 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking that Matters: Rethinking Benchmarking for Practical Impact
Nov 15, 2025Benchmarking has driven scientific progress in Evolutionary Computation, yet current practices fall short of real-world needs. Widely used synthetic suites such as BBOB and CEC isolate algorithmic phenomena but poorly reflect the structure, constraints, and information limitations of continuous and mixed-integer optimization problems in practice. This disconnect leads to the misuse of benchmarking suites for competitions, automated algorithm selection, and industrial decision-making, despite these suites being designed for different purposes. We identify key gaps in current benchmarking practices and tooling, including limited availability of real-world-inspired problems, missing high-level features, and challenges in multi-objective and noisy settings. We propose a vision centered on curated real-world-inspired benchmarks, practitioner-accessible feature spaces and community-maintained performance databases. Real progress requires coordinated effort: A living benchmarking ecosystem that evolves with real-world insights and supports both scientific understanding and industrial use.
Algorithm Selection with Probing Trajectories: Benchmarking the Choice of Classifier Model
Jan 20, 2025Recent approaches to training algorithm selectors in the black-box optimisation domain have advocated for the use of training data that is algorithm-centric in order to encapsulate information about how an algorithm performs on an instance, rather than relying on information derived from features of the instance itself. Probing-trajectories that consist of a sequence of objective performance per function evaluation obtained from a short run of an algorithm have recently shown particular promise in training accurate selectors. However, training models on this type of data requires an appropriately chosen classifier given the sequential nature of the data. There are currently no clear guidelines for choosing the most appropriate classifier for algorithm selection using time-series data from the plethora of models available. To address this, we conduct a large benchmark study using 17 different classifiers and three types of trajectory on a classification task using the BBOB benchmark suite using both leave-one-instance out and leave-one-problem out cross-validation. In contrast to previous studies using tabular data, we find that the choice of classifier has a significant impact, showing that feature-based and interval-based models are the best choices.
Beyond the Hype: Benchmarking LLM-Evolved Heuristics for Bin Packing
Jan 20, 2025
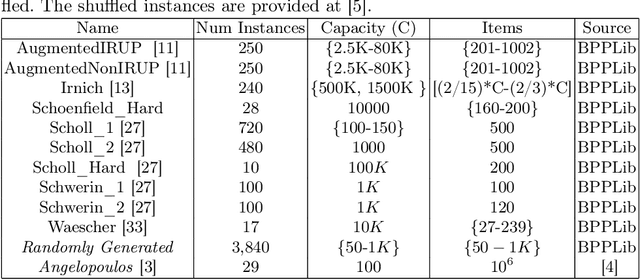
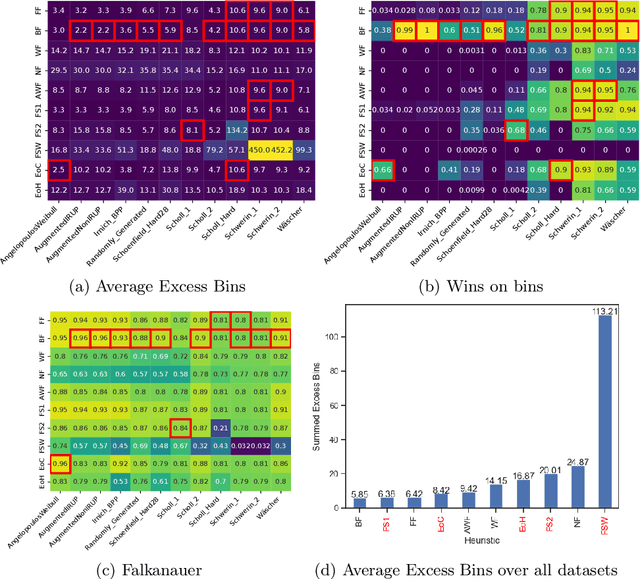
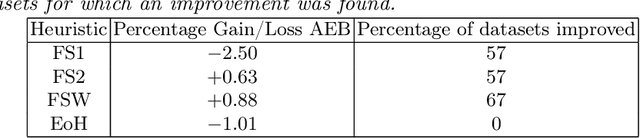
Coupling Large Language Models (LLMs) with Evolutionary Algorithms has recently shown significant promise as a technique to design new heuristics that outperform existing methods, particularly in the field of combinatorial optimisation. An escalating arms race is both rapidly producing new heuristics and improving the efficiency of the processes evolving them. However, driven by the desire to quickly demonstrate the superiority of new approaches, evaluation of the new heuristics produced for a specific domain is often cursory: testing on very few datasets in which instances all belong to a specific class from the domain, and on few instances per class. Taking bin-packing as an example, to the best of our knowledge we conduct the first rigorous benchmarking study of new LLM-generated heuristics, comparing them to well-known existing heuristics across a large suite of benchmark instances using three performance metrics. For each heuristic, we then evolve new instances won by the heuristic and perform an instance space analysis to understand where in the feature space each heuristic performs well. We show that most of the LLM heuristics do not generalise well when evaluated across a broad range of benchmarks in contrast to existing simple heuristics, and suggest that any gains from generating very specialist heuristics that only work in small areas of the instance space need to be weighed carefully against the considerable cost of generating these heuristics.
Stalling in Space: Attractor Analysis for any Algorithm
Dec 20, 2024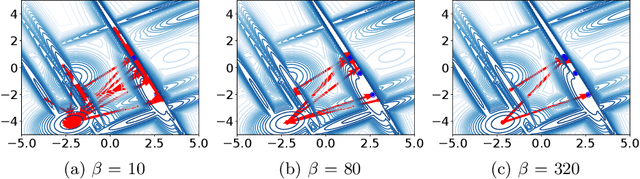

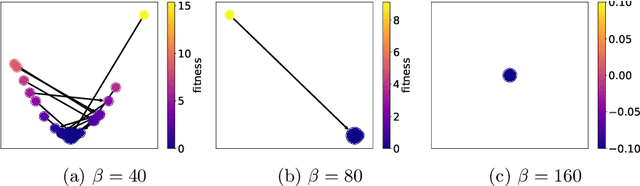

Network-based representations of fitness landscapes have grown in popularity in the past decade; this is probably because of growing interest in explainability for optimisation algorithms. Local optima networks (LONs) have been especially dominant in the literature and capture an approximation of local optima and their connectivity in the landscape. However, thus far, LONs have been constructed according to a strict definition of what a local optimum is: the result of local search. Many evolutionary approaches do not include this, however. Popular algorithms such as CMA-ES have therefore never been subject to LON analysis. Search trajectory networks (STNs) offer a possible alternative: nodes can be any search space location. However, STNs are not typically modelled in such a way that models temporal stalls: that is, a region in the search space where an algorithm fails to find a better solution over a defined period of time. In this work, we approach this by systematically analysing a special case of STN which we name attractor networks. These offer a coarse-grained view of algorithm behaviour with a singular focus on stall locations. We construct attractor networks for CMA-ES, differential evolution, and random search for 24 noiseless black-box optimisation benchmark problems. The properties of attractor networks are systematically explored. They are also visualised and compared to traditional LONs and STN models. We find that attractor networks facilitate insights into algorithm behaviour which other models cannot, and we advocate for the consideration of attractor analysis even for algorithms which do not include local search.
Evaluating the Robustness of Deep-Learning Algorithm-Selection Models by Evolving Adversarial Instances
Jun 24, 2024



Deep neural networks (DNN) are increasingly being used to perform algorithm-selection in combinatorial optimisation domains, particularly as they accommodate input representations which avoid designing and calculating features. Mounting evidence from domains that use images as input shows that deep convolutional networks are vulnerable to adversarial samples, in which a small perturbation of an instance can cause the DNN to misclassify. However, it remains unknown as to whether deep recurrent networks (DRN) which have recently been shown promise as algorithm-selectors in the bin-packing domain are equally vulnerable. We use an evolutionary algorithm (EA) to find perturbations of instances from two existing benchmarks for online bin packing that cause trained DRNs to misclassify: adversarial samples are successfully generated from up to 56% of the original instances depending on the dataset. Analysis of the new misclassified instances sheds light on the `fragility' of some training instances, i.e. instances where it is trivial to find a small perturbation that results in a misclassification and the factors that influence this. Finally, the method generates a large number of new instances misclassified with a wide variation in confidence, providing a rich new source of training data to create more robust models.
Identifying Easy Instances to Improve Efficiency of ML Pipelines for Algorithm-Selection
Jun 24, 2024


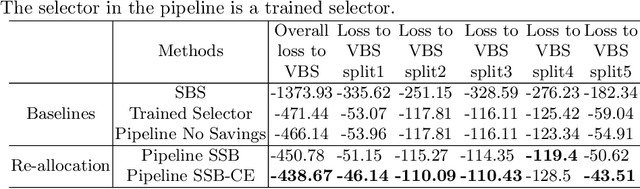
Algorithm-selection (AS) methods are essential in order to obtain the best performance from a portfolio of solvers over large sets of instances. However, many AS methods rely on an analysis phase, e.g. where features are computed by sampling solutions and used as input in a machine-learning model. For AS to be efficient, it is therefore important that this analysis phase is not computationally expensive. We propose a method for identifying easy instances which can be solved quickly using a generalist solver without any need for algorithm-selection. This saves computational budget associated with feature-computation which can then be used elsewhere in an AS pipeline, e.g., enabling additional function evaluations on hard problems. Experiments on the BBOB dataset in two settings (batch and streaming) show that identifying easy instances results in substantial savings in function evaluations. Re-allocating the saved budget to hard problems provides gains in performance compared to both the virtual best solver (VBS) computed with the original budget, the single best solver (SBS) and a trained algorithm-selector.
Improving Algorithm-Selection and Performance-Prediction via Learning Discriminating Training Samples
Apr 08, 2024



The choice of input-data used to train algorithm-selection models is recognised as being a critical part of the model success. Recently, feature-free methods for algorithm-selection that use short trajectories obtained from running a solver as input have shown promise. However, it is unclear to what extent these trajectories reliably discriminate between solvers. We propose a meta approach to generating discriminatory trajectories with respect to a portfolio of solvers. The algorithm-configuration tool irace is used to tune the parameters of a simple Simulated Annealing algorithm (SA) to produce trajectories that maximise the performance metrics of ML models trained on this data. We show that when the trajectories obtained from the tuned SA algorithm are used in ML models for algorithm-selection and performance prediction, we obtain significantly improved performance metrics compared to models trained both on raw trajectory data and on exploratory landscape features.
On the Utility of Probing Trajectories for Algorithm-Selection
Jan 23, 2024



Machine-learning approaches to algorithm-selection typically take data describing an instance as input. Input data can take the form of features derived from the instance description or fitness landscape, or can be a direct representation of the instance itself, i.e. an image or textual description. Regardless of the choice of input, there is an implicit assumption that instances that are similar will elicit similar performance from algorithm, and that a model is capable of learning this relationship. We argue that viewing algorithm-selection purely from an instance perspective can be misleading as it fails to account for how an algorithm `views' similarity between instances. We propose a novel `algorithm-centric' method for describing instances that can be used to train models for algorithm-selection: specifically, we use short probing trajectories calculated by applying a solver to an instance for a very short period of time. The approach is demonstrated to be promising, providing comparable or better results to computationally expensive landscape-based feature-based approaches. Furthermore, projecting the trajectories into a 2-dimensional space illustrates that functions that are similar from an algorithm-perspective do not necessarily correspond to the accepted categorisation of these functions from a human perspective.
Automated Algorithm Selection for Radar Network Configuration
May 07, 2022
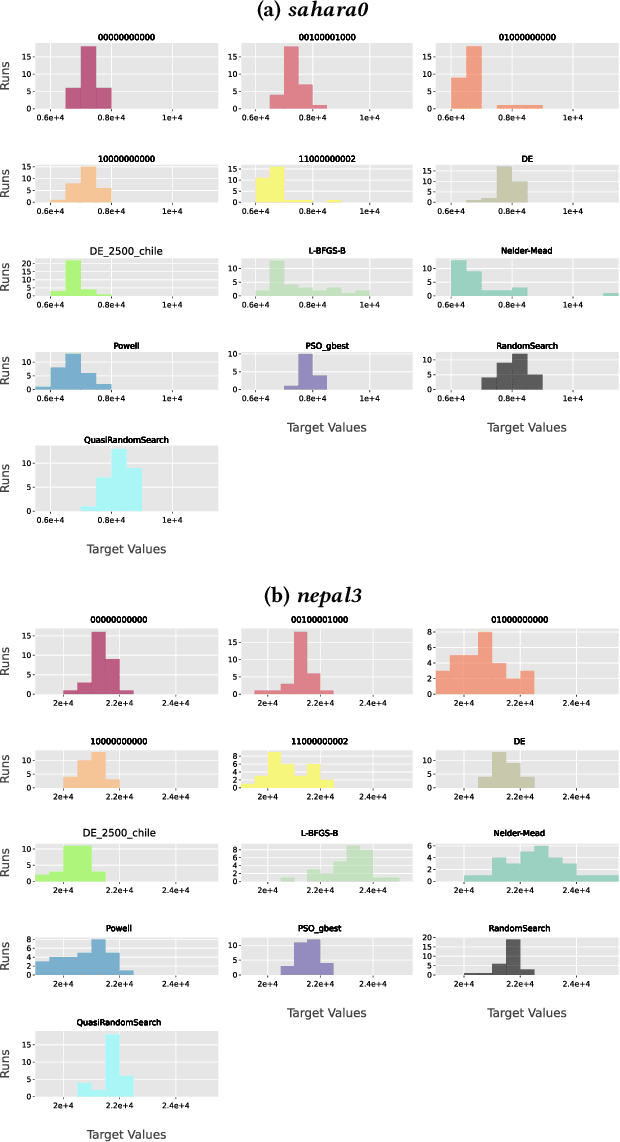

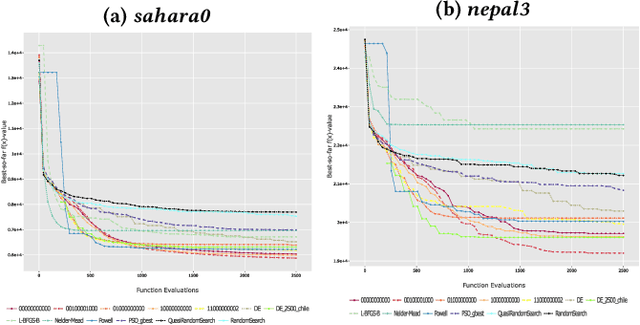
The configuration of radar networks is a complex problem that is often performed manually by experts with the help of a simulator. Different numbers and types of radars as well as different locations that the radars shall cover give rise to different instances of the radar configuration problem. The exact modeling of these instances is complex, as the quality of the configurations depends on a large number of parameters, on internal radar processing, and on the terrains on which the radars need to be placed. Classic optimization algorithms can therefore not be applied to this problem, and we rely on "trial-and-error" black-box approaches. In this paper, we study the performances of 13~black-box optimization algorithms on 153~radar network configuration problem instances. The algorithms perform considerably better than human experts. Their ranking, however, depends on the budget of configurations that can be evaluated and on the elevation profile of the location. We therefore also investigate automated algorithm selection approaches. Our results demonstrate that a pipeline that extracts instance features from the elevation of the terrain performs on par with the classical, far more expensive approach that extracts features from the objective function.
Towards Explainable Exploratory Landscape Analysis: Extreme Feature Selection for Classifying BBOB Functions
Feb 01, 2021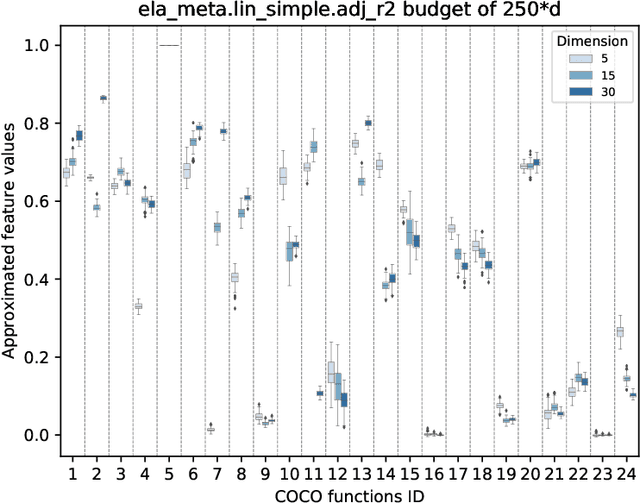
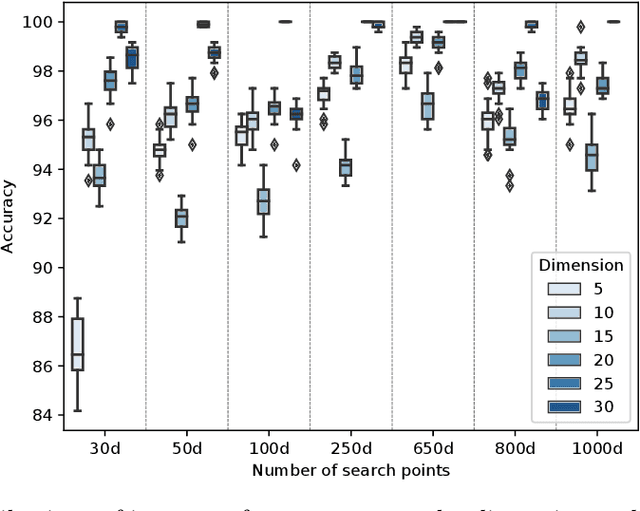
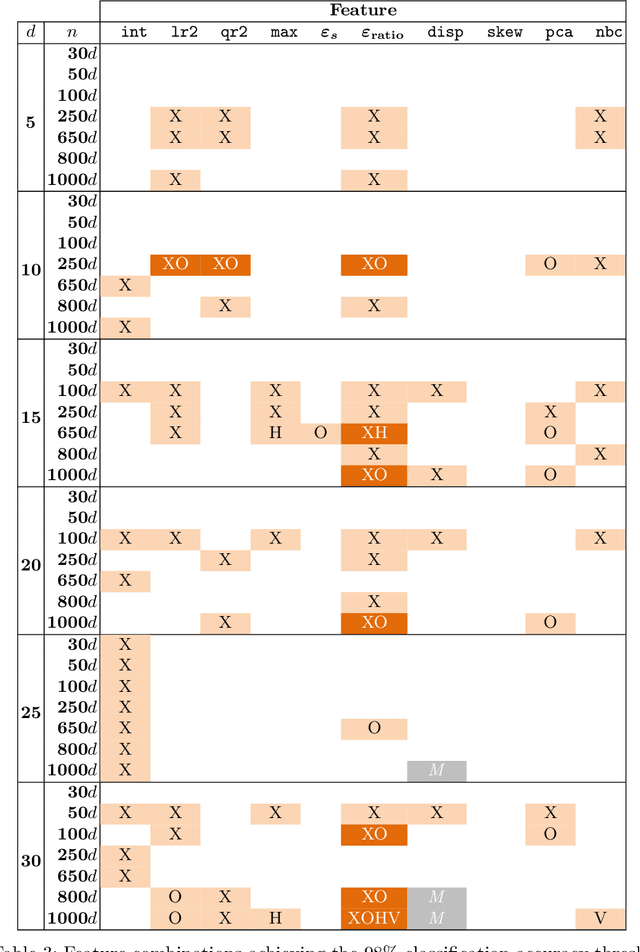
Facilitated by the recent advances of Machine Learning (ML), the automated design of optimization heuristics is currently shaking up evolutionary computation (EC). Where the design of hand-picked guidelines for choosing a most suitable heuristic has long dominated research activities in the field, automatically trained heuristics are now seen to outperform human-derived choices even for well-researched optimization tasks. ML-based EC is therefore not any more a futuristic vision, but has become an integral part of our community. A key criticism that ML-based heuristics are often faced with is their potential lack of explainability, which may hinder future developments. This applies in particular to supervised learning techniques which extrapolate algorithms' performance based on exploratory landscape analysis (ELA). In such applications, it is not uncommon to use dozens of problem features to build the models underlying the specific algorithm selection or configuration task. Our goal in this work is to analyze whether this many features are indeed needed. Using the classification of the BBOB test functions as testbed, we show that a surprisingly small number of features -- often less than four -- can suffice to achieve a 98\% accuracy. Interestingly, the number of features required to meet this threshold is found to decrease with the problem dimension. We show that the classification accuracy transfers to settings in which several instances are involved in training and testing. In the leave-one-instance-out setting, however, classification accuracy drops significantly, and the transformation-invariance of the features becomes a decisive success factor.