 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective-Induced Bias and Search Dynamics in Multiobjective Unsupervised Feature Selection
May 20, 2026Unsupervised feature selection is commonly formulated as a multiobjective optimisation problem that jointly optimises subset quality and subset size. Yet the behaviour of this formulation depends critically on the choice of evaluation objective, the direction of subset-size regularisation, and the initialisation strategy. We study these factors in a controlled setting using a synthetic dataset with known informative, redundant, and irrelevant feature types. Six formulations are compared by combining three evaluation objectives: accuracy, silhouette score, and PCA reconstruction loss with subset-size minimisation or maximisation. The results show that formulation strongly affects both search dynamics and the quality of the resulting Pareto front. Silhouette-based formulations exhibit a strong bias toward trivial low-cardinality solutions and remain weak proxies for predictive performance. In contrast, the proposed PCA loss objective produces compact subsets with test accuracy comparable to subsets obtained by directly optimising supervised accuracy. Overall, the study shows that objective design is central to effective multiobjective unsupervised feature selection.
Benefits of Low-Cost Bio-Inspiration in the Age of Overparametrization
Apr 22, 2026While Central Pattern Generators (CPGs) and Multi-Layer Perceptrons (MLP) are widely used paradigms in robot control, few systematic studies have been performed on the relative merits of large parameter spaces. In contexts where input and output spaces are small and performance is bounded, having more parameters to optimize may actively hinder the learning process instead of empowering it. To empirically measure this, we submit a given robot morphology, with limited proprioceptive capabilities, to controller optimization under two bio-inspired paradigms (CPGs and MLPs) with evolutionary- and reinforcement- trainer protocols. By varying parameter spaces across multiple reward functions, we observe that shallow MLPs and densely connected CPGs result in better performance when compared to deeper MLPs or Actor-Critic architectures. To account for the relationship between said performance and the number of parameters, we introduce a Parameter Impact metric which demonstrates that the additional parameters required by the reinforcement technique do not translate into better performance, thus favouring evolutionary strategies.
Multi-Agent Influence Diagrams to Hybrid Threat Modeling
Mar 03, 2026Western governments have adopted an assortment of counter-hybrid threat measures to defend against hostile actions below the conventional military threshold. The impact of these measures is unclear because of the ambiguity of hybrid threats, their cross-domain nature, and uncertainty about how countermeasures shape adversarial behavior. This paper offers a novel approach to clarifying this impact by unifying previously bifurcating hybrid threat modeling methods through a (multi-agent) influence diagram framework. The model balances the costs of countermeasures, their ability to dissuade the adversary from executing hybrid threats, and their potential to mitigate the impact of hybrid threats. We run 1000 semi-synthetic variants of a real-world-inspired scenario simulating the strategic interaction between attacking agent A and defending agent B over a cyber attack on critical infrastructure to explore the effectiveness of a set of five different counter-hybrid threat measures. Counter-hybrid measures range from strengthening resilience and denial of the adversary's ability to execute a hybrid threat to dissuasion through the threat of punishment. Our analysis primarily evaluates the overarching characteristics of counter-hybrid threat measures. This approach allows us to generalize the effectiveness of these measures and examine parameter impact sensitivity. In addition, we discuss policy relevance and outline future research avenues.
Structural bias in multi-objective optimisation
Feb 06, 2026Structural bias (SB) refers to systematic preferences of an optimisation algorithm for particular regions of the search space that arise independently of the objective function. While SB has been studied extensively in single-objective optimisation, its role in multi-objective optimisation remains largely unexplored. This is problematic, as dominance relations, diversity preservation and Pareto-based selection mechanisms may introduce or amplify structural effects. In this paper, we extend the concept of structural bias to the multi-objective setting and propose a methodology to study it in isolation from fitness-driven guidance. We introduce a suite of synthetic multi-objective test problems with analytically controlled Pareto fronts and deliberately uninformative objective values. These problems are designed to decouple algorithmic behaviour from problem structure, allowing bias induced purely by algorithmic operators and design choices to be observed. The test suite covers a range of Pareto front shapes, densities and noise levels, enabling systematic analysis of different manifestations of structural bias. We discuss methodological challenges specific to the multi-objective case and outline how existing SB detection approaches can be adapted. This work provides a first step towards behaviour-based benchmarking of multi-objective optimisers, complementing performance-based evaluation and informing more robust algorithm design.
Landscape-aware Automated Algorithm Design: An Efficient Framework for Real-world Optimization
Feb 04, 2026The advent of Large Language Models (LLMs) has opened new frontiers in automated algorithm design, giving rise to numerous powerful methods. However, these approaches retain critical limitations: they require extensive evaluation of the target problem to guide the search process, making them impractical for real-world optimization tasks, where each evaluation consumes substantial computational resources. This research proposes an innovative and efficient framework that decouples algorithm discovery from high-cost evaluation. Our core innovation lies in combining a Genetic Programming (GP) function generator with an LLM-driven evolutionary algorithm designer. The evolutionary direction of the GP-based function generator is guided by the similarity between the landscape characteristics of generated proxy functions and those of real-world problems, ensuring that algorithms discovered via proxy functions exhibit comparable performance on real-world problems. Our method enables deep exploration of the algorithmic space before final validation while avoiding costly real-world evaluations. We validated the framework's efficacy across multiple real-world problems, demonstrating its ability to discover high-performance algorithms while substantially reducing expensive evaluations. This approach shows a path to apply LLM-based automated algorithm design to computationally intensive real-world optimization challenges.
Lens-descriptor guided evolutionary algorithm for optimization of complex optical systems with glass choice
Jan 29, 2026Designing high-performance optical lenses entails exploring a high-dimensional, tightly constrained space of surface curvatures, glass choices, element thicknesses, and spacings. In practice, standard optimizers (e.g., gradient-based local search and evolutionary strategies) often converge to a single local optimum, overlooking many comparably good alternatives that matter for downstream engineering decisions. We propose the Lens Descriptor-Guided Evolutionary Algorithm (LDG-EA), a two-stage framework for multimodal lens optimization. LDG-EA first partitions the design space into behavior descriptors defined by curvature-sign patterns and material indices, then learns a probabilistic model over descriptors to allocate evaluations toward promising regions. Within each descriptor, LDG-EA applies the Hill-Valley Evolutionary Algorithm with covariance-matrix self-adaptation to recover multiple distinct local minima, optionally followed by gradient-based refinement. On a 24-variable (18 continuous and 6 integer), six-element Double-Gauss topology, LDG-EA generates on average around 14500 candidate minima spanning 636 unique descriptors, an order of magnitude more than a CMA-ES baseline, while keeping wall-clock time at one hour scale. Although the best LDG-EA design is slightly worse than a fine-tuned reference lens, it remains in the same performance range. Overall, the proposed LDG-EA produces a diverse set of solutions while maintaining competitive quality within practical computational budgets and wall-clock time.
LLaMEA-SAGE: Guiding Automated Algorithm Design with Structural Feedback from Explainable AI
Jan 29, 2026Large language models have enabled automated algorithm design (AAD) by generating optimization algorithms directly from natural-language prompts. While evolutionary frameworks such as LLaMEA demonstrate strong exploratory capabilities across the algorithm design space, their search dynamics are entirely driven by fitness feedback, leaving substantial information about the generated code unused. We propose a mechanism for guiding AAD using feedback constructed from graph-theoretic and complexity features extracted from the abstract syntax trees of the generated algorithms, based on a surrogate model learned over an archive of evaluated solutions. Using explainable AI techniques, we identify features that substantially affect performance and translate them into natural-language mutation instructions that steer subsequent LLM-based code generation without restricting expressivity. We propose LLaMEA-SAGE, which integrates this feature-driven guidance into LLaMEA, and evaluate it across several benchmarks. We show that the proposed structured guidance achieves the same performance faster than vanilla LLaMEA in a small controlled experiment. In a larger-scale experiment using the MA-BBOB suite from the GECCO-MA-BBOB competition, our guided approach achieves superior performance compared to state-of-the-art AAD methods. These results demonstrate that signals derived from code can effectively bias LLM-driven algorithm evolution, bridging the gap between code structure and human-understandable performance feedback in automated algorithm design.
Benchmarking that Matters: Rethinking Benchmarking for Practical Impact
Nov 15, 2025Benchmarking has driven scientific progress in Evolutionary Computation, yet current practices fall short of real-world needs. Widely used synthetic suites such as BBOB and CEC isolate algorithmic phenomena but poorly reflect the structure, constraints, and information limitations of continuous and mixed-integer optimization problems in practice. This disconnect leads to the misuse of benchmarking suites for competitions, automated algorithm selection, and industrial decision-making, despite these suites being designed for different purposes. We identify key gaps in current benchmarking practices and tooling, including limited availability of real-world-inspired problems, missing high-level features, and challenges in multi-objective and noisy settings. We propose a vision centered on curated real-world-inspired benchmarks, practitioner-accessible feature spaces and community-maintained performance databases. Real progress requires coordinated effort: A living benchmarking ecosystem that evolves with real-world insights and supports both scientific understanding and industrial use.
From Spikes to Speech: NeuroVoc -- A Biologically Plausible Vocoder Framework for Auditory Perception and Cochlear Implant Simulation
Jun 04, 2025



We present NeuroVoc, a flexible model-agnostic vocoder framework that reconstructs acoustic waveforms from simulated neural activity patterns using an inverse Fourier transform. The system applies straightforward signal processing to neurogram representations, time-frequency binned outputs from auditory nerve fiber models. Crucially, the model architecture is modular, allowing for easy substitution or modification of the underlying auditory models. This flexibility eliminates the need for speech-coding-strategy-specific vocoder implementations when simulating auditory perception in cochlear implant (CI) users. It also allows direct comparisons between normal hearing (NH) and electrical hearing (EH) models, as demonstrated in this study. The vocoder preserves distinctive features of each model; for example, the NH model retains harmonic structure more faithfully than the EH model. We evaluated perceptual intelligibility in noise using an online Digits-in-Noise (DIN) test, where participants completed three test conditions: one with standard speech, and two with vocoded speech using the NH and EH models. Both the standard DIN test and the EH-vocoded groups were statistically equivalent to clinically reported data for NH and CI listeners. On average, the NH and EH vocoded groups increased SRT compared to the standard test by 2.4 dB and 7.1 dB, respectively. These findings show that, although some degradation occurs, the vocoder can reconstruct intelligible speech under both hearing models and accurately reflects the reduced speech-in-noise performance experienced by CI users.
Towards a Deeper Understanding of Reasoning Capabilities in Large Language Models
May 15, 2025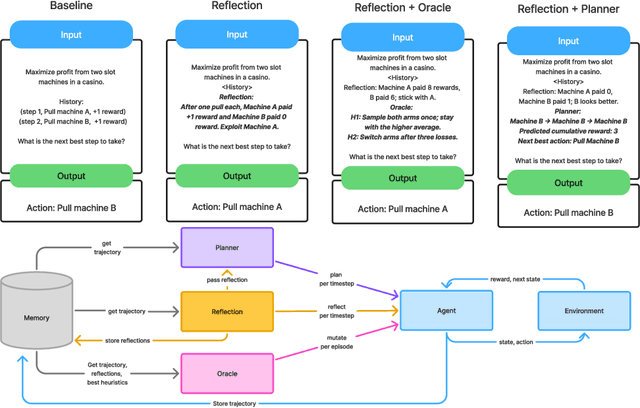
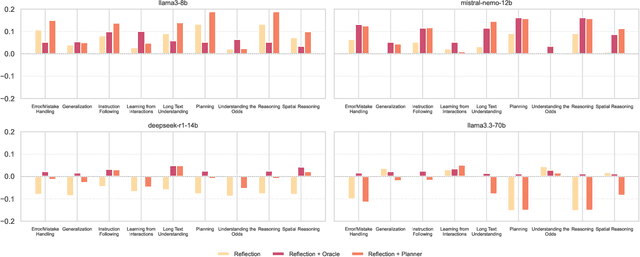
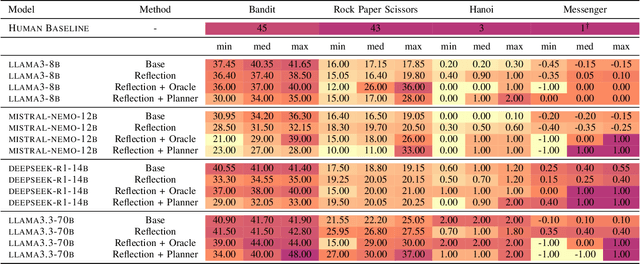
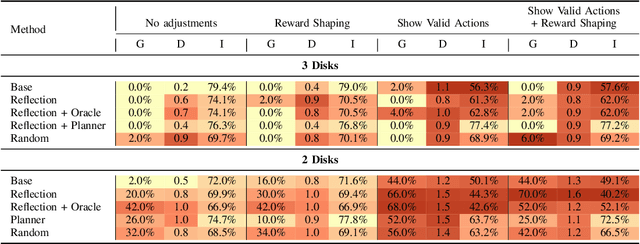
While large language models demonstrate impressive performance on static benchmarks, the true potential of large language models as self-learning and reasoning agents in dynamic environments remains unclear. This study systematically evaluates the efficacy of self-reflection, heuristic mutation, and planning as prompting techniques to test the adaptive capabilities of agents. We conduct experiments with various open-source language models in dynamic environments and find that larger models generally outperform smaller ones, but that strategic prompting can close this performance gap. Second, a too-long prompt can negatively impact smaller models on basic reactive tasks, while larger models show more robust behaviour. Third, advanced prompting techniques primarily benefit smaller models on complex games, but offer less improvement for already high-performing large language models. Yet, we find that advanced reasoning methods yield highly variable outcomes: while capable of significantly improving performance when reasoning and decision-making align, they also introduce instability and can lead to big performance drops. Compared to human performance, our findings reveal little evidence of true emergent reasoning. Instead, large language model performance exhibits persistent limitations in crucial areas such as planning, reasoning, and spatial coordination, suggesting that current-generation large language models still suffer fundamental shortcomings that may not be fully overcome through self-reflective prompting alone. Reasoning is a multi-faceted task, and while reasoning methods like Chain of thought improves multi-step reasoning on math word problems, our findings using dynamic benchmarks highlight important shortcomings in general reasoning capabilities, indicating a need to move beyond static benchmarks to capture the complexity of reasoning.