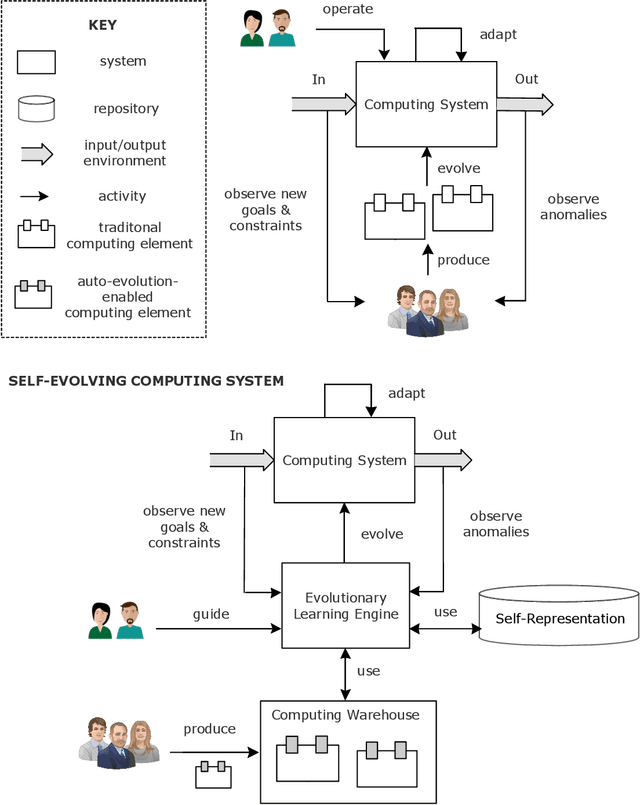
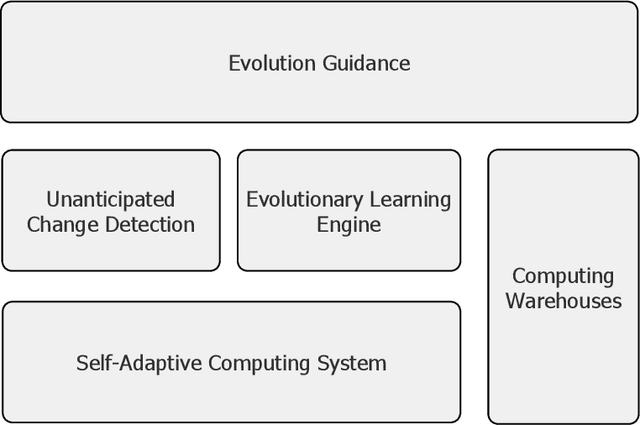
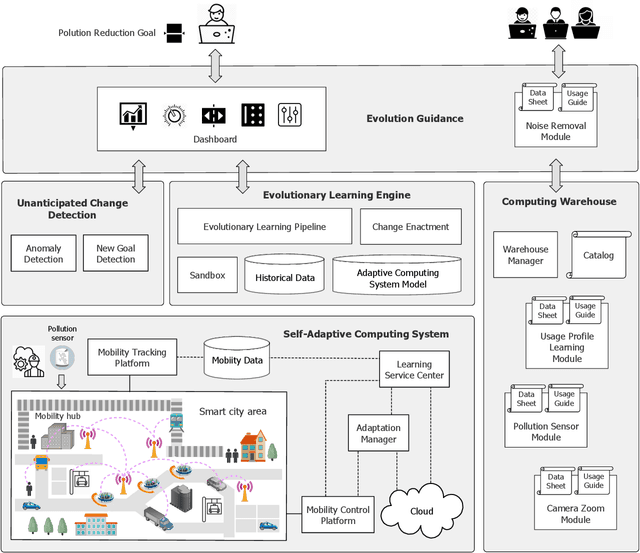
Computing systems are omnipresent; their sustainability has become crucial for our society. A key aspect of this sustainability is the ability of computing systems to cope with the continuous change they face, ranging from dynamic operating conditions, to changing goals, and technological progress. While we are able to engineer smart computing systems that autonomously deal with various types of changes, handling unanticipated changes requires system evolution, which remains in essence a human-centered process. This will eventually become unmanageable. To break through the status quo, we put forward an arguable opinion for the vision of self-evolving computing systems that are equipped with an evolutionary engine enabling them to evolve autonomously. Specifically, when a self-evolving computing system detects conditions outside its operational domain, such as an anomaly or a new goal, it activates an evolutionary engine that runs online experiments to determine how the system needs to evolve to deal with the changes, thereby evolving its architecture. During this process the engine can integrate new computing elements that are provided by computing warehouses. These computing elements provide specifications and procedures enabling their automatic integration. We motivate the need for self-evolving computing systems in light of the state of the art, outline a conceptual architecture of self-evolving computing systems, and illustrate the architecture for a future smart city mobility system that needs to evolve continuously with changing conditions. To conclude, we highlight key research challenges to realize the vision of self-evolving computing systems.
The Unreasonable Effectiveness of the Final Batch Normalization Layer
Sep 18, 2021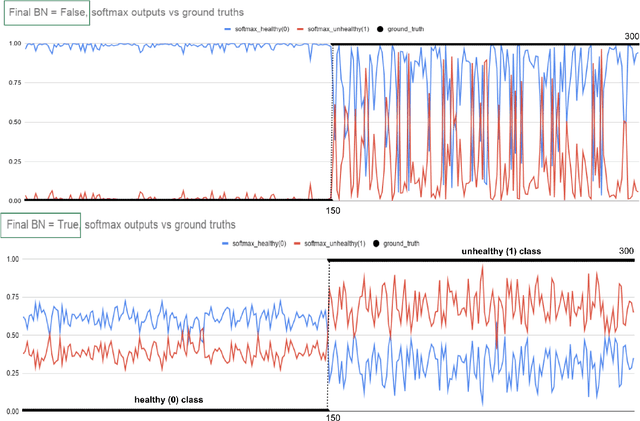


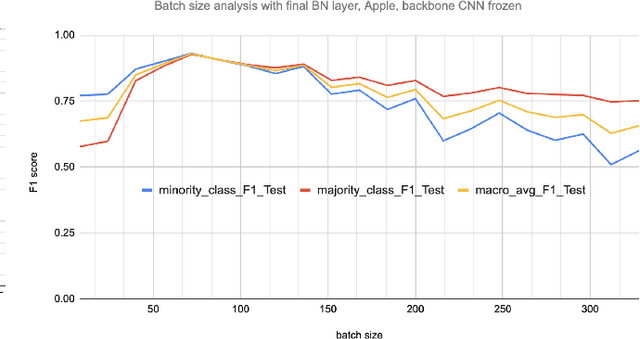
Early-stage disease indications are rarely recorded in real-world domains, such as Agriculture and Healthcare, and yet, their accurate identification is critical in that point of time. In this type of highly imbalanced classification problems, which encompass complex features, deep learning (DL) is much needed because of its strong detection capabilities. At the same time, DL is observed in practice to favor majority over minority classes and consequently suffer from inaccurate detection of the targeted early-stage indications. In this work, we extend the study done by Kocaman et al., 2020, showing that the final BN layer, when placed before the softmax output layer, has a considerable impact in highly imbalanced image classification problems as well as undermines the role of the softmax outputs as an uncertainty measure. This current study addresses additional hypotheses and reports on the following findings: (i) the performance gain after adding the final BN layer in highly imbalanced settings could still be achieved after removing this additional BN layer in inference; (ii) there is a certain threshold for the imbalance ratio upon which the progress gained by the final BN layer reaches its peak; (iii) the batch size also plays a role and affects the outcome of the final BN application; (iv) the impact of the BN application is also reproducible on other datasets and when utilizing much simpler neural architectures; (v) the reported BN effect occurs only per a single majority class and multiple minority classes i.e., no improvements are evident when there are two majority classes; and finally, (vi) utilizing this BN layer with sigmoid activation has almost no impact when dealing with a strongly imbalanced image classification tasks.
Automatic Preference Based Multi-objective Evolutionary Algorithm on Vehicle Fleet Maintenance Scheduling Optimization
Jan 23, 2021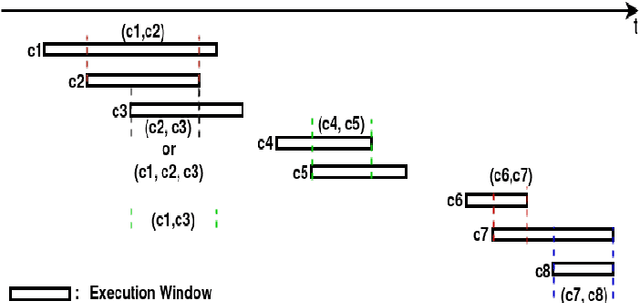
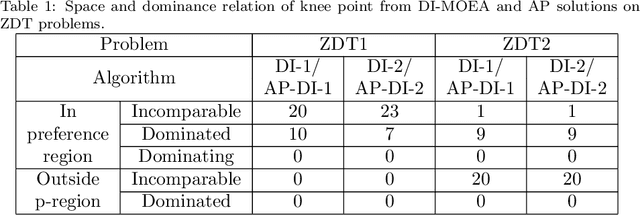
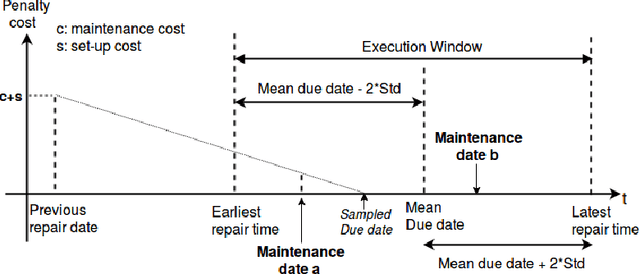
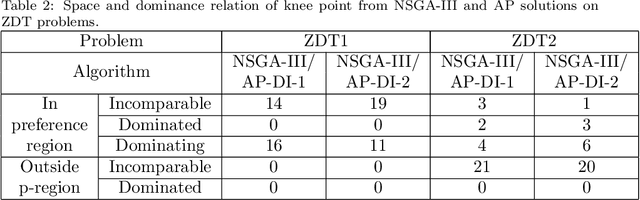
A preference based multi-objective evolutionary algorithm is proposed for generating solutions in an automatically detected knee point region. It is named Automatic Preference based DI-MOEA (AP-DI-MOEA) where DI-MOEA stands for Diversity-Indicator based Multi-Objective Evolutionary Algorithm). AP-DI-MOEA has two main characteristics: firstly, it generates the preference region automatically during the optimization; secondly, it concentrates the solution set in this preference region. Moreover, the real-world vehicle fleet maintenance scheduling optimization (VFMSO) problem is formulated, and a customized multi-objective evolutionary algorithm (MOEA) is proposed to optimize maintenance schedules of vehicle fleets based on the predicted failure distribution of the components of cars. Furthermore, the customized MOEA for VFMSO is combined with AP-DI-MOEA to find maintenance schedules in the automatically generated preference region. Experimental results on multi-objective benchmark problems and our three-objective real-world application problems show that the newly proposed algorithm can generate the preference region accurately and that it can obtain better solutions in the preference region. Especially, in many cases, under the same budget, the Pareto optimal solutions obtained by AP-DI-MOEA dominate solutions obtained by MOEAs that pursue the entire Pareto front.